Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
Compiling LLVM, NAMD Performance
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
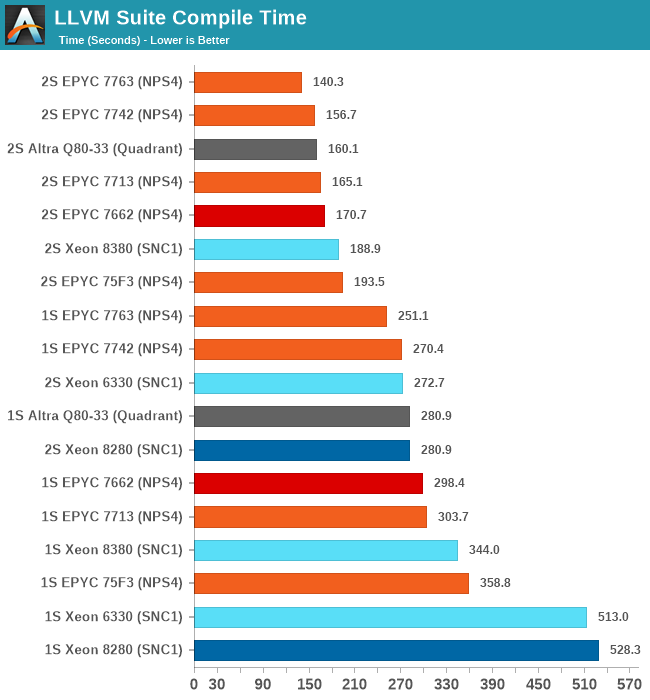
Starting off with the Xeon 8380, we’re looking at large generational improvements for the new Ice Lake SP chip. A 33-35% improvement in compile time depending on whether we’re looking at 2S or 1S figures is enough to reposition Intel’s flagship CPU in the rankings by notable amounts, finally no longer lagging behind as drastically as some of the competition.
It’s definitely not sufficient to compete with AMD and Ampere, both showcasing figures that are still 25 and 15% ahead of the Xeon 8380.
The Xeon 6330 is falling in line with where we benchmarked it in previous tests, just slightly edging out the Xeon 8280 (6258R equivalent), meaning we’re seeing minor ISO-core ISO-power generational improvements (again I have to mention that the 6330 is half the price of a 6258R).
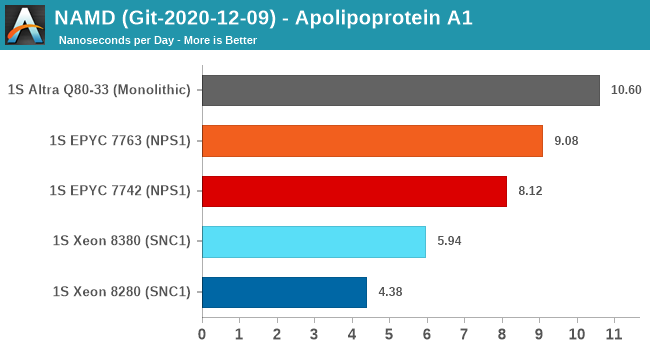
NAMD is a problem-child benchmark due to its recent addition of AVX512: the code had been contributed by Intel engineers – which isn’t exactly an issue in my view. The problem is that this is a new algorithm which has no relation to the normal code-path, which remains not as hand-optimised for AVX2, and further eyebrow raising is that it’s solely compatible with Intel’s ICC and no other compiler. That’s one level too much in terms of questionable status as a benchmark: are we benchmarking it as a general HPC-representative workload, or are we benchmarking it solely for the sake of NAMD and only NAMD performance?
We understand Intel is putting a lot of focus on these kinds of workloads that are hyper-optimised to run well extremely on Intel-only hardware, and it’s a valid optimisation path for many use-cases. I’m just questioning how representative it is of the wider market and workloads.
In any case, the GCC binaries of the test on the ApoA1 protein showcase significant performance uplifts for the Xeon 8380, showcasing a +35.6% gain. Using this apples-to-apples code path, it’s still quite behind the competition which scales the performance much higher thanks to more cores.








169 Comments
View All Comments
TomWomack - Wednesday, April 7, 2021 - link
Is it known whether there will be an IceLake-X this time round? The list of single-Xeon motherboard launches suggests possibly not; it would obviously be appealing to have a 24-core HEDT without paying the Xeon premium.EthiaW - Wednesday, April 7, 2021 - link
Boeings and Airbuses are never actually sold at their nominal prices, they cost far less, a non-disclosed number, for big buyers after gruesome haggling, sometimes less than half the “catalogue” price.I think this is exactly what's intel doing now: set the catalogue price high to avoid losing face, and give huge discount to avoid losing market share.
duploxxx - Wednesday, April 7, 2021 - link
well easy conclusion.EPYC 75F3 is the clear winner SKU and the must have for most of the workloads.
This is based on price - performance - cores and its related 3rd party sw licensing...
I wonder when Intel will be able to convince VMware to move from a 32core licensing schema to a 40core :)
They used to get all the dev favor when PAT was still in the house, I had several senior engineers in escalation calls stating that the hypervisor was optimised for Intel ...guess what even under optimised looking for a VM farm in 2020-2021-....you are way better off with an AMD build.
WaltC - Wednesday, April 7, 2021 - link
If you can't beat the competition, then what? Ian seems to be impressed that Intel was finally able to launch a Xeon that's a little faster than its previous Xeon, but not fast enough to justify the price tag in relation to what AMD has been offering for a while. So here we are congratulating Intel on burning through wads more cash to produce yet-another-non-competitive result. It really seems as if Intel *requires* AMD to set its goals and to tell it where it needs to go--and that is sad. It all began with x86-64 and SDRAM from AMD beating out Itanium and RDRAM years ago. And when you look at what Intel has done since it's just not all that impressive. Well, at least we can dispense with the notion that "Intel's 10nm is TSMC's 7nm" as that clearly is not the case.JayNor - Wednesday, April 7, 2021 - link
What about the networking applications of this new chip? Dan Rodriguez's presentation showed gains of 1.4x to 1.8x for various networking benchmarks. Intel's entry into 5G infrastructure, NFV, vRAN, ORAN, hybrid cloud is growing faster than they originally predicted. They are able to bundle Optane, SmartNICs, FPGAs, eASIC chips, XeonD, P5900 family Atom chips... I don't believe they have a competitor that can provide that level of solution.Bagheera - Thursday, April 8, 2021 - link
Patr!ck Patr!ck Partr!ck?evilpaul666 - Saturday, April 10, 2021 - link
It only works in front of a mirror. Donning a hoodie helps, too.Oxford Guy - Wednesday, April 7, 2021 - link
There is some faulty logic at work in many of the comments, with claims like it's cheating to use a more optimized compiler.It's not cheating unless:
• the compiler produces code that's so much more unstable/buggy that it's quite a bit more untrustworthy than the less-optimized compiler
• you don't make it clear to readers that the compiler may make the architecture look more performant simply because the other architectures may not have had compiler optimizations on the same level
• you use the same compiler for different architectures when using a different compiler for one or more other architectures will produce more optimized code for those architectures as well
• the compiler sabotages the competition, via things like 'genuine Intel'
Fact is that if a CPU can accomplish a certain amount of work in a certain amount of time, using a certain amount of watts under a certain level of cooling — that is the part's actual performance capability.
If that means writing machine code directly (not even assembly) to get to that performance level, so what? That's an entirely different matter, which is how practical/economical/profitable/effortful it is to get enough code to measure all of the different aspects of the part's maximum performance capability. The only time one can really cite that as a deal-breaker is if one has hard data to demonstrate that by the time the hand-tuned/optimized code is written changes to the architecture (and/or support chips/hardware) will obsolete the advantage — making the effort utterly fruitless, beyond intellectual curiosity concerning the part's ability. For instance, if one knows that Intel, for instance, is going to integrate new instructions (very soon) that will make various types of hand-tuned assembly obsolete in short order, it can be argued that it's not worth the effort to write the code. People made this argument with some of AMD's Bulldozer/Piledriver instructions, on the basis that enough industry adoption wasn't going to happen. But, frankly... if you're going to make claims about the part's performance, you really should do what you can to find out what it is.
Oxford Guy - Wednesday, April 7, 2021 - link
One can, though, of course... include a disclaimer that 'it seems clear enough that, regardless of how much hand-tuned code is done, the CPU isn't going to deliver enough to beat the competition, if the competition's code is similarly hand-tuned' — if that's the case. Even if a certain task is tuned to run twice as fast, is it going to be twice as fast as tuned code for the competition's stuff? Is its performance per watt deficit going to be erased? Will its pricing no longer be a drag on its perceived competitiveness?For example, one could have wrung every last drop of performance out of Bulldozer but it wasn't going to beat Sandy Bridge E — a chip with the same number of transistors. Piledriver could beat at least the desktop version of Sandy in certain workloads when clocked well outside of the optimal (for the node's performance per watt) range but that's where it's very helpful to have tests at the same clock. It was discovered, for instance, that the Fury X and Vega had basically identical performance at the same clock. Since desktop Sandy could easily clock at the same 4.0 GHz Piledriver initially shipped with it could be tested at that rate, too.
Ideally, CPU makers would release benchmarks that demonstrate every facet of their chip's maximum performance. The concern about those being best-case and synthetic is less of a problem in that scenario because all aspects of the chip's performance would be tested and published. That makes cherry-picking impossible.
mode_13h - Thursday, April 8, 2021 - link
The faulty logic I see is that you seem to believe it's the review's job to showcase the product in the best possible light. No, that's Intel's job, and you can find plenty of that material at intel.com, if that's what you want.Articles like this should focus on representing the performance of the CPUs as the bulk of readers are likely to experience it. So, even if using some vendor-supplied compiler with trick settings might not fit your definition of "cheating", that doesn't mean it's a service to the readers.
I think it could be appropriate to do that sort of thing, in articles that specifically analyze some narrow aspect of a CPU, for instance to determine the hardware's true capabilities or if it was just over-hyped. But, not in these sort of overall reviews.