Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
Conclusion & First Impressions
Today’s Arm Client TechDay disclosures were generally quite a lot more extensive than in the last few years, especially given the number of new IP releases we’ve covered. Three new CPU microarchitectures, a new DSU/L3 cluster design, and two new SoC interconnect IPs is quite a bit more than we’re used to, and it goes to underscore just how much effort Arm is putting into updating all of the parts of its client IP.
Starting off with the CPUs, the new Cortex-X2 and Cortex-A710 cores are meant to be iterative designs compared to their predecessors, and that's certainly what they are from a performance and efficiency viewpoint. On a generational basis, Arm is promising a 10-16% improvement in IPC. However these figures are somewhat muddled by the fact we’re also comparing 4MB and 8MB L3 caches. Generally, it’s a reasonable expectation of what we’ll be seeing in 2022 devices, but it’s also hard to disambiguate and attribute the performance of the cores versus that of the new DSU-110 L3 cluster design.
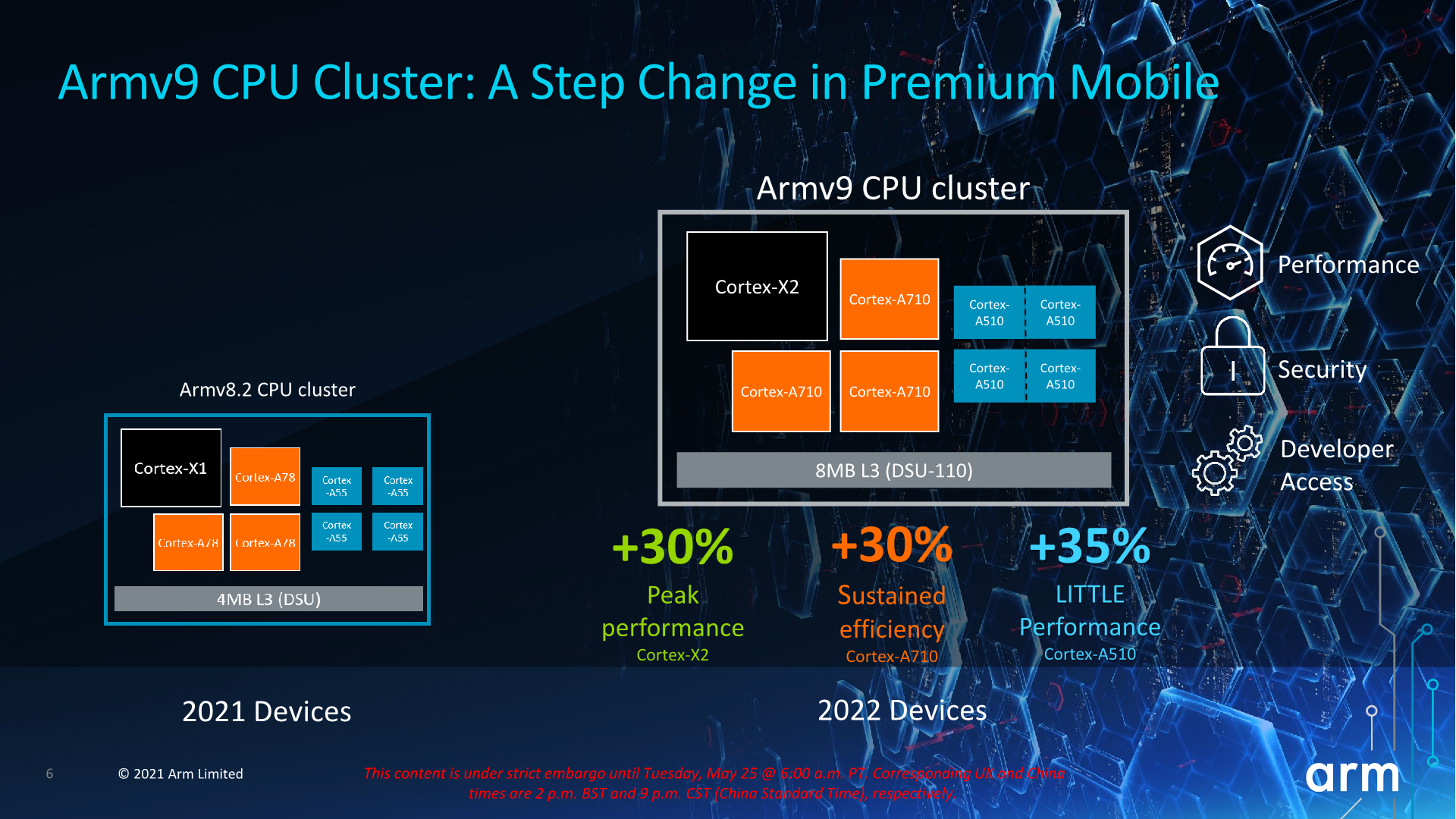
Arm has also made some more lofty performance claims when it comes to actual device implementations in 2022, such as +30% peak-to-peak performance boosts on the parts of the X2 cores. Generally, given our expectations that both the next Snapdragon and the next Exynos flagships will come in a similar Samsung foundry process node with smaller improvements, I’m very doubtful we’ll be seeing such larger generational improvements in practice, unless somehow MediaTek surprises us with a flagship X2 SoC made out at TSMC.
While the X2 and A710 aren’t all that groundbreaking, we have to note that the move towards Armv9 brings a lot of new architectural features that would otherwise eat into the expected yearly performance or efficiency improvements. The move to the new ISA baseline has been a long time coming and I’m curious to see what it will enable in terms of media applications (SVE) or AI (new ML instructions).
This is also the fourth and last iteration of Arm’s Austin core family, so hopefully next year’s new Sophia family will see larger generational leaps. Arm admits that we’re nearing diminishing returns and it’s certainly not at the same break-neck pace it was moving a few years ago, but there’s still a lot which can be done.
Today we also saw the unveiling of a brand-new little core in the form of the Cortex-A510. A new clean-sheet design from the Cambridge team, it’s certainly using an innovative approach given its “merged core” design, sharing the L2 cache hierarchy and the FP/SIMD back-end amongst two otherwise full featured cores. The performance and IPC gains are claimed to be quite large at +35-50%, however it seems that this generation hasn’t improved the efficiency curve all that much. It’s still a much better design and will have effective benefits for power efficiency in real-world workloads due to how workloads interact between the little and larger cores, but leaves us with a feeling that it doesn’t provide a knock-out convincing jump we had expected after 4 years. The silver lining here is that Arm is promising further generational improvements in performance and power with subsequent iterations, so we won’t be left with the current state of affairs the same way we saw the Cortex-A55 stagnate.

One of the more key points I saw Arm put their focus on was the new possibilities in larger form-factor devices beyond mobile. The new DSU-110 now supports up to 8 Cortex-X2 cores, a theoretical setup that would pretty much blow away the current Cortex-A76 based Arm laptop SoCs such as the Snapdragon 8cx family. The new cluster design allows for large L3 caches of up to 16MB, and while I don’t know if we’ll see the new interconnect IPs used by the larger vendors, it surely also makes a big argument for larger performance designs. The catch is that if Qualcomm were to adopt and make such a design, it would seemingly be short-lived given their recent Nuvia acquisition and intent on using custom cores. Otherwise, because of a lack of Mali Windows drivers, this really only leaves space for a theoretical Samsung laptop SoC with AMD RDNA GPU, but such a SoC could nonetheless be very successful.
Overall, this year’s CPU and system IP announcements from Arm are extremely solid new IP offerings, really laying down a new foundation, both architecturally with Armv9, and microarchitecturally thanks to elements such as the new DSU and the new little core CPUs. We’re looking forward to the new 2022 SoCs and products that will be powered by the new Arm IP.








181 Comments
View All Comments
mode_13h - Tuesday, June 1, 2021 - link
> some CPUs did mark the instruction boundaries in the cache.Not surprising, other than how far back you say it went.
mode_13h - Wednesday, May 26, 2021 - link
All good points. People who think "ISA doesn't matter" don't really understand everything an ISA encompasses.GeoffreyA - Wednesday, May 26, 2021 - link
The difference that divides them is that CISC can include a memory operation as part of an arithmetic one, whereas in RISC the two are separate (at least, in a load-store architecture).mode_13h - Wednesday, May 26, 2021 - link
> The difference that divides them is that CISC can include a memory operationI'm not an expert on the subject, but there are other elements in RISC orthodoxy, concerning things like:
* number of operands (also number of src & dst operands)
* encoding of immediates
* side-effects
I view the whole subject of CISC vs. RISC as something like MMA (Mixed Martial Arts). It turns out that there's no single best classical martial arts style. The most effective fighters use a blend of techniques adopted from various, disparate fighting styles.
GeoffreyA - Thursday, May 27, 2021 - link
"The most effective fighters use a blend of techniques"Absolutely. It's almost a universal principle that the winning design puts together the best elements from competing designs and throws away the junk.
Thala - Tuesday, May 25, 2021 - link
It does not matter that they are RISC-like inside, the issue with x86 is that they still carry the typical CISC baggage - and no internal RISC-like structure will help them here.km1810vm4 - Wednesday, May 26, 2021 - link
I would say x86 baggage. There were much nicer CISC architectures around at the time, like the Motorola 68000.TheinsanegamerN - Wednesday, May 26, 2021 - link
Intel's p5 processors implemented RISC style micro ops into their x86 decoding, that's part of why they were so dramatically faster then 486. It's not like this is hard to find out....mode_13h - Thursday, May 27, 2021 - link
> Intel's p5 processors implemented RISC style micro ops into their x86 decodingIn fact, early CPUs used a lot of microcode, and one of the ways they got faster was by replacing microcoded operations with hardwired logic. This was enabled by ever-increasing transistor budgets.
> that's part of why they were so dramatically faster then 486.
This feels like a bit of revisionist history. Here are some of the reasons why Pentium was faster than 80486:
https://en.wikipedia.org/wiki/P5_(microarchitectur...
Kamen Rider Blade - Tuesday, May 25, 2021 - link
Android needs to get their developers to stop using Java and use C/C++/Rust for their apps to eek out the max performance possible.Apple's App code base is generally C/C++, that's why they have the performance that they have.
And it's a long time nagging issue that I wish the Android community would solve.
It would give Android a HUGE performance boost to move their Apps over to C/C++/Rust.
Programming Languages have already been benchmarked against each other to see which one's faster and sorry to say it, but the C/C++/Rust family win the day in terms of Code Speed while using the same hardware platform.
https://benchmarksgame-team.pages.debian.net/bench...