Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
The Cortex-A710: More Performance with More Efficiency
While the Cortex-X2 goes for all-out performance while paying the power and area penalties, Arm's Cortex-A710 design goes for a more efficient approach.
First of all, the new product nomenclature now is self-evident in regards to what Arm will be doing going forward- they’re skipping the A79 designation and simply starting fresh with a new three-digit scheme with the A710. Not very important in the grand scheme of things but an interesting marketing tidbit.

The Cortex-A710, much like the X2, is an Armv9 core with all new features that come with the new architecture version. Unlike the X2, the A710 also supports EL0 AArch32 execution, and as mentioned in the intro, this was mostly a design choice demanded by customers in the Chinese market where the ecosystem is still slightly lagging behind in moving all applications over to AArch64.

In terms of front-end enhancements, we’re seeing the same branch prediction improvements as on the X2, with larger structures as well as better accuracy. Other structures such as the L1I TLB have also seen an increase from 32 entries to 48 entries. Other front-end structures such as the macro-OP cache remain the same at 1.5K entries (The X2 also remains at 3K entries).

A very interesting choice for the A710 mid-core is that Arm has reduced the macro-OP cache and dispatch stage throughputs from 6-wide to 5-wide. This was mainly a targeted power and efficiency optimization for this generation, as we’re seeing a more important divergence between the Cortex-A and Cortex-X cores in terms of their specializations and targeted use-cases for performance and power.
The dispatch stage also features the same optimizations as on the X2, removing 1 cycle from the pipeline towards an overall 10-cycle pipeline design.
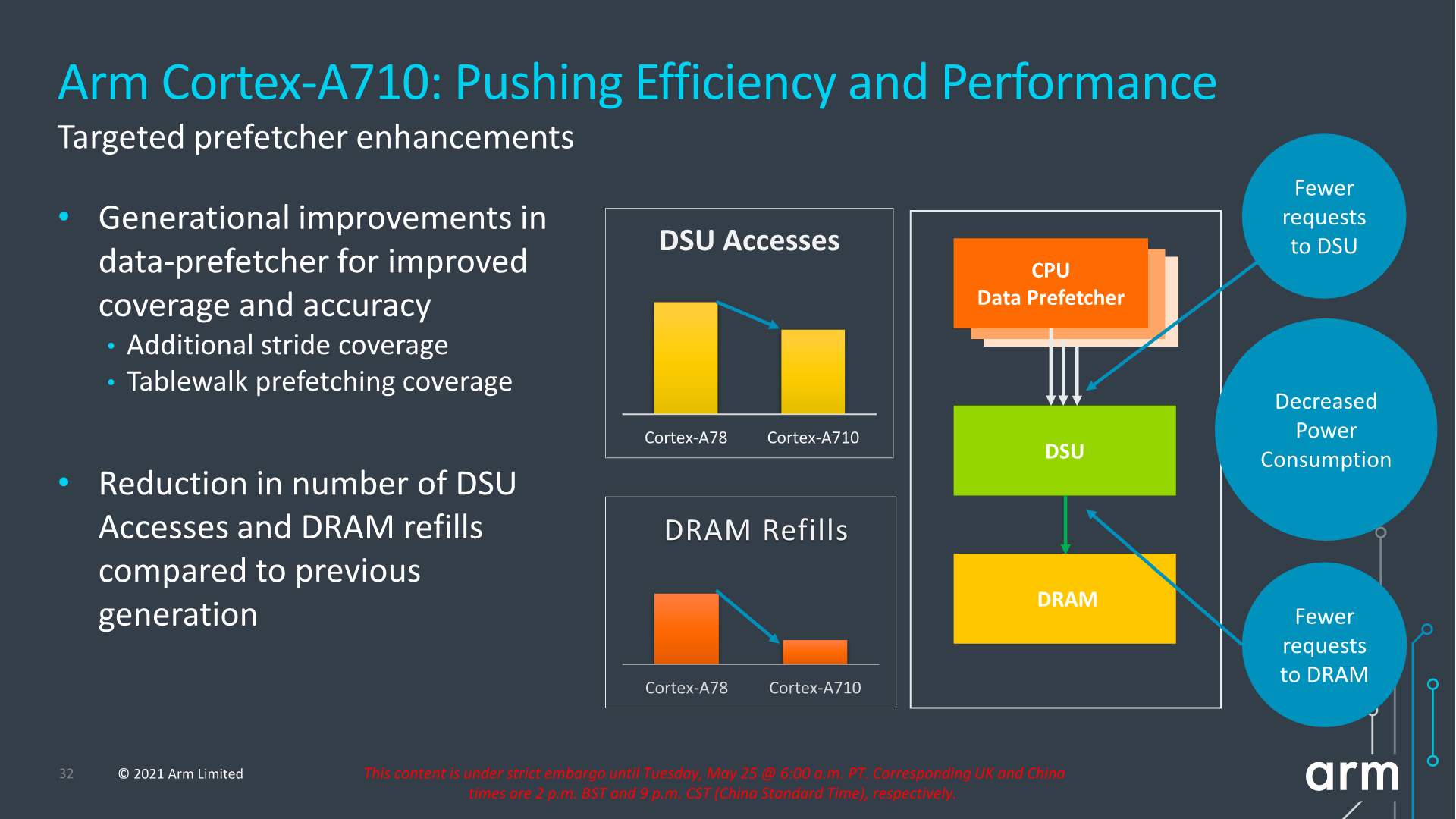
Arm also focuses on core improvements that affect the uncore parts of the system, which take place thanks to the new improvements in the prefetcher designs and how they interact with the new DSU-110 (which we’ll cover later). The new combination of core and DSU are able to reduce access from the core towards the L3 cache, as well as reducing the costly DRAM accesses thanks to the more efficiency prefetchers and larger L3 cache.
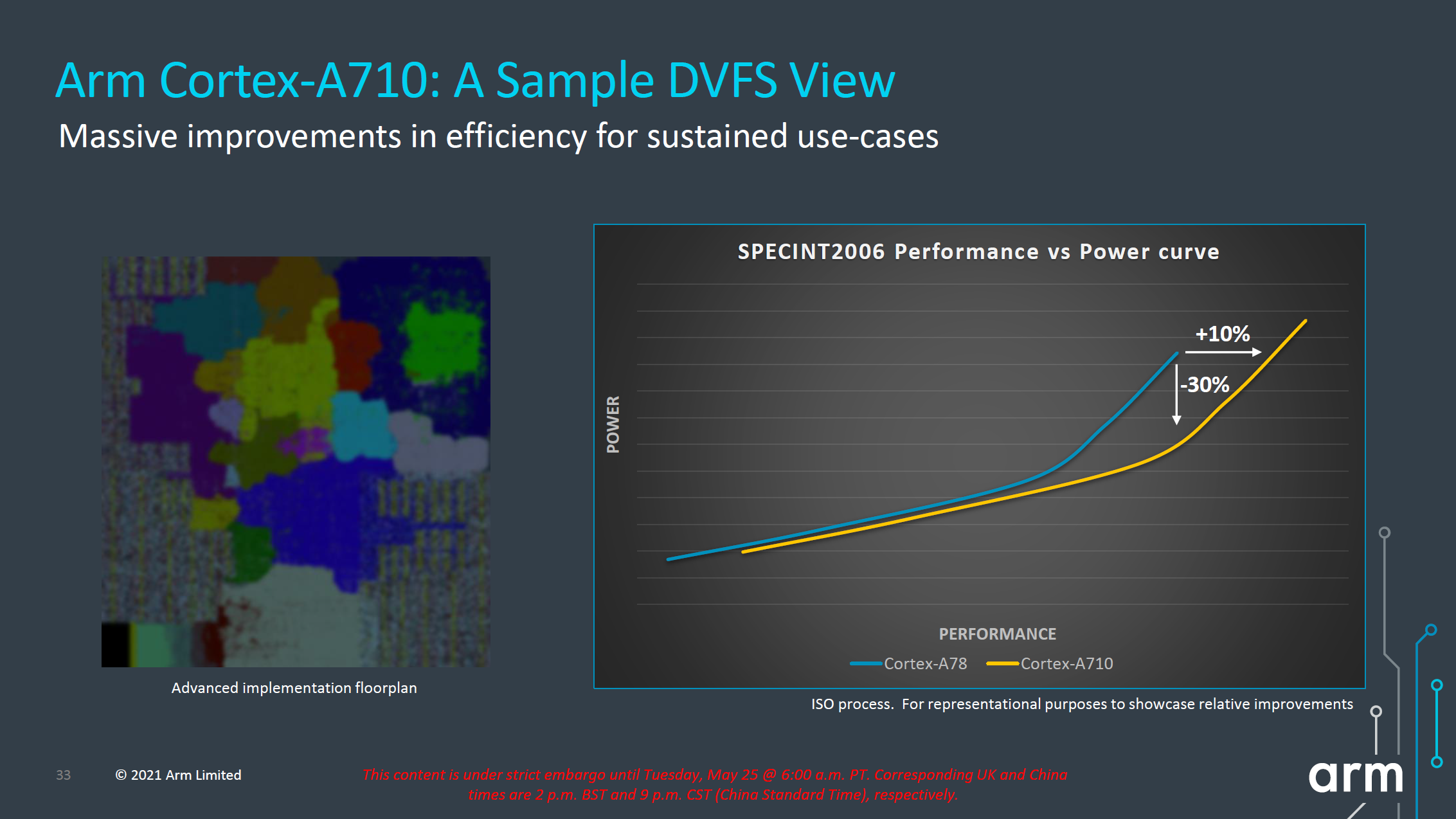
In terms of IPC, Arm advertises +10%, but again the issue with this figure here is that we’re comparing an 8MB L3 cache design to a 4MB L3 cache design. While this is a likely comparison for flagship SoCs next year, because the Cortex-A710 is also a core that would be used in mid-range or lower-end SoCs which might use much smaller L3 caches, it’s unlikely we’ll be seeing such IPC improvements in that sector unless the actual SoCs really do also improve their DSU sizes.
More important than the +10% improvement in performance is that, when backing off slightly in frequency, we can see that the power reduction can be rather large. According to Arm, at iso-performance the A710 consumes up to 30% less power than the Cortex-A78. This is something that would greatly help with sustained performance and power efficiency of more modestly clocked “middle” core implementations of the Cortex-A710.
In general, both the X2 and the A710’s performance and power figures are quite modest, making them the smallest generation-over-generation figures we’ve seen from Arm in quite a few years. Arm explains that due to this generation having made larger architectural changes with the move to Armv9, there has been an impact in regards to the usual efficiency and performance improvements that we’ve seen in prior generations.
Both the X2 and the A710 are also the fourth generation of this Austin microarchitecture family, so we’re hitting a wall of diminishing returns and maturity of the design. A few years ago we were under impression that the Austin family would only go on for three generations before handing things over to a new clean-sheet design from the Sophia team, but that original roadmap has been changed, and now we'll be seeing the new Sophia core with larger leaps in performance being disclosed next year.








181 Comments
View All Comments
ChrisGX - Monday, May 31, 2021 - link
There is one part of Andrei's analysis of the X2 core that I don't get. I do get the scepticism about ARM's optimistic estimate of a 30% lift in peak performance being on offer given the dismal underperformance of Samsung's 5nm silicon but my reading of what ARM has said is that the 16% performance gain for the X2 is ISO process, i.e. on the same silicon process at the same power and frequency. Am I wrong to read this as (effectively) an IPC gain without an energy cost associated with it? (Let us ignore for the moment such good news will likely be dashed due of Samsung's iffy silicon.) I know that sounds like a very rosy picture but isn't that the picture that ARM painted? In this context I don't get Andrei's suggestion of a lineal increase in power for that peak performance gain.Personally, I find the claim of a 16% performance gain hard to believe (and the 30% number after unspecified silicon process improvements and processor clock boost, presumably, even harder to believe). Still, I want to be clear on what ARM is claiming and what I have missed (if anything). Any comments would be welcome.
ChrisGX - Monday, May 31, 2021 - link
I have just reviewed Andrei's analysis again and I note he referred to a power increase (not a lineal power increase in proportion to the 16% performance increase) drawing particularly attention to the increased cache size.ChrisGX - Wednesday, June 2, 2021 - link
Regarding the projections of a 30% peak performance increase for a premium mobile SoC in 2022 I can't see how to get to that performance number (after a 16% IPC increase) without a) the prime X2 core being clocked at around 3.3GHz - 3.35GHz and b) corresponding silicon process improvements that permit lower voltages (at the increased core frequency). That implies a process that is better than TSMC's N5.For an 8 core X2 based SoC for consumer computers that performs at a peak rate of 1.4x the performance of a Core i5-1135G7 (which would represent a truly stunning level of performance) I think the SoC would have to be clocked at around 3.7GHz - 3.8GHz (again on a process that is markedly better than TSMC's N5). Performance like that, of course, won't come without elevating core and SoC power consumption to a significant degree.
Getting performance outcomes as good as that doesn't seem especially likely to me.
mode_13h - Wednesday, June 2, 2021 - link
Thanks for the analysis. If correct, this could mark the opening of a significant credibility gap, in ARM's projections.ChrisGX - Sunday, June 6, 2021 - link
I just had a look at the PPA Improvements that TSMC has advertised for its N4 process (there are unconfirmed claims that Qualcomm will be using N4 for the next premium SoC for flagship Android mobile phones) and I don't see ARM's projected performance numbers being reached on that process. N3 would do it but we won't see that before 2H2022. Without inviting thermal problems a performance improvement of 24% at 3.2GHz might fall within the bounds of possibility. (Note: Information on the N4 process is thin but I have assumed 7% more performance will be available at the same power compared to N5. With additional performance improvements of 16% from IPC gains - without pushing the power budget - a performance lift of 24% seems feasible.)https://www.anandtech.com/show/16639/tsmc-update-2...
rohn287 - Thursday, December 2, 2021 - link
Just asking, why not use 2-X2 cores with 2 higher clocked A710 and 2 normal A710. This will help reduce heat and increase performance in Android phones. Similar to Apples approach.The Futuristic - Saturday, April 2, 2022 - link
I know it's too late for comment, but the processors with this core have just entered the market. Depending on them and comparing them with Apple A15 E cores especially, I think they should start using cortex A710 as E cores instead of cortex A55. Apple E cores consumes around 0.44watt, cortex A78 in dimensity 1200 at 6nm uses 1.16W for same performance. So A710 is 30% efficient for same and taking it even further on 5nm. It will close the gap between Apple E cores and cortex cores. So 2x cortex X2 + 4x cortex A710 configured CPU, will catch Apple A15 in multi-core atleast.yeeeeman - Wednesday, May 11, 2022 - link
we're getting very close to the cortex x3 announcement.yeeeeman - Saturday, June 4, 2022 - link
seems like arm is missing the end of may announcements this year. anyone knows why?