Intel Core i7-11700K Review: Blasting Off with Rocket Lake
by Dr. Ian Cutress on March 5, 2021 4:30 PM EST- Posted in
- CPUs
- Intel
- 14nm
- Xe-LP
- Rocket Lake
- Cypress Cove
- i7-11700K
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
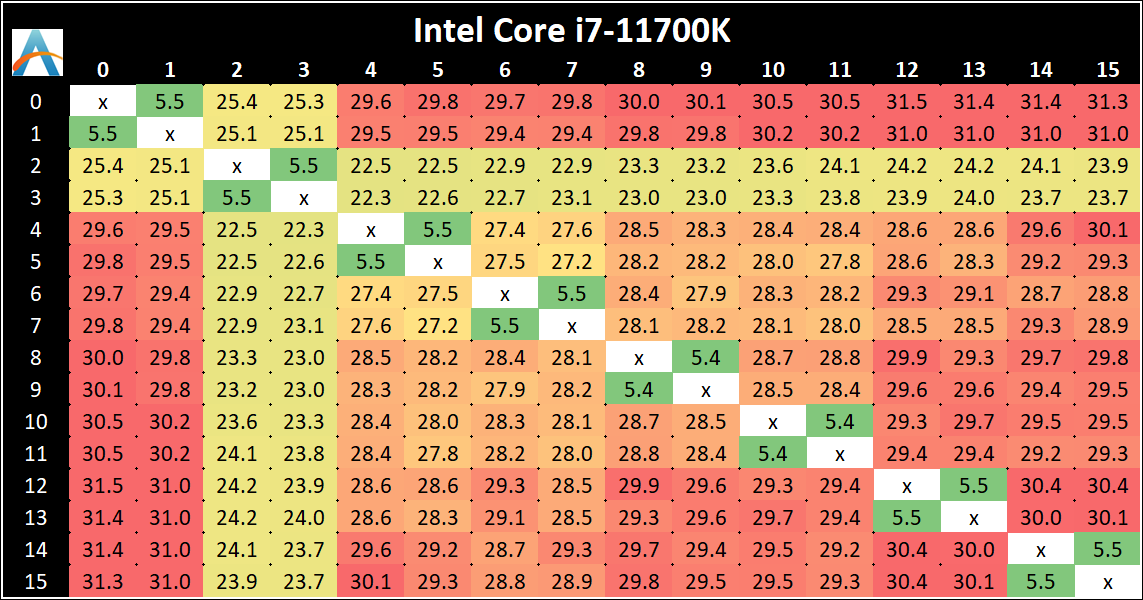
The core-to-core numbers are interesting, being worse (higher) than the previous generation across the board. Here we are seeing, mostly, 28-30 nanoseconds, compared to 18-24 nanoseconds with the 10700K. This is part of the L3 latency regression, as shown in our next tests.
One pair of threads here are very fast to access all cores, some 5 ns faster than any others, which again makes the layout more puzzling.
Update 1: With microcode 0x34, we saw no update to the core-to-core latencies.
Cache-to-DRAM Latency
This is another in-house test built by Andrei, which showcases the access latency at all the points in the cache hierarchy for a single core. We start at 2 KiB, and probe the latency all the way through to 256 MB, which for most CPUs sits inside the DRAM (before you start saying 64-core TR has 256 MB of L3, it’s only 16 MB per core, so at 20 MB you are in DRAM).
Part of this test helps us understand the range of latencies for accessing a given level of cache, but also the transition between the cache levels gives insight into how different parts of the cache microarchitecture work, such as TLBs. As CPU microarchitects look at interesting and novel ways to design caches upon caches inside caches, this basic test proves to be very valuable.
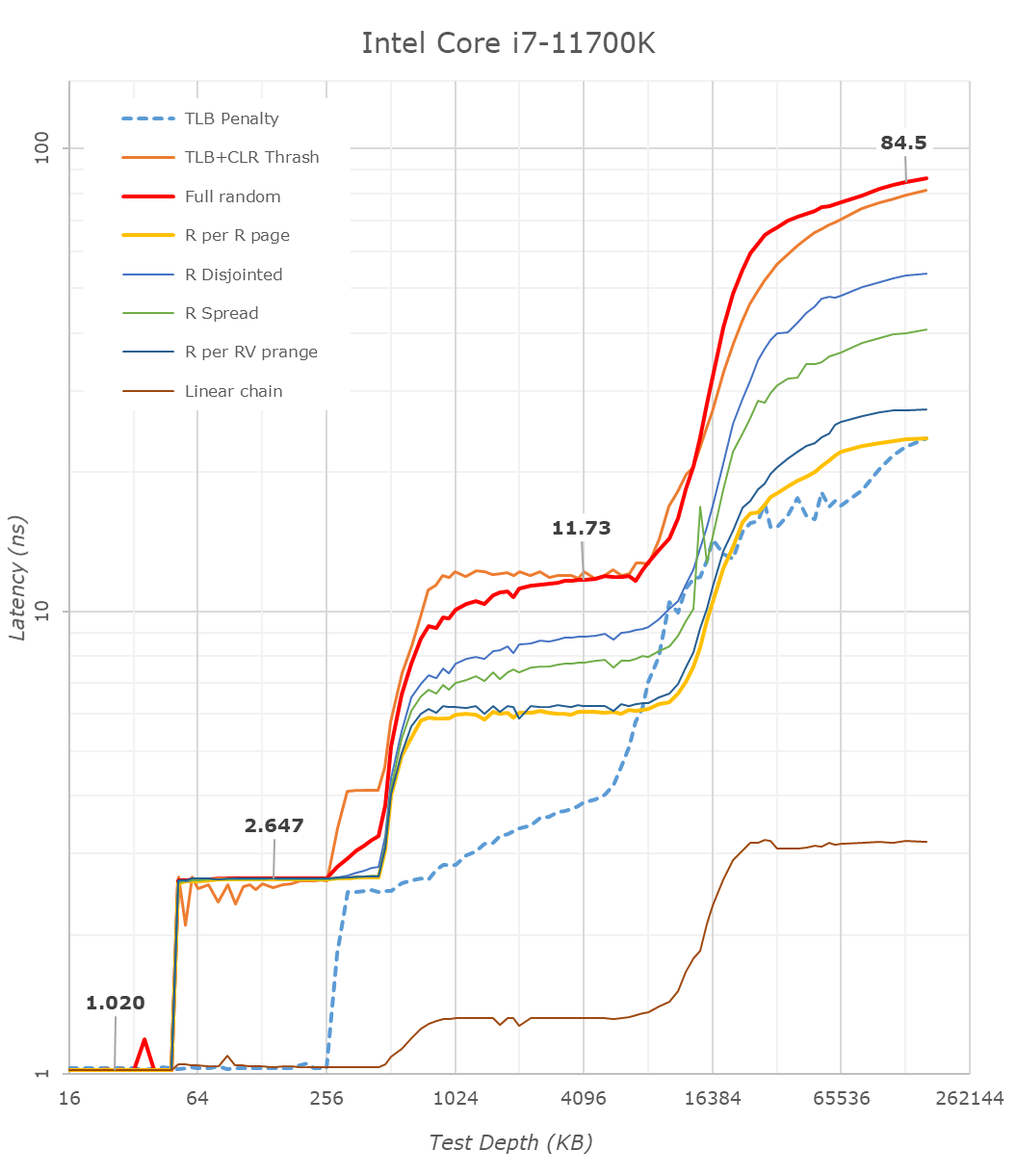
Looking at the rough graph of the 11700K and the general boundaries of the cache hierarchies, we again see the changes of the microarchitecture that had first debuted in Intel’s Sunny Cove cores, such as the move from an L1D cache from 32KB to 48KB, as well as the doubling of the L2 cache from 256KB to 512KB.
The L3 cache on these parts look to be unchanged from a capacity perspective, featuring the same 16MB which is shared amongst the 8 cores of the chip.
On the DRAM side of things, we’re not seeing much change, albeit there is a small 2.1ns generational regression at the full random 128MB measurement point. We’re using identical RAM sticks at the same timings between the measurements here.
It’s to be noted that these slight regressions are also found across the cache hierarchies, with the new CPU, although it’s clocked slightly higher here, shows worse absolute latency than its predecessor, it’s also to be noted that AMD’s newest Zen3 based designs showcase also lower latency across the board.
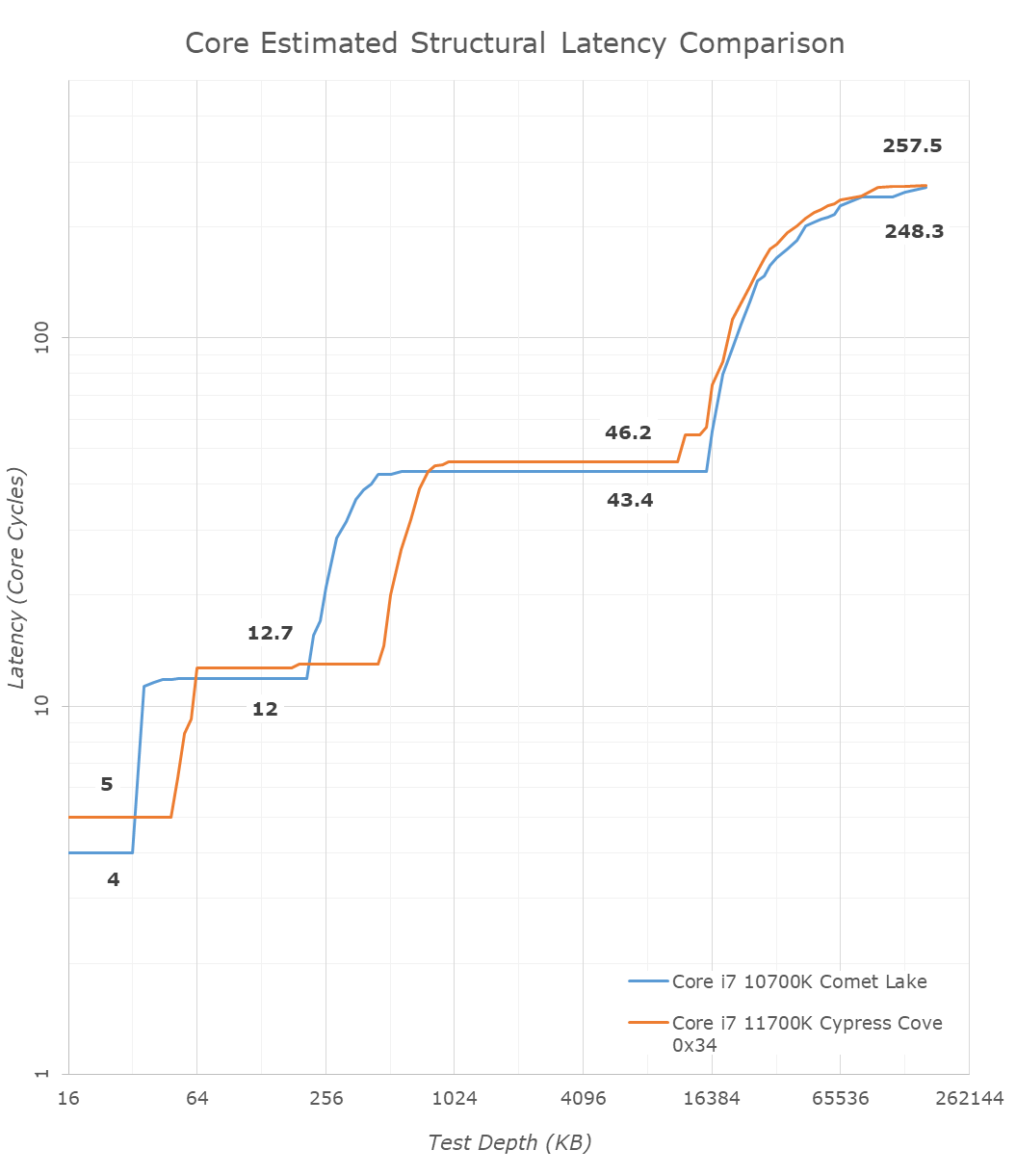
With the new graph of the Core i7-11700K with microcode 0x34, the same cache structures are observed, however we are seeing better performance with L3.
The L1 cache structure is the same, and the L2 is of a similar latency. In our previous test, the L3 latency was 50.9 cycles, but with the new microcode is now at 45.1 cycles, and is now more in line with the L3 cache on Comet Lake.
Out at DRAM, our 128 MB point reduced from 82.4 nanoseconds to 72.8 nanoseconds, which is a 12% reduction, but not the +40% reduction that other media outlets are reporting as we feel our tools are more accurate. Similarly, for DRAM bandwidth, we are seeing a +12% memory bandwidth increase between 0x2C and 0x34, not the +50% bandwidth others are claiming. (BIOS 0x1B however, was significantly lower than this, resulting in a +50% bandwidth increase from 0x1B to 0x34.)
In the previous edition of our article, we questioned the previous L3 cycle being a larger than estimated regression. With the updated microcode, the smaller difference is still a regression, but more in line with our expectations. We are waiting to hear back from Intel what differences in the microcode encouraged this change.
Frequency Ramping
Both AMD and Intel over the past few years have introduced features to their processors that speed up the time from when a CPU moves from idle into a high powered state. The effect of this means that users can get peak performance quicker, but the biggest knock-on effect for this is with battery life in mobile devices, especially if a system can turbo up quick and turbo down quick, ensuring that it stays in the lowest and most efficient power state for as long as possible.
Intel’s technology is called SpeedShift, although SpeedShift was not enabled until Skylake.
One of the issues though with this technology is that sometimes the adjustments in frequency can be so fast, software cannot detect them. If the frequency is changing on the order of microseconds, but your software is only probing frequency in milliseconds (or seconds), then quick changes will be missed. Not only that, as an observer probing the frequency, you could be affecting the actual turbo performance. When the CPU is changing frequency, it essentially has to pause all compute while it aligns the frequency rate of the whole core.
We wrote an extensive review analysis piece on this, called ‘Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics’, due to an issue where users were not observing the peak turbo speeds for AMD’s processors.
We got around the issue by making the frequency probing the workload causing the turbo. The software is able to detect frequency adjustments on a microsecond scale, so we can see how well a system can get to those boost frequencies. Our Frequency Ramp tool has already been in use in a number of reviews.
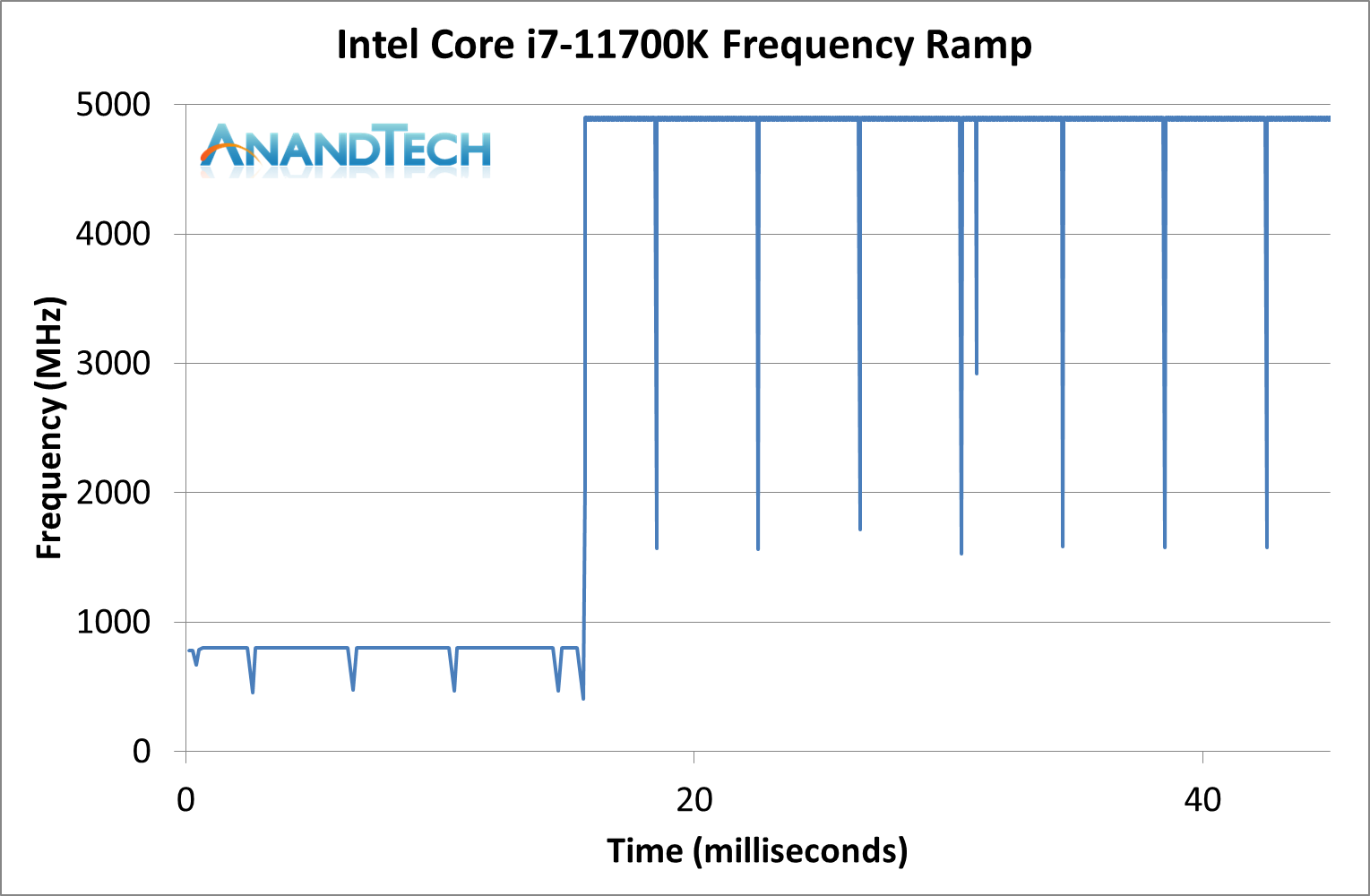
Our ramp test shows a jump straight from 800 MHz up to 4900 MHz in around 17 milliseconds, or a frame at 60 Hz.








541 Comments
View All Comments
blppt - Saturday, March 13, 2021 - link
They did try to at least 'ride it out' until Zen could get done, and that required smoothing out the rough edges, so they did devote some resources.BD/PD never did any better than a low-end solution for the desktop/laptop market, but they had to offer something until Zen was done.
Oxford Guy - Sunday, March 28, 2021 - link
'They did try to at least 'ride it out' until Zen could get done, and that required smoothing out the rough edges, so they did devote some resources.'Wow... watch the goal posts move.
Riding out = doing nothing. Piledriver was not improved. The entire higher-performance & supercomputer market was unchanged from Piledriver to Zen. All AMD did was ship cheap knock-off APU rubbish and console trash.
The fact that AMD succeeded with Zen is probably mostly a testament to one largely ignored feature of monopoly power: the monopolist can become so slow and inefficient that a nearly dead competitor can come back to best it. That's not symptomatic of a well-run economic system. It's a trainwreck.
AMD should have been wealthy enough to do proper R&D and bulldozer would have never happened in the first place. But, Intel was a huge abusive monopolist and everyone went right along, content to feed the problem. After AMD did Bulldozer and Piledriver the company should have been dead. If there had been adequate competition it would have been. So, ironically, AMD can thank Intel for being its only competition, for resting on its laurels because of its extreme monopolization.
GeoffreyA - Wednesday, March 10, 2021 - link
Oxford Guy. I don't remember the exact details and am running largely from memory here. Yes, I agree, Bulldozer had far lower IPC than Phenom, but, according to their belief, was supposed to restore them to the top and knock Intel down. In practice, it failed miserably and was worse even than Netburst. Credit must be given, however, for their raising Bulldozer's IPC a lot each generation (something like 20-30% if I remember right), and curtailing power. It also addressed weaknesses in K10 and surpassed K10's IPC eventually. Anyway, working against such a hopeless design surely taught them a lot; and pouring that knowledge into a classic x86 design, Zen, took it further than Skylake after just one iteration.AMD would have done better had they just persisted with K10, which wasn't that far behind Nehalem. But, perhaps we wouldn't have had Zen: it took AMD's going through the lowest depths, passing through the fire as it were, to become what they are today, leaving Intel baffled. I agree, they were truly idiotic in the last decade but no more. May it stay that way!
Concerning CMT, I don't know much about it to comment, but think Bulldozer's principal weakness came from sharing execution units---the FP units I believe and others---between modules. Zen kept each core separate and gave it full (and weighty) resources, along with a micro-op cache and other improvements. As for Jaguar, it may be junk from a desktop point of view, yes, but was excellent in its domain and left Atom in the dust.
Oxford Guy - Sunday, March 28, 2021 - link
'Credit must be given, however, for their raising Bulldozer's IPC a lot each generation (something like 20-30% if I remember right), and curtailing power.'Piledriver was a small IPC improvement and regressed in AVX. Piledriver's AVX was so extremely poor that it was faster to not use it. Piledriver was a massive power hog. The 32nm SOI process node, according to 'TheStilt' was improved over time which is probably the main source of power efficiency improvement in Piledriver versus Bulldozer. I do not recall the IPC improvement of Piledriver over Bulldozer but it was nothing close to 20% I think. Instead, it merely made it possible to raise clocks further, along with the aforementioned node improvement. And, 'TheStilt' said the node got better after Piledriver's first generation. The 'E' parts, for instance, were quite a lot improved in leakage — but the whole line (other than the 9000 series which he said should have been sent to the scrapper) improved in leakage. What didn't improve, sadly, is the bad Piledriver design. AMD never bothered to fix it.
While Piledriver, when clocked high (like 4.7 GHz) could be relevant against Sandy in multi-thread (including well-threaded games like Desert of Kharak) it was extremely pitiful in single-thread. And, it sucked down boatloads of power to get to 4.7, even with the best-leakage chips.
And, going back to your 20–30% claim. Steamroller, which was considered a serious disappointment, featured only 4 of the CMT quasi cores, not 8. Excavator cut things in cache land even further. Both were cost-cutting parts, not performance improvements. Piledriver killed both of them simply by turning up the clocks high. The multi-thread performance of Steamroller and Excavator was not competitive because of the lack of cache, lack of cores, and lack of clock. Single-thread was a bit improved but, again, the only thing one could really do was blast current through Piledriver. It was a disgusting situation due to the single-threaded performance, which was unacceptable in 2012 and an abomination for the later years AMD kept peddling Piledriver in.
The only credit AMD deserves for the construction core period is not going out of business, despite trying so hard to do that.
GeoffreyA - Sunday, March 28, 2021 - link
Oxford Guy, while I respect your view, I do not agree with it, and still stand by my statement that AMD deserves credit for improving Bulldozer and executing yearly. Agreed, my 20-30% claim was not sober but I just meant it as a recollection and did qualify my statement.I don't think it's fair to put AMD down for embarking on Bulldozer. When they set out, quite likely they thought it was going to go further than the aging Phenom/K10 design, and the fact is, while falling behind in IPC compared with K10, it improved on a lot of points and laid the foundation. Its chief weakness was the idea of sharing resources, like the fetch, decode, and FP units, as well as going for a deeper pipeline. (The difference from Netburst is that Bulldozer was decently wide.)
Piledriver refined the foundation, raising IPC and adding a perceptron branch predictor, still used in Zen by the way, and I believe finally surpassed K10's IPC (and that of Llano). While being made on the same 32 nm process, it dropped power by switching to hard-edge flip flops, which took some work to put in. They used that lowered power to raise clock speeds, bringing power to the same level as Bulldozer. And Trinity, the Piledriver APU, surpassed Llano. I need to learn more about Steamroller and Excavator before I comment, but note in passing that SR improved the architecture again, giving each integer core its own fetch/decode units, among other things; and Excavator switched to GPU libraries in laying out the circuitry, dropping power and area, the tradeoff being lower frequency.
GeoffreyA - Sunday, March 28, 2021 - link
Also, the reviews show that things were not as bad as we remember, though power was terrible.https://www.anandtech.com/show/6396/the-vishera-re...
https://www.anandtech.com/show/5831/amd-trinity-re...
Oxford Guy - Tuesday, April 6, 2021 - link
I don't need to look at reviews agaih. I know how bad the IPC was in Bulldozer, Piledriver, Steamroller, and Excavator. Single-thread in Cinebench R15, for instance, was really low even at 5.2 GHz in Piledriver. It takes chilled water to get it to bench at that clock.GeoffreyA - Wednesday, March 10, 2021 - link
Lack of competition, high prices, lack of integrity. I agree it's one big mess, but there's so little we can do, except boycotting their products. As it stands, the best advice is likely: find a product at a decent price, buy it, be happy, and let these rotten companies do what they want.Oxford Guy - Sunday, March 28, 2021 - link
'find a product at a decent price, buy it, be happy'Buy a product you can't buy so you can prop up monopolies that cause the problem of shortage + bad pricing + low choice (features to choose from/i.e. innovation, limited).
GeoffreyA - Sunday, March 28, 2021 - link
The only solution is a worldwide boycott of their products, till they drop their prices, etc.