Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
Conclusion & First Impressions
Today’s Arm Client TechDay disclosures were generally quite a lot more extensive than in the last few years, especially given the number of new IP releases we’ve covered. Three new CPU microarchitectures, a new DSU/L3 cluster design, and two new SoC interconnect IPs is quite a bit more than we’re used to, and it goes to underscore just how much effort Arm is putting into updating all of the parts of its client IP.
Starting off with the CPUs, the new Cortex-X2 and Cortex-A710 cores are meant to be iterative designs compared to their predecessors, and that's certainly what they are from a performance and efficiency viewpoint. On a generational basis, Arm is promising a 10-16% improvement in IPC. However these figures are somewhat muddled by the fact we’re also comparing 4MB and 8MB L3 caches. Generally, it’s a reasonable expectation of what we’ll be seeing in 2022 devices, but it’s also hard to disambiguate and attribute the performance of the cores versus that of the new DSU-110 L3 cluster design.
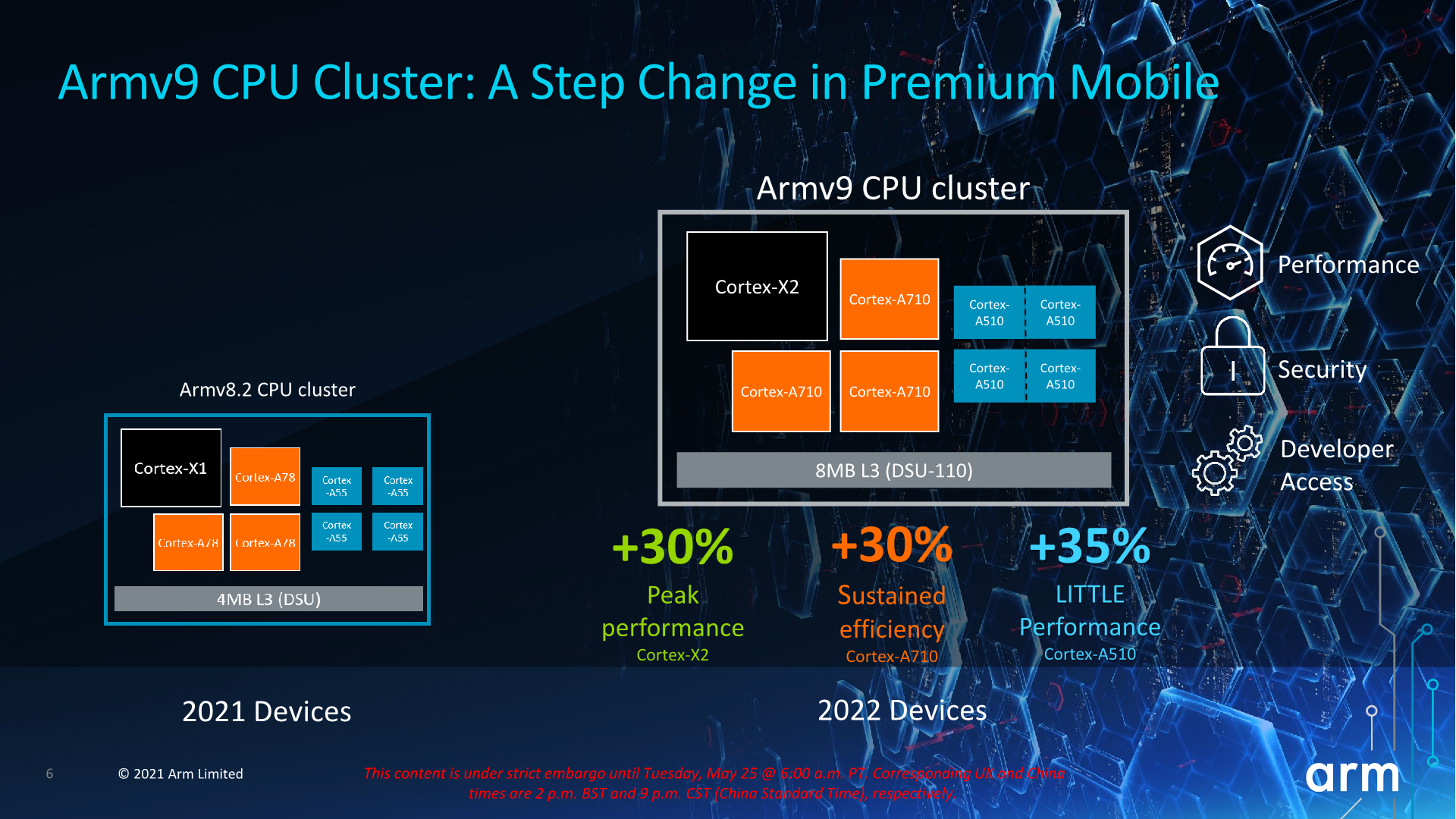
Arm has also made some more lofty performance claims when it comes to actual device implementations in 2022, such as +30% peak-to-peak performance boosts on the parts of the X2 cores. Generally, given our expectations that both the next Snapdragon and the next Exynos flagships will come in a similar Samsung foundry process node with smaller improvements, I’m very doubtful we’ll be seeing such larger generational improvements in practice, unless somehow MediaTek surprises us with a flagship X2 SoC made out at TSMC.
While the X2 and A710 aren’t all that groundbreaking, we have to note that the move towards Armv9 brings a lot of new architectural features that would otherwise eat into the expected yearly performance or efficiency improvements. The move to the new ISA baseline has been a long time coming and I’m curious to see what it will enable in terms of media applications (SVE) or AI (new ML instructions).
This is also the fourth and last iteration of Arm’s Austin core family, so hopefully next year’s new Sophia family will see larger generational leaps. Arm admits that we’re nearing diminishing returns and it’s certainly not at the same break-neck pace it was moving a few years ago, but there’s still a lot which can be done.
Today we also saw the unveiling of a brand-new little core in the form of the Cortex-A510. A new clean-sheet design from the Cambridge team, it’s certainly using an innovative approach given its “merged core” design, sharing the L2 cache hierarchy and the FP/SIMD back-end amongst two otherwise full featured cores. The performance and IPC gains are claimed to be quite large at +35-50%, however it seems that this generation hasn’t improved the efficiency curve all that much. It’s still a much better design and will have effective benefits for power efficiency in real-world workloads due to how workloads interact between the little and larger cores, but leaves us with a feeling that it doesn’t provide a knock-out convincing jump we had expected after 4 years. The silver lining here is that Arm is promising further generational improvements in performance and power with subsequent iterations, so we won’t be left with the current state of affairs the same way we saw the Cortex-A55 stagnate.

One of the more key points I saw Arm put their focus on was the new possibilities in larger form-factor devices beyond mobile. The new DSU-110 now supports up to 8 Cortex-X2 cores, a theoretical setup that would pretty much blow away the current Cortex-A76 based Arm laptop SoCs such as the Snapdragon 8cx family. The new cluster design allows for large L3 caches of up to 16MB, and while I don’t know if we’ll see the new interconnect IPs used by the larger vendors, it surely also makes a big argument for larger performance designs. The catch is that if Qualcomm were to adopt and make such a design, it would seemingly be short-lived given their recent Nuvia acquisition and intent on using custom cores. Otherwise, because of a lack of Mali Windows drivers, this really only leaves space for a theoretical Samsung laptop SoC with AMD RDNA GPU, but such a SoC could nonetheless be very successful.
Overall, this year’s CPU and system IP announcements from Arm are extremely solid new IP offerings, really laying down a new foundation, both architecturally with Armv9, and microarchitecturally thanks to elements such as the new DSU and the new little core CPUs. We’re looking forward to the new 2022 SoCs and products that will be powered by the new Arm IP.








181 Comments
View All Comments
WorBlux - Thursday, May 27, 2021 - link
These micro-ops are greatly exaggerated. For instance Gracemont CPU's don't have any. And 4 of the 5 decoders on intel are simple, meaning they only drop one micro-op per instruction.Having to deal with a variable length instruction is still a bitch on the front end.
mode_13h - Saturday, May 29, 2021 - link
> Gracemont CPU's don't have any.I think you meant to say they don't have micro-op *caches*.
Tomatotech - Tuesday, May 25, 2021 - link
They’re correct. x86 cores have been RISC internally since the Pentium era. They’re black boxes that take CISC instructions, then internally these instructions are converted to RISC for the microprocessors.See the Development section of this wiki article for the Pentium. Later chips expanded and further developed the internal RISC parts after the success of the Pentium. Sorry to shatter your illusions.
https://en.wikipedia.org/wiki/P5_(microarchitectur...
Wilco1 - Tuesday, May 25, 2021 - link
RISC/CISC is only ever about the ISA, never about implementation. Even the very first 8086 uses simpler micro-ops internally in its microcode, but that doesn't make it any more RISC than modern implementations.Another common misconception that changing the decoder is all that is required to change ISAs. This is also incorrect since the internals are very different between ISAs.
Thala - Tuesday, May 25, 2021 - link
Precisely. x86 will never escape from the problem:- having variable length instructions
- having less architectural registers
- having TSO memory model
And no internal RISC-like microarchitecture will help with above issues.
GeoffreyA - Wednesday, May 26, 2021 - link
"having variable length instructions"The main bottleneck of x86 and the part where ARM has the upper hand. Still, it's not impossible that some genius at AMD or Intel could crack the variable-length handicap once and for all. The micro-op cache did much. Something else is still missing.
mode_13h - Wednesday, May 26, 2021 - link
> Still, it's not impossible that some genius at AMD or> Intel could crack the variable-length handicap once and for all.
The only solution I see to that is basically letting the uop cache spill to RAM, so the decoder works more like a JIT translation engine.
And that only solves *one* of x86's key detriments.
GeoffreyA - Thursday, May 27, 2021 - link
That's a possibility but more work on the OS side. In that case, it might be better to switch to a new, fixed-length ISA altogether.If there were some way to index instruction start/end before reaching the decoder. Perhaps the compiler could help but that might break compatibility.
mode_13h - Saturday, May 29, 2021 - link
> That's a possibility but more work on the OS side.Yes. The era of "free" CPU performance improvements is coming to an end.
> In that case, it might be better to switch to a new, fixed-length ISA altogether.
Well, it's one thing Intel or AMD could do to eke a little more life out of x86-64. I think it's actually not a lot to ask from operating systems.
> If there were some way to index instruction start/end before reaching the decoder.
Perhaps the L1 instruction cache could do some preliminary analysis, during fills. They could add a couple extra bits per byte, to hold information subsequently useful to the decoder.
Or, maybe the decoder could just write back some info to help itself, if it needs to re-decode those same instructions after the corresponding micro-ops have been evicted from the micro-op cache.
GeoffreyA - Monday, May 31, 2021 - link
"Perhaps the L1 instruction cache could do some preliminary analysis"Interestingly, some CPUs did mark the instruction boundaries in the cache. Possibly the same principle. If I remember right, the Pentium MMX and some of the Atoms; and on AMD's side, K7 all the way to Bulldozer.