Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
Conclusion & End Remarks
Today’s launch of the new 3rd gen Xeon Scalable processors is a major step forward for Intel and the company’s roadmap. Ice Lake SP had been baking in the oven for a very long time: originally planned for a 2020 release, Intel had only started production recently this January, so finally seeing the chips in silicon and in hand has been a relief.
Generationally Impressive
Technically, Ice Lake SP is an impressive and major generation leap for Intel’s enterprise line-up. Manufactured on a new 10nm process, node, employing a new core microarchitecture, faster memory with more memory channels, PCIe 4.0, new accelerator capabilities and VNNI instructions, security improvements – these are all just the tip of the iceberg that Ice Lake SP brings to the table.
In terms of generational performance uplifts, we saw some major progress today with the new Xeon 8380. With 40 cores at a higher TDP of 270W, the new flagship chip is a veritable beast with large increases in performance in almost all workloads. Major architectural improvements such as the new memory bandwidth optimisations are amongst what I found to be most impressive for the new parts, showcasing that Intel still has a few tricks up its sleeve in terms of design.
This being the first super-large 10nm chip design from Intel, the question of how efficiency would end up was a big question to the whole puzzle to the new generation line-up. On the Xeon 8380, a 40-core part at 270W, we saw a +18% increase in performance / W compared to the 28-core 205W Xeon 8280. This grew to a +36% perf/W advantage when limiting the ICX part to 205 as well. On the other hand, our mid-stack Xeon 6330 sample showed very little advantages to the Xeon 8280, even both are 28-core 205W designs. Due to the mix of good and bad results here, it seems we’ll have to delay a definitive verdict on the process node improvements to the future until we can get more SKUs, as the current variations are quite large.
Per-core performance, as well as single-thread performance of the new parts don’t quite achieve what I imagine Intel would have hoped through just the IPC gains of the design. The IPC gains are there and they’re notable, however the new parts also lose out on frequency, meaning the actual performance doesn’t move too much, although we did see smaller increases. Interestingly enough, this is roughly the same conclusion we came to when we tested Intel's Ice Lake notebook platform back in August 2019.

The Competitive Hurdle Still Stands
As impressive as the new Xeon 8380 is from a generational and technical stand-point, what really matters at the end of the day is how it fares up to the competition. I’ll be blunt here; nobody really expected the new ICL-SP parts to beat AMD or the new Arm competition – and it didn’t. The competitive gap had been so gigantic, with silly scenarios such as where competing 1-socket systems would outperform Intel’s 2-socket solutions. Ice Lake SP gets rid of those more embarrassing situations, and narrows the performance gap significantly, however the gap still remains, and is still undeniable.
We’ve only had access limited to the flagship Xeon 8380 and the mid-stack Xeon 6330 for the review today, however in a competitive landscape, both those chips lose out in both absolute performance as well as price/performance compared to AMD’s line-up.
Intel had been pushing very hard the software optimisation side of things, trying to differentiate themselves as well as novel technologies such as PMem (Optane DC persistent memory, essentially Optane memory modules), which unfortunately didn’t have enough time to cover for this piece. Indeed, we saw a larger focus on “whole system solutions” which take advantage of Intel’s broader product portfolio strengths in the enterprise market. The push for the new accelerator technologies means Intel needs to be working closely with partners and optimising public codebases to take advantage of these non-standard solutions, which might be a hurdle for deployments such as cloud services where interoperability might be important. While the theoretical gains can be large, anyone rolling a custom local software stack might see a limited benefit however, unless they are already experts with Intel's accelerator portfolio.
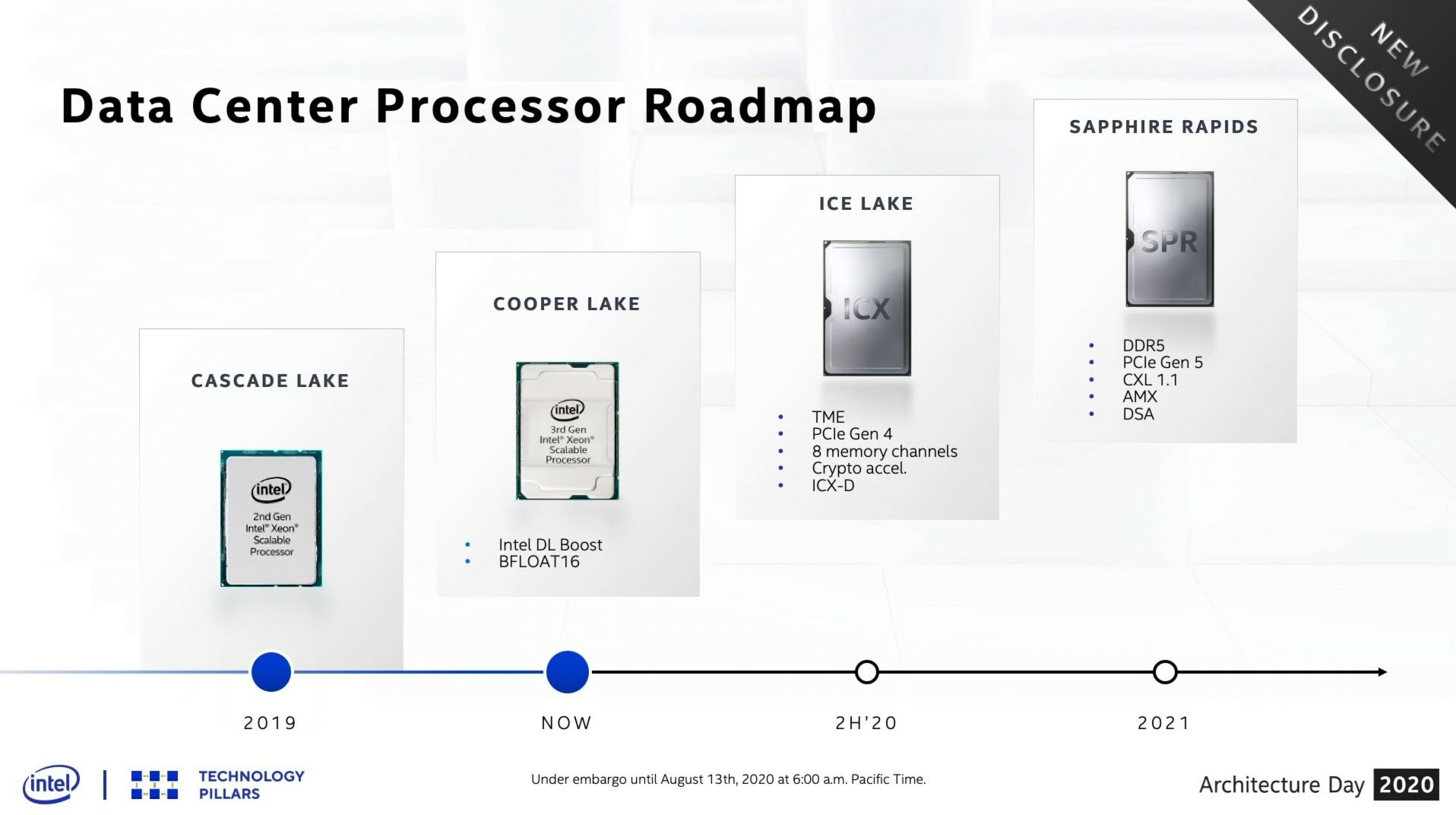
There’s also the looming Intel roadmap. While we are exulted to finally see Ice lake SP reach the market, Intel is promising the upcoming Sapphire Rapids chips for later this year, on a new platform with DDR5 and PCIe 5. Intel is set to have Ice Lake Xeon and Sapphire Rapids Xeon in the market concurrently, with the idea to manage both, especially for customers that apply the leading edge hardware as soon as it is available. It will be interesting to see the scale of the roll out of Ice Lake with this in mind.
At the end of the day, Ice Lake SP is a success. Performance is up, and performance per watt is up. I'm sure if we were able to test Intel's acceleration enhancements more thoroughly, we would be able to corroborate some of the results and hype that Intel wants to generate around its product. But even as a success, it’s not a traditional competitive success. The generational improvements are there and they are large, and as long as Intel is the market share leader, this should translate into upgraded systems and deployments throughout the enterprise industry. Intel is still in a tough competitive situation overall with the high quality the rest of the market is enabling.








169 Comments
View All Comments
Drazick - Wednesday, April 7, 2021 - link
The ICC compiler has much better vectorization engine than the one in GCC. It will usually generate better vectorized code. Especially numerical code.But the real benefit of ICC is its companion libraries: VSML, MKL, IPP.
Oxford Guy - Wednesday, April 7, 2021 - link
I remember that custom builds of Blender done with ICC scored better on Piledriver as well as on Intel hardware. So, even an architecture that was very different was faster with ICC.mode_13h - Thursday, April 8, 2021 - link
And when was this? Like 10 years ago? How do we know the point is still relevant?Oxford Guy - Sunday, April 11, 2021 - link
How do we know it isn't?Instead of whinge why not investigate the issue if you're actually interested?
Bottom line is that, just before the time of Zen's release, I tested three builds of Blender done with ICC and all were faster on both Intel and Piledriver (a very different architecture from Haswell).
I asked why the Blender team wasn't releasing its builds with ICC since performance was being left on the table but only heard vague suggestions about code stability.
Wilco1 - Sunday, April 11, 2021 - link
This thread has a similar comment about quality and support in ICC: https://twitter.com/andreif7/status/13808945639975...KurtL - Wednesday, April 7, 2021 - link
This is absolutely untrue. There is not much special about AOCC, it is just a AMD-packaged Clang/LLVM with few extras so it is not a SPEC compiler at all. Neither is it true for Intel. Sites that are concerned about getting the most performance out of their investments often use the Intel compilers. It is a very good compiler for any code with good potential for vectorization, and I have seen it do miracles on badly written code that no version of GCC could do.Wilco1 - Wednesday, April 7, 2021 - link
And those closed-source "extras" in AOCC magically improve the SPEC score compared to standard LLVM. How is it not a SPEC compiler just like ICC has been for decades?JoeDuarte - Wednesday, April 7, 2021 - link
It's strange to tell people who use the Intel compiler that it's not used much in the real world, as though that carries some substantive point.The Intel compiler has always been better than gcc in terms of the performance of compiled code. You asserted that that is no longer true, but I'm not clear on what evidence you're basing that on. ICC is moving to clang and LLVM, so we'll see what happens there. clang and gcc appear to be a wash at this point.
It's true that lots of open source Linux-world projects use gcc, but I wouldn't know the percentage. Those projects tend to be lazy or untrained when it comes to optimization. They hardly use any compiler flags relevant to performance, like those stipulating modern CPU baselines, or link time optimization / whole program optimization. Nor do they exploit SIMD and vectorization much, or PGO, or parallelization. So they leave a lot of performance on the table. More rigorous environments like HPC or just performance-aware teams are more likely to use ICC or at least lots of good flags and testing.
And yes, I would definitely support using optimized assembly in benchmarks, especially if it surfaced significant differences in CPU performance. And probably, if the workload was realistic or broadly applicable. Anything that's going to execute thousands, millions, or billions of times is worth optimizing. Inner loops are a common focus, so I don't know what you're objecting to there. Benchmarks should be about realizable optimal performance, and optimization in general should be a much bigger priority for serious software developers – today's software and OSes are absurdly slow, and in many cases desktop applications are slower in user-time than their late 1980s counterparts. Servers are also far too slow to do simple things like parse an HTTP request header.
pSupaNova - Wednesday, April 7, 2021 - link
"today's software and OSes are absurdly slow, and in many cases desktop applications are slower in user-time than their late 1980s counterparts." a late 1980's desktop could not even play a video let alone edit one, your average mid range smartphone is much more capable. My four year old can do basic computing with just her voice. People like you forget how far software and hardware has come.GeoffreyA - Wednesday, April 7, 2021 - link
Sure, computers and devices are far more capable these days, from a hardware point of view, but applications, relying too much on GUI frameworks and modern languages, are more sluggish today than, say, a bare Win32 application of yore.