Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
New DSU-110 L3 & Cluster: Massively More Bandwidth
Alongside the new CPU microarchitectures, Arm today is also announcing a new L3 design in the form of the new DSU-110. The “DynamIQ Shared Unit” had been the company’s go-to cluster and “core complex” block ever since it was introduced in 2017 with the Cortex-A75 and Cortex-A55. While we’ve seen small iterative improvements, today’s DSU-110 marks a major change in how the DSU operates and how it promises to scale up in cache size and bandwidth.

The new DSU-110 is a ground-up redesign with an emphasis on more bandwidth and more power efficiency. It continues to be the core building block for all of Arm’s mobile and lower tier market segments.
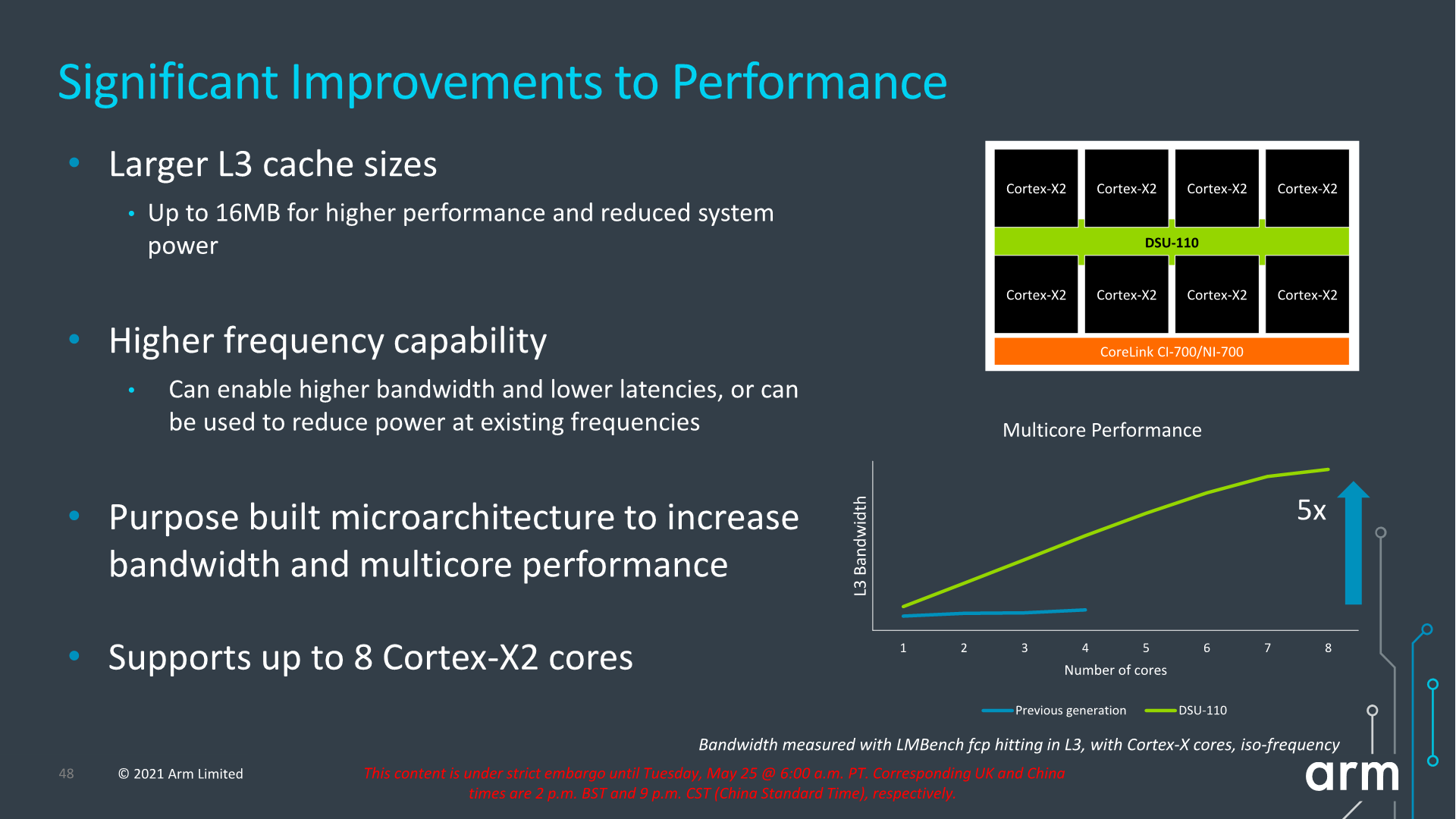
A key metric is of course the increase of L3 cache configuration which will now go up to 16MB this generation. This is of course the high-end of the spectrum and generally we shouldn’t expect such a configuration in a mobile SoC soon, but Arm has had several slides depicting larger form-factor implementations using such a larger design housing up to 8 Cortex-X2 cores. This is undoubtedly extremely interesting for a higher-performance laptop use-case.
The bandwidth increase of the new design is also significant, and applies from single-thread to multi-threaded scenarios. The new DSU-110 promises aggregate bandwidth increases of up to 5x compared to the contemporary design. More interesting is the fact that it also significantly boosts single-core bandwidth, and Arm here actually notes that the new DSU can actually support more bandwidth than what’s actually capable of the new core microarchitectures for the time being.

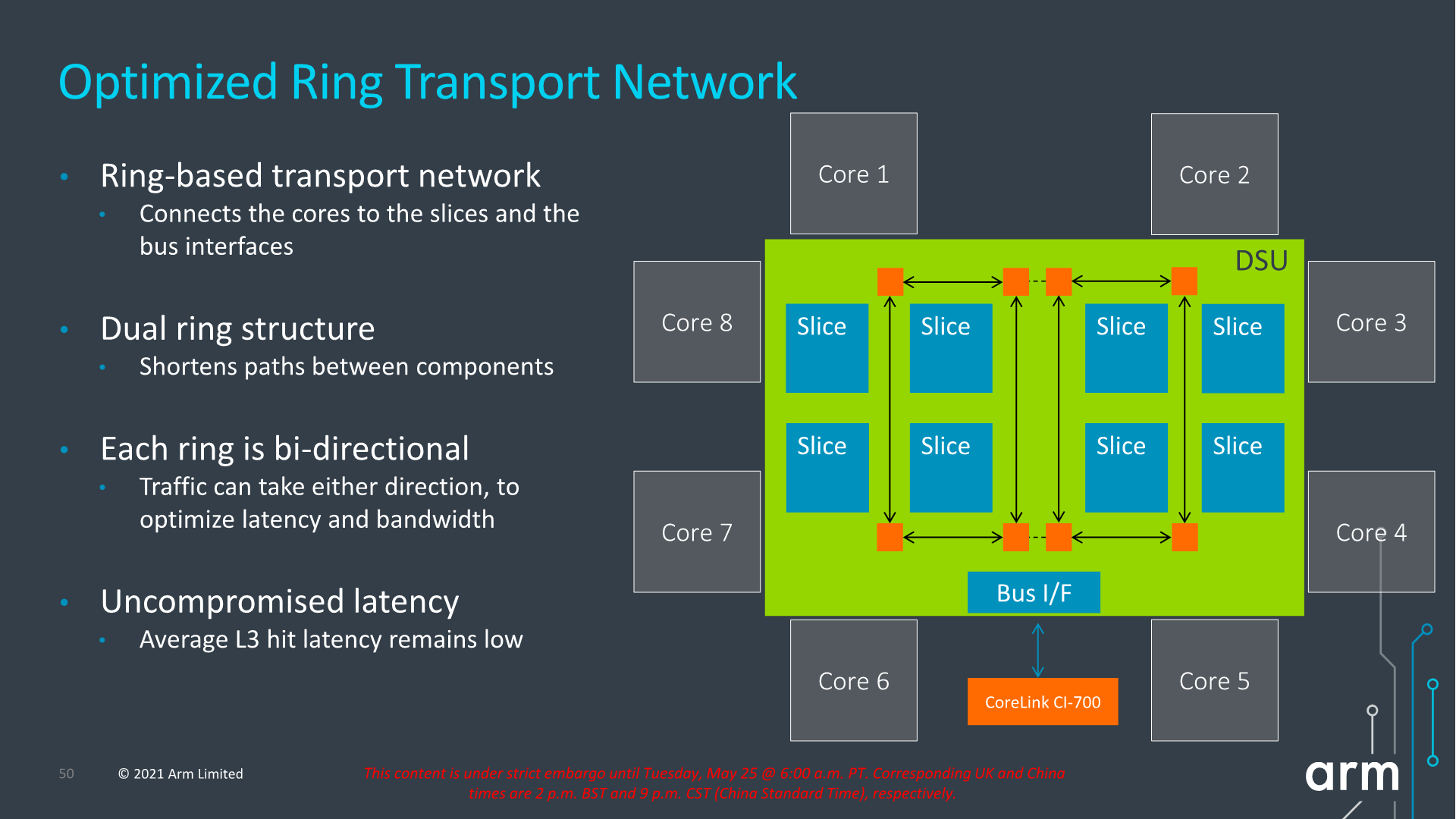
Arm never really disclosed the internal topology of the previous generation DSU, but remarks that with the DSU-110 the company has shifted over to a bi-directional dual-ring transport topology, each with four ring-stops, and now supporting up to 8 cache slices. The dual-ring structure is used to reduce the latencies and hops between ring-stops and in shorten the paths between the cache slices and cores. Arm notes that they’ve tried to retain the same lower access latencies as on the current generation DSU (cache size increases aside), so we should be seeing very similar average latencies between the two generations.
Parallel access increases for bandwidth as well as more outstanding transactions seem to have been also very important in order to improve performance, which seems very exciting for upcoming SoC designs, but also puts into more question the previously presented CPU IPC improvements and exactly how much the new DSU-110 contributes to those numbers.
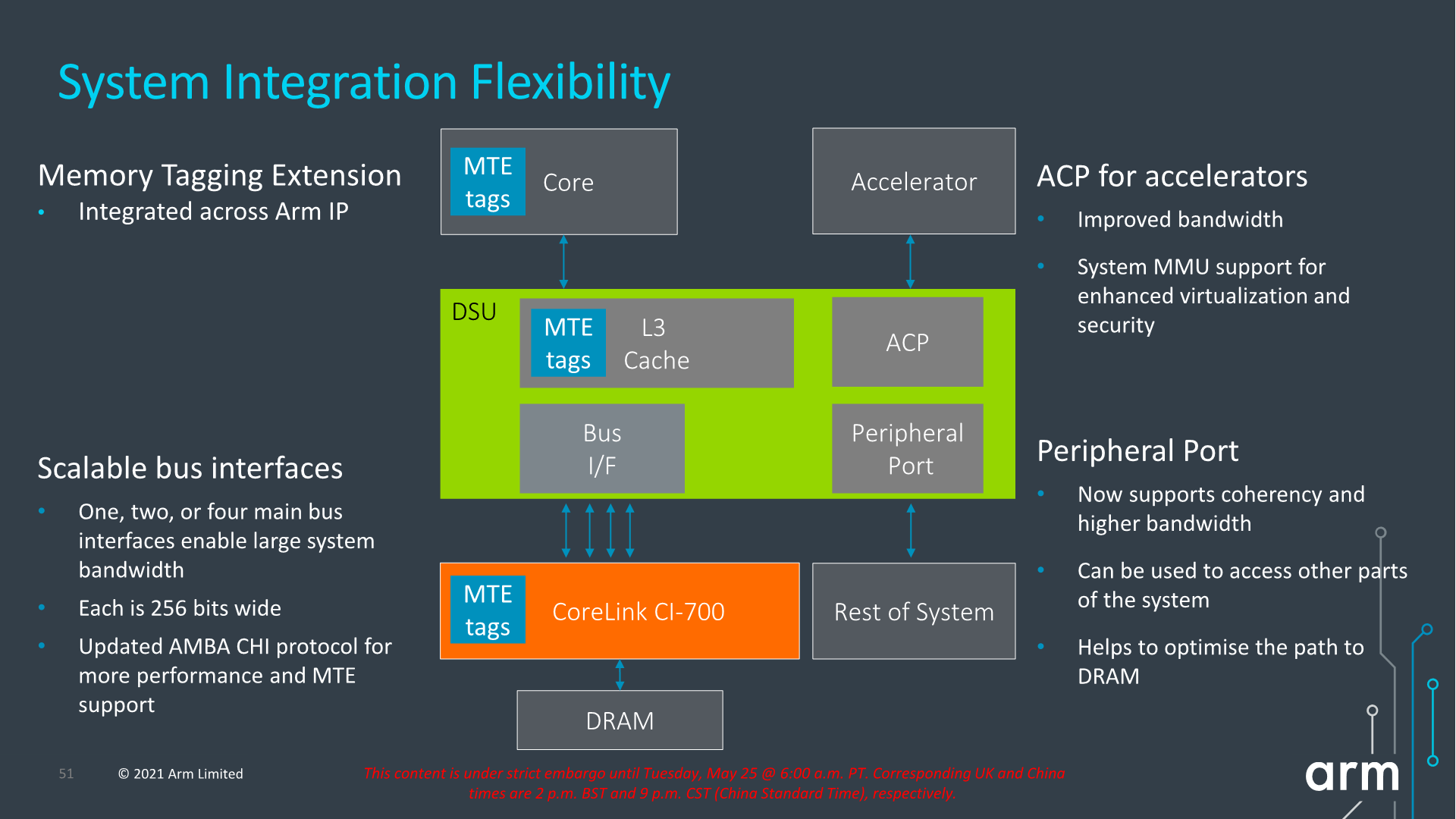
Architecturally, one important change to the capabilities of the DSU-110 is support for MTE tags, a upcoming security and debugging feature promising to greatly help with memory safety issues.
The new DSU can scale up to 4x AMBA CHI ports, meaning we’ll have up to 1024-bit total bi-directional bandwidth to the system memory. With a theoretical DSU clock of around 2GHz this would enable bandwidth of up to 256GB/s reads or writes, or double that when combined, plenty enough to be able to saturate also eventual high-end laptop configurations.

In terms of power efficiency, the new DSU offers more options for low-power operation when in idle situations, implementing partial L3 power-down, able to reduce leakage power of up to 75% compared to the current DSU.
In general idle situations but still having the full L3 powered on, the new design promises up to 25% reduction in leakage power all whilst offering 2x the bandwidth capabilities.
It’s important to note that we’re talking about leakage power here- active dynamic power is expected to generally scale linearly with the bandwidth increase of the new design, meaning 5x the bandwidth would also cost 5x the power. This would be an important factor to note into system power and in general the expected power behaviour of the next-gen SoCs when they’re put under heavy memory workloads.

Arm describes the DSU-110 as the backbone of the Armv9 cluster and that seemingly seems to be an apt description. The new bandwidth capabilities are sure to help out both with single-threaded, but also with multi-threaded performance of upcoming SoCs. Generally, the new 16MB L3 capability, while it’s possible somebody might do a high-end laptop SoC configuration, isn’t as exciting as the now finally expected move to a new 8MB L3 on mobile SoCs, hopefully also enabling higher power efficiency and more battery life for devices.








181 Comments
View All Comments
mode_13h - Wednesday, May 26, 2021 - link
> I do not know what else and why would anyone hate x86 processors from Intel and AMDLove & hate don't enter into it, for many of us. Based on our understanding of the tech, we recognize that x86 is fighting a losing battle. Apple is merely interesting as the foremost of x86' competitors.
> believe SPEC and Apple marketing PR.
There are plenty of Mac app benchmarks now, between x86 and ARM-based Macs. It's not just the SPEC scores and PR.
> People are using old school Xeon for home server
Sure. More power to them! The picture gets more complicated for laptops, though.
> to play damn latest games with community patches
You can only do that with some games, and eventually you have to start dialing back the quality settings, when you go back far enough.
For sure, x86 will be with us for at least another decade, in some fashion and degree. And the PC gamer will probably be one of the last holdouts.
> Why would anyone hate the only processing standard ...
Since you view this in terms of love/hate, why do you seem to hate ARM?
> Yep they are dumb and ignorant for sure.
Who said that? I think you're projecting.
mode_13h - Wednesday, May 26, 2021 - link
Do you understand thath GeoffreyA was being sarcastic? I think he was poking fun at the very pitched battle that you seem to be walking right into!Silver5urfer - Wednesday, May 26, 2021 - link
Another bs as usual, show me any AT Andrei bench here which shows how that garbage M1 scales in SMT, he never includes that CPU in SMT / HT benchmarks and only in ST it shows up showing some perf. And it's not even breaking any AMD or Intel CPU, with TGL Intel clearly demonstrated they are ready for AMD, forger Apple.64Core Mac Pros ? haha lmao you think logic and transistors simply can expand as long as Apple can buy shills out, you have look at the density of the chip and the uArch scaling PLUS power planes for such huge amount of cores AND the Power envelope.
M1 loses out AMD BGA processors and M1X, M2 do not exist today. We can also talk how AMD Genoa is going to increase cores to 80C and if you add SMT on that with on-die Chipset HBM TSMC 5N, it's a bloodbath for HEDT. Period. So Ryzen 5000 will smash the M1 to smithereens and blow it's ashes into air, wait for the Threadripper based on Milan to see even more catastrophic destruction of the M1, how are you even generalizing these high core count AMD and Intel CPUs on all computing devices, smells massive pile of dumbness.
I wonder what x86 did to you to hate it so much, it brought PC to masses, and it gave you the power of a computer from big rooms to your own room and now we have DIY with full socketed HW to use, ARM garbage has no consumer end ddevices which are popular enough. One can buy the Fujitsu A64FX but it;s super expensive, and Graviton 2 is AWS only, Ampere announced full custom, so expect not possible to buy anytime soon and their old 80C platform is now outdated, what is that ARM is giving and empowering you ? the iPad you used to type or the iPhone ? which have zero filesystem access or the M1 which has no user replaceable components.
mode_13h - Wednesday, May 26, 2021 - link
> I wonder what x86 did to you to hate it so muchTech is just a tool. I started out using MS DOS and then I moved on to Windows and Linux. I didn't hate DOS, but it had outlived its usefulness for me.
> ARM garbage has no consumer end ddevices which are popular enough.
Laptops, so far. Mini PCs are probably just around the corner. Mediatek is licensed Nvidia's GPU IP and has talked about building ARM-based gaming machines.
Intel and AMD could also get into the ARM race, and they could eventually make socketed processors. Certainly, any server processors will be socketed, but I mean for DIYers.
melgross - Thursday, May 27, 2021 - link
You have serious problems.mdriftmeyer - Friday, May 28, 2021 - link
Genoa is known already at 96 cores and patents have them up to 128 cores.The_Assimilator - Wednesday, May 26, 2021 - link
According to you ARM-bros, x86 has been dead every year for the past two decades. So excuse me if I don't put much stock in your particular brand of wankery - especially since Arm IPC improvements have hit a wall at the 3GHz mark.mode_13h - Wednesday, May 26, 2021 - link
> every year for the past two decadestwo decades ???
> Arm IPC improvements have hit a wall at the 3GHz mark.
Yeah, it's a fair point but also kind of irrelevant. Wider, shallower cores tend to clock lower. For mobile and servers, that works out better, since perf/W is a key metric for them. It's mostly just desktops and workstations where you have the luxury of clocking as high as you want. Even HPC is really starting to focus on energy-efficiency.
As for the relevance of IPC and clocks, what really counts is single- and multi- thread performance. The user just cares how fast it goes and potentially how much power it burns or heat it churns out.
GeoffreyA - Thursday, May 27, 2021 - link
It's interesting to see whether Intel and AMD will ever dial back the clocks in their quest for wider, weightier cores.mode_13h - Saturday, May 29, 2021 - link
Well, AMD's Zen cores have never clocked as high as Intel's, but Zen2 and Zen3 have been enjoying more perf/W and are also wider than Intel's. For Intel's part, they added more width in Sunny Cove.Increasing clock speed is a fairly reliable, straight forward way to raise performance over a wide variety of workloads. It's just not great in perf/W.
And to the extent that narrower cores use less silicon, that make them cheaper to produce.