Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
Compiling LLVM, NAMD Performance
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
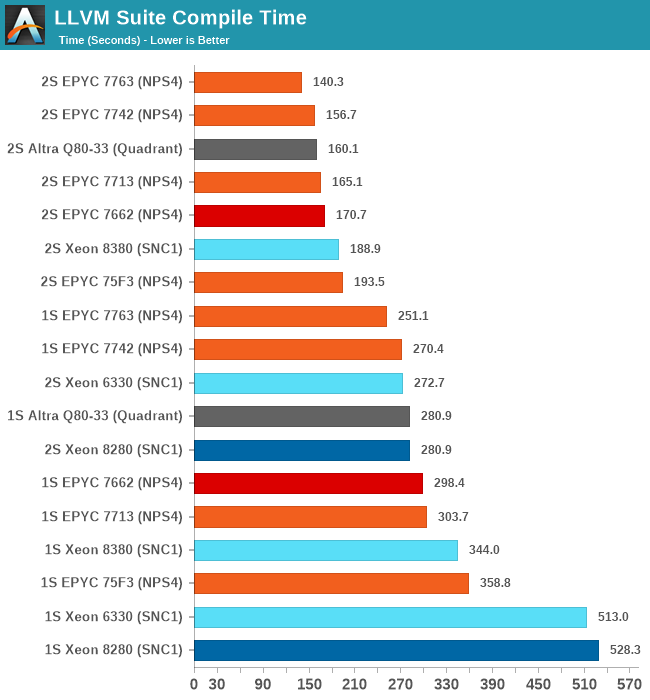
Starting off with the Xeon 8380, we’re looking at large generational improvements for the new Ice Lake SP chip. A 33-35% improvement in compile time depending on whether we’re looking at 2S or 1S figures is enough to reposition Intel’s flagship CPU in the rankings by notable amounts, finally no longer lagging behind as drastically as some of the competition.
It’s definitely not sufficient to compete with AMD and Ampere, both showcasing figures that are still 25 and 15% ahead of the Xeon 8380.
The Xeon 6330 is falling in line with where we benchmarked it in previous tests, just slightly edging out the Xeon 8280 (6258R equivalent), meaning we’re seeing minor ISO-core ISO-power generational improvements (again I have to mention that the 6330 is half the price of a 6258R).
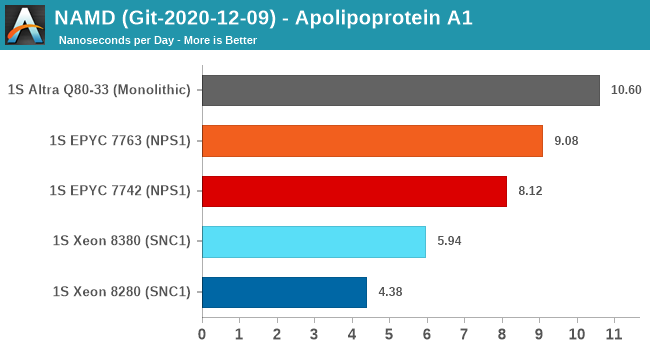
NAMD is a problem-child benchmark due to its recent addition of AVX512: the code had been contributed by Intel engineers – which isn’t exactly an issue in my view. The problem is that this is a new algorithm which has no relation to the normal code-path, which remains not as hand-optimised for AVX2, and further eyebrow raising is that it’s solely compatible with Intel’s ICC and no other compiler. That’s one level too much in terms of questionable status as a benchmark: are we benchmarking it as a general HPC-representative workload, or are we benchmarking it solely for the sake of NAMD and only NAMD performance?
We understand Intel is putting a lot of focus on these kinds of workloads that are hyper-optimised to run well extremely on Intel-only hardware, and it’s a valid optimisation path for many use-cases. I’m just questioning how representative it is of the wider market and workloads.
In any case, the GCC binaries of the test on the ApoA1 protein showcase significant performance uplifts for the Xeon 8380, showcasing a +35.6% gain. Using this apples-to-apples code path, it’s still quite behind the competition which scales the performance much higher thanks to more cores.








169 Comments
View All Comments
mode_13h - Monday, April 12, 2021 - link
With regard specifically to testing AVX-512, perhaps the best method is to include results both with and without it. This serves the dual-role of informing customers of the likely performance for software compiled with more typical options, as well as showing how much further performance is to be gained by using an AVX-512 optimized build.KurtL - Wednesday, April 7, 2021 - link
GCC the industry standard in real world? Maybe in that part of the world where you live, but not everywhere. It is only true in a part of the world. HPC centres have relied on icc for ages for much of the performance-critical code, though GCC is slowly catching up, at least for C and C++ but not at all for Fortran, an important language in HPC (I just read it made it back in the top-20 of most used languages after falling back to position 34 a year or so ago). In embedded systems and the non-x86-world in general, LLVM derived compilers have long been the norm. Commercial compiler vendors and CPU manufacturers are all moving to LLVM-based compilers or have been there for years already.Wilco1 - Wednesday, April 7, 2021 - link
Yes GCC is the industry standard for Linux. That's a simple fact, not something you can dispute.In HPC people are willing to use various compilers to get best performance, so it's certainly not purely ICC. And HPC isn't exclusively Intel or x86 based either. LLVM is increasing in popularity in the wider industry but it still needs to catch up to GCC in performance.
mode_13h - Wednesday, April 7, 2021 - link
GCC is the only supported compiler for building the Linux kernel, although Google is working hard to make it build with LLVM. They seem to believe it's better for security.From the benchmarks that Phoronix routinely publishes, each has its strengths and weaknesses. I think neither is a clear winner.
Wilco1 - Thursday, April 8, 2021 - link
Plus almost all distros use GCC - there is only one I know that uses LLVM. LLVM is slowly gaining popularity though.They are fairly close for general code, however recent GCC versions significantly improved vectorization, and that helps SPEC.
Wilco1 - Tuesday, April 6, 2021 - link
ICC and AMD's AOCC are SPEC trick compilers. Neither is used much in the real world since for real code they are typically slower than GCC or LLVM.Btw are you equally happy if I propose to use a compiler which replaces critical inner loops of the benchmarks with hand-optimized assembler code? It would be foolish not to take advantage of the extra performance you get only on those benchmarks...
ricebunny - Tuesday, April 6, 2021 - link
They are not SPEC tricks. You can use these compilers for any compliant C++ code that you have. In the last 10 years, the only time I didn’t use icc with Intel chips was on systems where I had no control over the sw ecosystem.Wilco1 - Tuesday, April 6, 2021 - link
They only exist because of SPEC. The latest ICC is now based on LLVM since it was falling further behind on typical code.ricebunny - Tuesday, April 6, 2021 - link
From my experience icc consistently produced better vectorized code.Anandtech again didn’t publicize the compiler flags they used to build the benchmark code. By default, gcc will not generate avx512 optimized code.
Wilco1 - Tuesday, April 6, 2021 - link
Maybe compared to old GCC/LLVM versions, but things have changed. There is now little difference between ICC and GCC when running SPEC in terms of vectorized performance. Note the amount of code that can benefit from AVX-512 is absolutely tiny, and the speedups in the real world are smaller than expected (see eg. SIMDJson results with hand-optimized AVX-512).And please read the article - the setup is clearly explained in every review: "We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2 (for Zen3 as well due to GCC 10.2 not having znver3). "