Apple's M1 Pro, M1 Max SoCs Investigated: New Performance and Efficiency Heights
by Andrei Frumusanu on October 25, 2021 9:00 AM EST- Posted in
- Laptops
- Apple
- MacBook
- Apple M1 Pro
- Apple M1 Max
Huge Memory Bandwidth, but not for every Block
One highly intriguing aspect of the M1 Max, maybe less so for the M1 Pro, is the massive memory bandwidth that is available for the SoC.
Apple was keen to market their 400GB/s figure during the launch, but this number is so wild and out there that there’s just a lot of questions left open as to how the chip is able to take advantage of this kind of bandwidth, so it’s one of the first things to investigate.
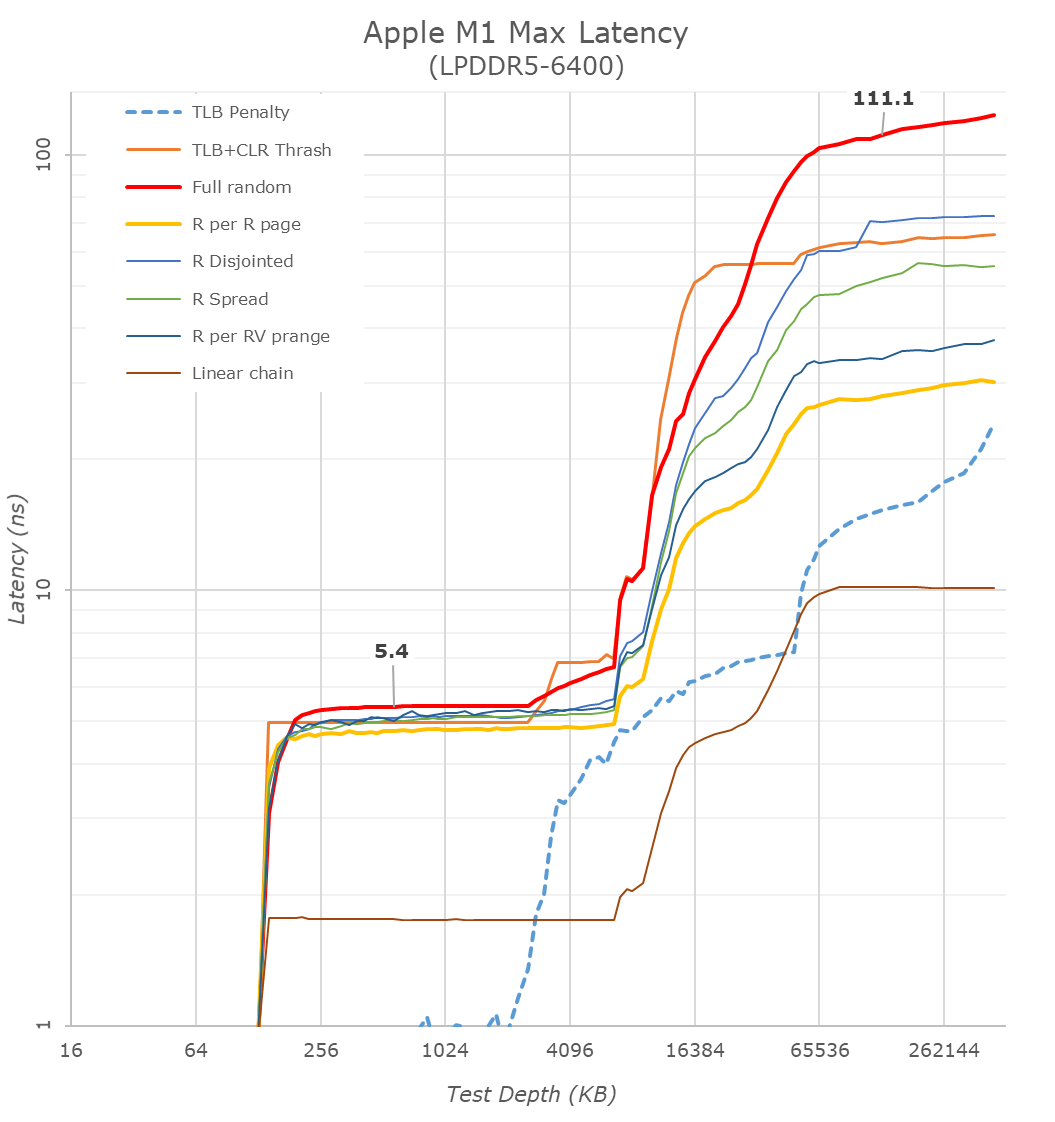
Starting off with our memory latency tests, the new M1 Max changes system memory behaviour quite significantly compared to what we’ve seen on the M1. On the core and L2 side of things, there haven’t been any changes and we consequently don’t see much alterations in terms of the results – it’s still a 3.2GHz peak core with 128KB of L1D at 3 cycles load-load latencies, and a 12MB L2 cache.
Where things are quite different is when we enter the system cache, instead of 8MB, on the M1 Max it’s now 48MB large, and also a lot more noticeable in the latency graph. While being much larger, it’s also evidently slower than the M1 SLC – the exact figures here depend on access pattern, but even the linear chain access shows that data has to travel a longer distance than the M1 and corresponding A-chips.
DRAM latency, even though on paper is faster for the M1 Max in terms of frequency on bandwidth, goes up this generation. At a 128MB comparable test depth, the new chip is roughly 15ns slower. The larger SLCs, more complex chip fabric, as well as possible worse timings on the part of the new LPDDR5 memory all could add to the regression we’re seeing here. In practical terms, because the SLC is so much bigger this generation, workloads latencies should still be lower for the M1 Max due to the higher cache hit rates, so performance shouldn’t regress.
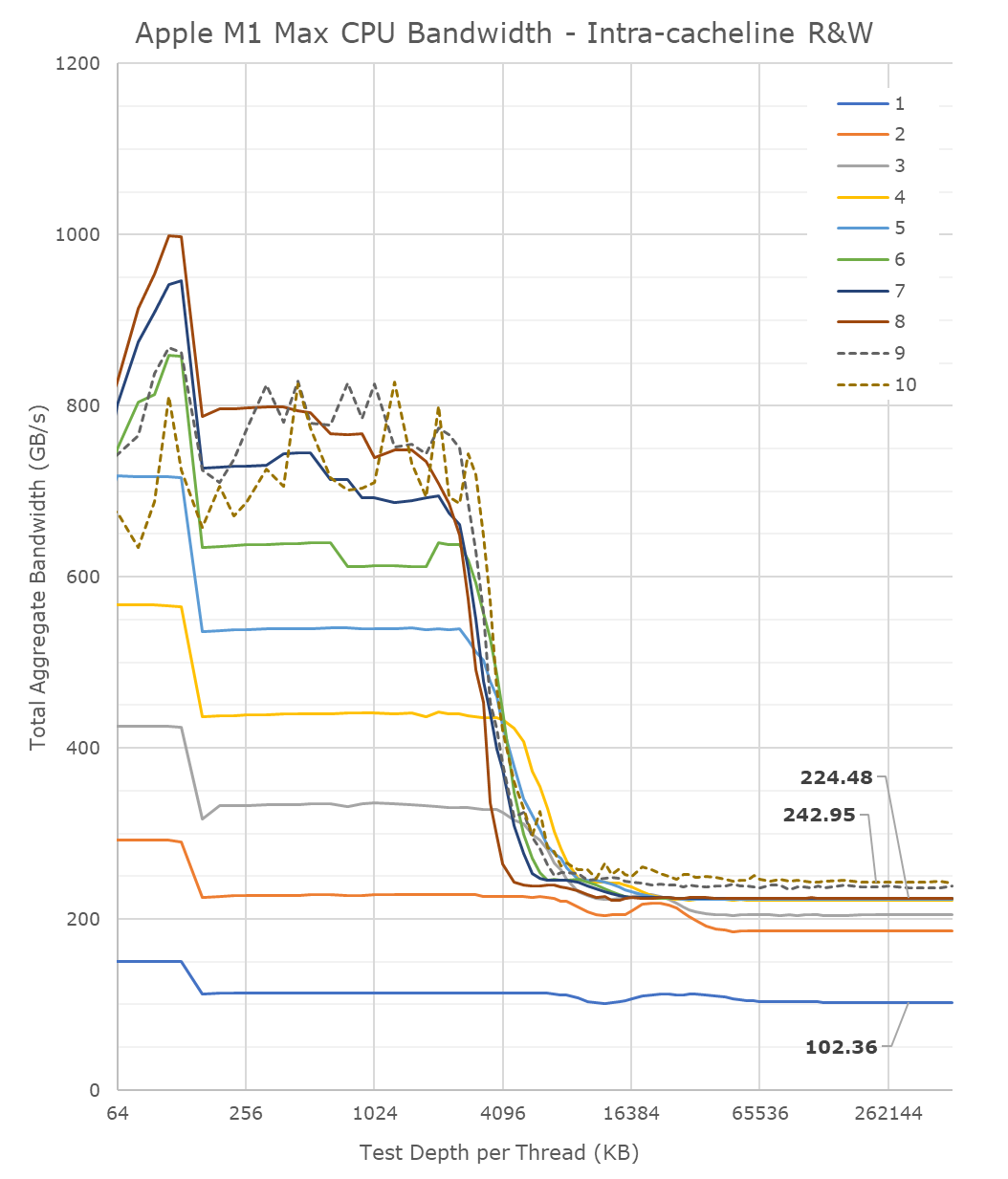
A lot of people in the HPC audience were extremely intrigued to see a chip with such massive bandwidth – not because they care about GPU or other offload engines of the SoC, but because the possibility of the CPUs being able to have access to such immense bandwidth, something that otherwise is only possible to achieve on larger server-class CPUs that cost a multitude of what the new MacBook Pros are sold at. It was also one of the first things I tested out – to see exactly just how much bandwidth the CPU cores have access to.
Unfortunately, the news here isn’t the best case-scenario that we hoped for, as the M1 Max isn’t able to fully saturate the SoC bandwidth from just the CPU side;
From a single core perspective, meaning from a single software thread, things are quite impressive for the chip, as it’s able to stress the memory fabric to up to 102GB/s. This is extremely impressive and outperforms any other design in the industry by multiple factors, we had already noted that the M1 chip was able to fully saturate its memory bandwidth with a single core and that the bottleneck had been on the DRAM itself. On the M1 Max, it seems that we’re hitting the limit of what a core can do – or more precisely, a limit to what the CPU cluster can do.
The little hump between 12MB and 64MB should be the SLC of 48MB in size, the reduction in BW at the 12MB figure signals that the core is somehow limited in bandwidth when evicting cache lines back to the upper memory system. Our test here consists of reading, modifying, and writing back cache lines, with a 1:1 R/W ratio.
Going from 1 core/threads to 2, what the system is actually doing is spreading the workload across the two performance clusters of the SoC, so both threads are on their own cluster and have full access to the 12MB of L2. The “hump” after 12MB reduces in size, ending earlier now at +24MB, which makes sense as the 48MB SLC is now shared amongst two cores. Bandwidth here increases to 186GB/s.
Adding a third thread there’s a bit of an imbalance across the clusters, DRAM bandwidth goes to 204GB/s, but a fourth thread lands us at 224GB/s and this appears to be the limit on the SoC fabric that the CPUs are able to achieve, as adding additional cores and threads beyond this point does not increase the bandwidth to DRAM at all. It’s only when the E-cores, which are in their own cluster, are added in, when the bandwidth is able to jump up again, to a maximum of 243GB/s.
While 243GB/s is massive, and overshadows any other design in the industry, it’s still quite far from the 409GB/s the chip is capable of. More importantly for the M1 Max, it’s only slightly higher than the 204GB/s limit of the M1 Pro, so from a CPU-only workload perspective, it doesn’t appear to make sense to get the Max if one is focused just on CPU bandwidth.
That begs the question, why does the M1 Max have such massive bandwidth? The GPU naturally comes to mind, however in my testing, I’ve had extreme trouble to find workloads that would stress the GPU sufficiently to take advantage of the available bandwidth. Granted, this is also an issue of lacking workloads, but for actual 3D rendering and benchmarks, I haven’t seen the GPU use more than 90GB/s (measured via system performance counters). While I’m sure there’s some productivity workload out there where the GPU is able to stretch its legs, we haven’t been able to identify them yet.
That leaves everything else which is on the SoC, media engine, NPU, and just workloads that would simply stress all parts of the chip at the same time. The new media engine on the M1 Pro and Max are now able to decode and encode ProRes RAW formats, the above clip is a 5K 12bit sample with a bitrate of 1.59Gbps, and the M1 Max is not only able to play it back in real-time, it’s able to do it at multiple times the speed, with seamless immediate seeking. Doing the same thing on my 5900X machine results in single-digit frames. The SoC DRAM bandwidth while seeking around was at around 40-50GB/s – I imagine that workloads that stress CPU, GPU, media engines all at the same time would be able to take advantage of the full system memory bandwidth, and allow the M1 Max to stretch its legs and differentiate itself more from the M1 Pro and other systems.








493 Comments
View All Comments
Ppietra - Tuesday, October 26, 2021 - link
anyone can compile SPEC and see the source codePpietra - Monday, October 25, 2021 - link
There aren’t that many games that are actually optimized for Apple’s hardware so you cannot actually extrapolate to other case scenarios, though we shouldn’t expect to be the best anyway. We should look for other kind of workloads to see out it behaves.SPEC uses a lot of different real world tasks.
FurryFireball - Wednesday, October 27, 2021 - link
World of Warcraft is optimized for the M1Ppietra - Wednesday, October 27, 2021 - link
true, but it isn’t one of the games that were tested.What I meant is that people seem to be drawing conclusions about hardware based on games that have almost no optimisation.
The Hardcard - Monday, October 25, 2021 - link
Please provide 1 example of the M1 falling behind on native code. As far as games, we’ll see if maybe one developer will dip a toe in with a native game. I wouldn’t buy one of these now if gaming was a prority.But note, these SPEC scores are unoptimized and independently compiled, so there are no benchmark tricks here. Imagine what the scores would be if time was taken to optimize to the architecture’s strengths.
name99 - Monday, October 25, 2021 - link
Oh the internet...- Idiot fringe A complaining that "SPEC results don't count because Apple didn't submit properly tuned and optimized results".
- Meanwhile, simultaneously, Idiot fringe B complaining that "Apple cheats on benchmarks because they once, 20 years ago, in fact tried to create tuned and optimized SPEC results".
sean8102 - Tuesday, October 26, 2021 - link
From what I can find Baldur's Gate 3 and WoW are the only 2 demanding games that are ARM native on macOS.https://www.applegamingwiki.com/wiki/M1_native_com...
michael2k - Monday, October 25, 2021 - link
From the article, yes, the benchmark does show the M1M beating the 3080 and Intel/AMD:On the GPU side, the GE76 Raider comes with a GTX 3080 mobile. On Aztec High, this uses a total of 200W power for 266fps, while the M1 Max beats it at 307fps with just 70W wall active power. The package powers for the MSI system are reported at 35+144W.
In the SPECfp suite, the M1 Max is in its own category of silicon with no comparison in the market. It completely demolishes any laptop contender, showcasing 2.2x performance of the second-best laptop chip. The M1 Max even manages to outperform the 16-core 5950X – a chip whose package power is at 142W, with rest of system even quite above that. It’s an absolutely absurd comparison and a situation we haven’t seen the likes of.
However, your assertion regarding applications seems completely opposite what the review found:
With that said, the GPU performance of the new chips relative to the best in the world of Windows is all over the place. GFXBench looks really good, as do the MacBooks’ performance productivity workloads. For the true professionals out there – the people using cameras that cost as much as a MacBook Pro and software packages that are only slightly cheaper – the M1 Pro and M1 Max should prove very welcome. There is a massive amount of pixel pushing power available in these SoCs, so long as you have the workload required to put it to good use.
taligentia - Monday, October 25, 2021 - link
Did you even read the article ?The "real world" 3080 scenarios were done using Rosetta emulated apps.
When you look at GPU intensive apps e.g. Davinci Resolve it is seeing staggering performance.
vlad42 - Monday, October 25, 2021 - link
Did you read the article? Andrei made sure the UHD benchmarks were GPU bound, not CPU bound (which would be the case if it were a Rosetta issue).