Intel Core i7-11700K Review: Blasting Off with Rocket Lake
by Dr. Ian Cutress on March 5, 2021 4:30 PM EST- Posted in
- CPUs
- Intel
- 14nm
- Xe-LP
- Rocket Lake
- Cypress Cove
- i7-11700K
CPU Tests: Encoding
One of the interesting elements on modern processors is encoding performance. This covers two main areas: encryption/decryption for secure data transfer, and video transcoding from one video format to another.
In the encrypt/decrypt scenario, how data is transferred and by what mechanism is pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security.
Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
HandBrake 1.32: Link
Video transcoding (both encode and decode) is a hot topic in performance metrics as more and more content is being created. First consideration is the standard in which the video is encoded, which can be lossless or lossy, trade performance for file-size, trade quality for file-size, or all of the above can increase encoding rates to help accelerate decoding rates. Alongside Google's favorite codecs, VP9 and AV1, there are others that are prominent: H264, the older codec, is practically everywhere and is designed to be optimized for 1080p video, and HEVC (or H.265) that is aimed to provide the same quality as H264 but at a lower file-size (or better quality for the same size). HEVC is important as 4K is streamed over the air, meaning less bits need to be transferred for the same quality content. There are other codecs coming to market designed for specific use cases all the time.
Handbrake is a favored tool for transcoding, with the later versions using copious amounts of newer APIs to take advantage of co-processors, like GPUs. It is available on Windows via an interface or can be accessed through the command-line, with the latter making our testing easier, with a redirection operator for the console output.
We take the compiled version of this 16-minute YouTube video about Russian CPUs at 1080p30 h264 and convert into three different files: (1) 480p30 ‘Discord’, (2) 720p30 ‘YouTube’, and (3) 4K60 HEVC.
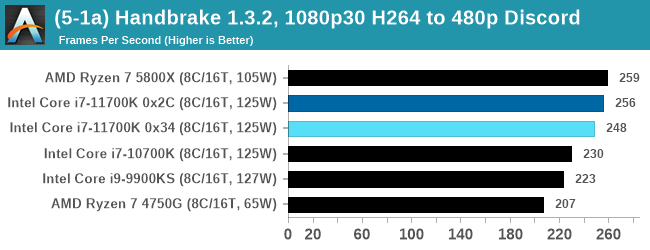
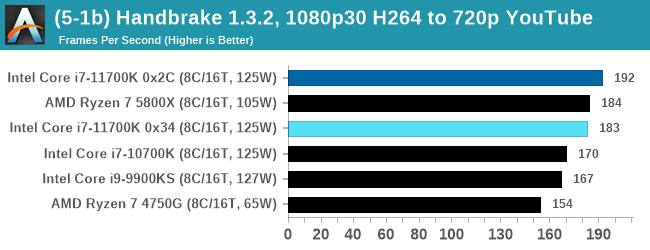
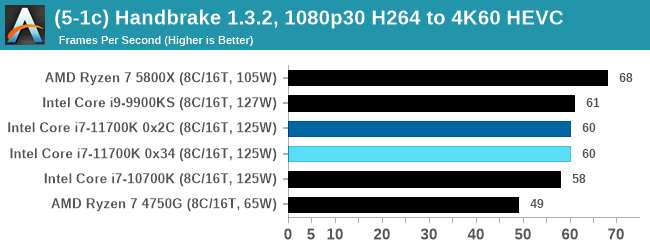
Up to the final 4K60 HEVC, in CPU-only mode, the Intel CPU puts up some good gen-on-gen numbers.
7-Zip 1900: Link
The first compression benchmark tool we use is the open-source 7-zip, which typically offers good scaling across multiple cores. 7-zip is the compression tool most cited by readers as one they would rather see benchmarks on, and the program includes a built-in benchmark tool for both compression and decompression.
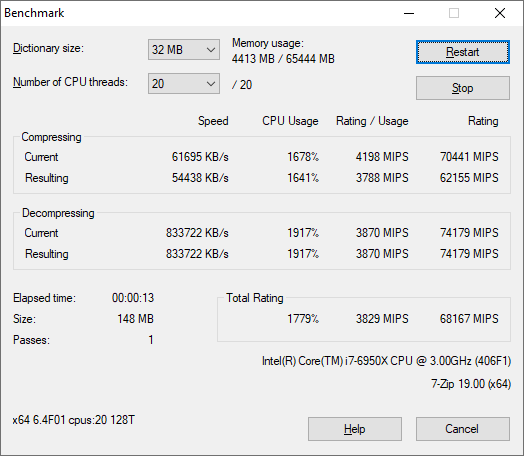
The tool can either be run from inside the software or through the command line. We take the latter route as it is easier to automate, obtain results, and put through our process. The command line flags available offer an option for repeated runs, and the output provides the average automatically through the console. We direct this output into a text file and regex the required values for compression, decompression, and a combined score.
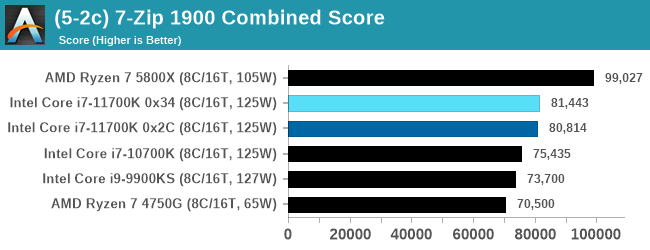
An increase over the previous generation, but AMD has a 25% lead.
AES Encoding
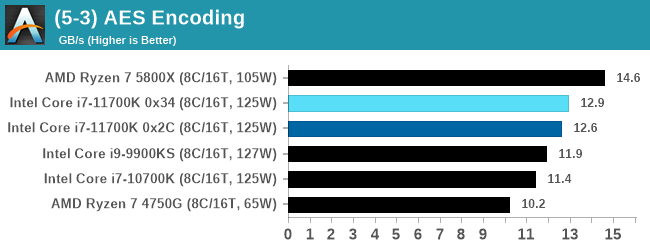
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.
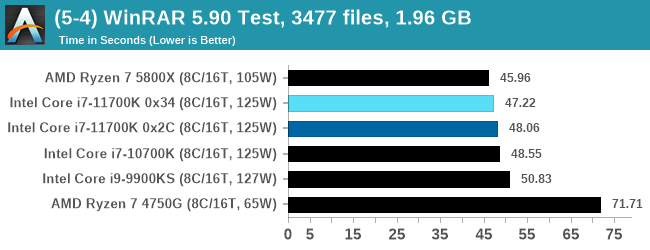
WinRAR 5.90: Link
For the 2020 test suite, we move to the latest version of WinRAR in our compression test. WinRAR in some quarters is more user friendly that 7-Zip, hence its inclusion. Rather than use a benchmark mode as we did with 7-Zip, here we take a set of files representative of a generic stack
- 33 video files , each 30 seconds, in 1.37 GB,
- 2834 smaller website files in 370 folders in 150 MB,
- 100 Beat Saber music tracks and input files, for 451 MB
This is a mixture of compressible and incompressible formats. The results shown are the time taken to encode the file. Due to DRAM caching, we run the test for 20 minutes times and take the average of the last five runs when the benchmark is in a steady state.
For automation, we use AHK’s internal timing tools from initiating the workload until the window closes signifying the end. This means the results are contained within AHK, with an average of the last 5 results being easy enough to calculate.
CPU Tests: Legacy and Web
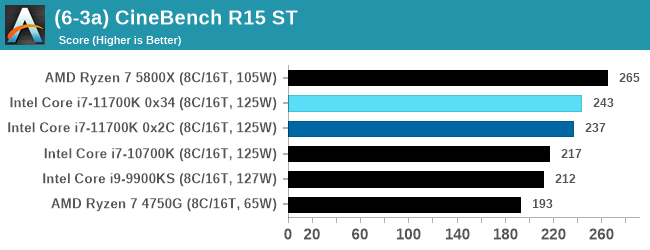
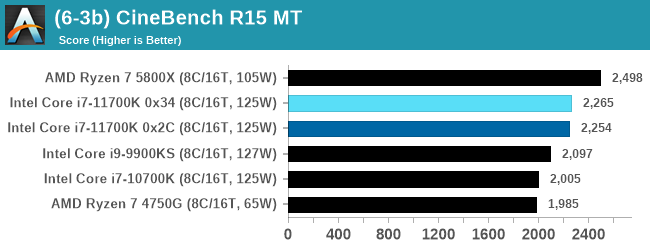
In order to gather data to compare with older benchmarks, we are still keeping a number of tests under our ‘legacy’ section. This includes all the former major versions of CineBench (R15, R11.5, R10) as well as x264 HD 3.0 and the first very naïve version of 3DPM v2.1. We won’t be transferring the data over from the old testing into Bench, otherwise it would be populated with 200 CPUs with only one data point, so it will fill up as we test more CPUs like the others.
The other section here is our web tests.
Web Tests: Kraken, Octane, and Speedometer
Benchmarking using web tools is always a bit difficult. Browsers change almost daily, and the way the web is used changes even quicker. While there is some scope for advanced computational based benchmarks, most users care about responsiveness, which requires a strong back-end to work quickly to provide on the front-end. The benchmarks we chose for our web tests are essentially industry standards – at least once upon a time.
It should be noted that for each test, the browser is closed and re-opened a new with a fresh cache. We use a fixed Chromium version for our tests with the update capabilities removed to ensure consistency.
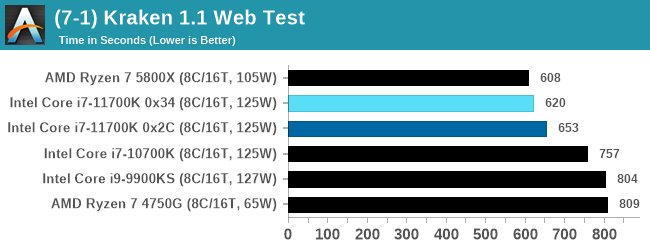
Mozilla Kraken 1.1
Kraken is a 2010 benchmark from Mozilla and does a series of JavaScript tests. These tests are a little more involved than previous tests, looking at artificial intelligence, audio manipulation, image manipulation, json parsing, and cryptographic functions. The benchmark starts with an initial download of data for the audio and imaging, and then runs through 10 times giving a timed result.

We loop through the 10-run test four times (so that’s a total of 40 runs), and average the four end-results. The result is given as time to complete the test, and we’re reaching a slow asymptotic limit with regards the highest IPC processors.
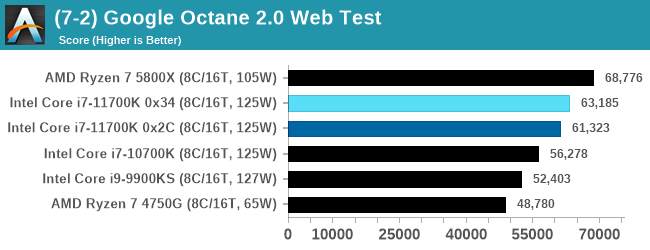
Google Octane 2.0
Our second test is also JavaScript based, but uses a lot more variation of newer JS techniques, such as object-oriented programming, kernel simulation, object creation/destruction, garbage collection, array manipulations, compiler latency and code execution.
Octane was developed after the discontinuation of other tests, with the goal of being more web-like than previous tests. It has been a popular benchmark, making it an obvious target for optimizations in the JavaScript engines. Ultimately it was retired in early 2017 due to this, although it is still widely used as a tool to determine general CPU performance in a number of web tasks.
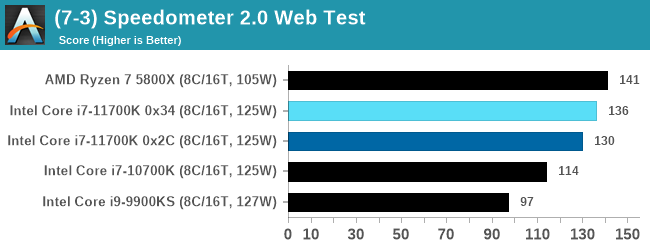
Speedometer 2: JavaScript Frameworks
Our newest web test is Speedometer 2, which is a test over a series of JavaScript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles.
Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics.
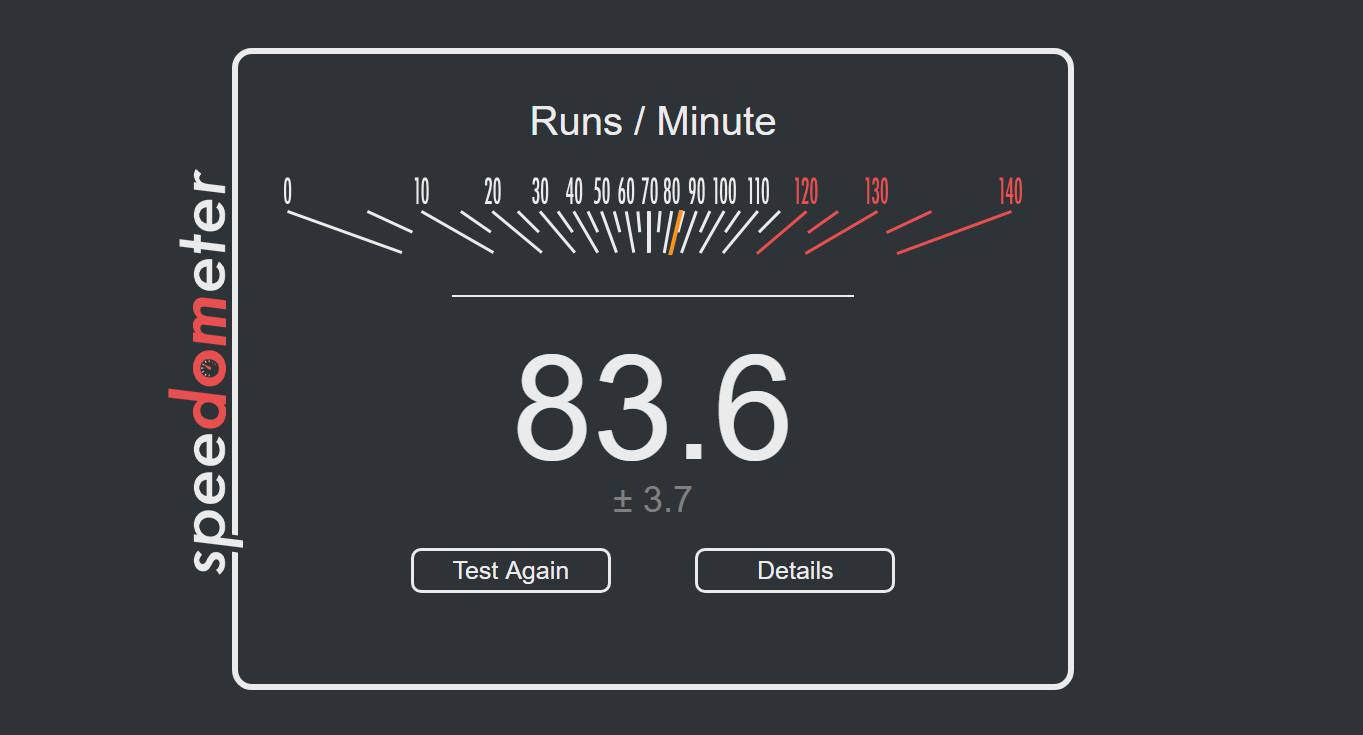
We repeat over the benchmark for a dozen loops, taking the average of the last five.
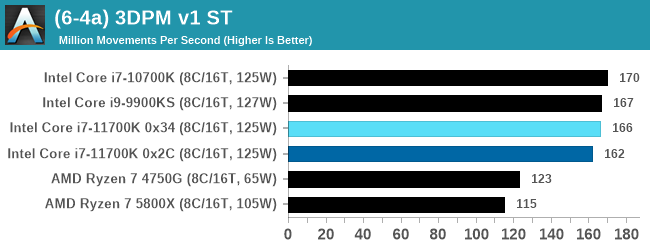
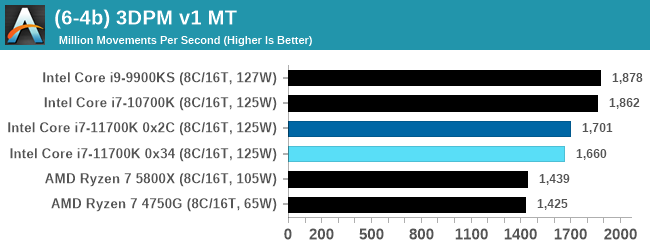
Legacy Tests








541 Comments
View All Comments
blppt - Saturday, March 13, 2021 - link
Not really---the Bulldozer design had far more problems than just the inadequate Windows scheduler---while "optimized" linux kernels gave better performance, the true issue with Bulldozer was that you had 8 relatively weak cores versus 4 strong cores from Intel, and at the time, coders were still struggling to optimize for anything over 2 cores.In a sense, the designers of Bulldozer REALLY misread the timeline of highly multithreaded coding taking over the market. Heck, even if it was released now alongside the equivalent Core 2 quads, it would still stink for the majority of users, because no game gets any significant advantage of 4+ physical cores even today---and most games still value high single thread/core performance.
Oxford Guy - Sunday, March 28, 2021 - link
'the true issue with Bulldozer was that you had 8 relatively weak cores versus 4 strong cores from Intel, and at the time, coders were still struggling to optimize for anything over 2 cores. In a sense, the designers of Bulldozer REALLY misread the timeline of highly multithreaded coding taking over the market.'My guess is that AMD designed Bulldozer for the enterprise market and didn't want to invest in an additional design more suited to the consumer desktop space. Instead, its additional design priority was the console scam (Jaguar). While that was a good move for AMD it wasn't beneficial for consumers, as consoles are a parasitic redundancy.
One thing many ignore is that Piledriver supercomputers occupied quite high spots in the world performance lists. Mostly that was due to the majority of their work being done by the GPUs, though. Even the original Bulldozer, in Opteron branding, was used in some.
The cheapness of Piledriver chips was also probably a factor in the adoption of the design for supercomputers. Turn down the voltage/wattage so that you're in the efficient part of the improved 32nm SOI node and rely almost completely on heavily threaded code when not running GPU-specific code... and voila — you have an alternative to the monopoly-priced Intel stuff.
But, on the desktop, Piledriver was a bad joke. That's because of its very poor single-thread performance mainly. Not everything can be multi-threaded and even if it is that can mean a speed regression sometimes. The slowness of the L3, the lack of enough operations caching... the design wasn't even all that optimized for multi-thread performance — especially FPU stuff. The cores were very deeply pipelined, designed to use very high clocks. They were not efficient with avoiding bubbles and such. I read that AMD relied too heavily on automated tools due to cost sensitivity.
My vague understanding of the design is that it was narrow and deep like the Pentium 4. Why AMD tried NetBurst 2.0 is beyond me. Even for the enterprise market it's a bad move because power efficiency is important there, especially with servers (rather than supercomputers which, I think, were more tolerant of high power usage – in terms of acceptable design requirements). Even turning down the clocks/voltage to get the best efficiency from the node doesn't fix the issue of the pipelining inefficiency (although hand-tuned code used for some enterprise/scientific stuff would mask that weakness more than general-purpose consumer-grade apps would).
usiname - Monday, March 8, 2021 - link
Intel know very well that is mistake, but alder lake's big cores are not much better in term of power consumption and 10nm quality wafers so their only choice is to keep the production of max 8 core mainstream. This is bad for them, because even 3 years after AMD show 16 core mainstream they can't and as our very well known Intel they will cheat by introduce their 16 core cpu with 8 fake cores. Even more, when they introduce their "super duper" 12900k with 16 cores they will set price higher than every amd main stream and this is triple win, cheap 8 core cpu for manufacturing, better binned with higher clocks and on price of $800-1000. If you think intel trying to do something new and innovative you are wrong.GeoffreyA - Monday, March 8, 2021 - link
You may well turn out to be right about 16 cores having 8 junk ones, and knowing Intel, that's how they operate, with smoke and mirrors when they can't compete properly.Hifihedgehog - Tuesday, March 9, 2021 - link
The irony here is how Intel used to give ARM smack for having inferior single core performance while they were surpassed in multicore by the likes of Qualcomm. I believe—paraphrasing—what they would say is not all cores are created equal. Well, it looks like Intel is trying to look like they are maintaining parity when they are really just giving us mostly crappy cores that can’t perform well at all.GeoffreyA - Tuesday, March 9, 2021 - link
Also, as others have pointed out before, the nomenclature is just there to obfuscate the whole picture. Not knowing anything much about Alder Lake, I did some searching and saw that it's Golden Cove + Gracemont. Wondering what exactly GC was, I searched a little but couldn't find the answer, so I'll guess it's just Sunny Cove with a new name stuck on.Bagheera - Monday, March 8, 2021 - link
the more I read about Intel's 10nm (check relevant articles on SemiWiki and Semi accurate), the more I feel ADL is designed as a workaround for the power/thermal limitations of their 10nm process, instead of being some sort of revelation for next gen performance.Note how TGL remains Intel's only viable product on 10nm at the moment, with Ice Lake SP now two years late. I think Intel knows their 10nm may never be ready for desktop parts, so ADL is a way to have a desktop product on 10nm except not really (it's more akin to a mobile part).
It will probably do fine for gaming, but highly doubtful it will be a meaningful competition to Zen 4 for the prosumer space.
blppt - Monday, March 8, 2021 - link
Bulldozer/Piledriver were a dumb design because they relied HEAVILY on highly-threaded applications to achieve their performance. Almost none of which existed in the late 2000s when they launched. Single thread/core performance was absolutely pathetic compared to Intel's offerings at the time (Sandy Bridge and on).Zan Lynx - Sunday, March 14, 2021 - link
And yet here we are today with 8 cores in game consoles and AMD's Mantle API being the basis of both DirectX 12 and Vulkan. Multicore was always the future and it was obvious even in 2003.blppt - Monday, March 15, 2021 - link
"And yet here we are today with 8 cores in game consoles and AMD's Mantle API being the basis of both DirectX 12 and Vulkan. Multicore was always the future and it was obvious even in 200"You're missing the point. Even TODAY, few (if any) games gain an advantage of more than 4 physical cores + 4 Virtual. It is still, to this day, far more advantageous for games to have 4 strong physical cores than 8 weak ones. The latter was Bulldozer.
Never mind back in 2011/2012.