Intel Core i7-11700K Review: Blasting Off with Rocket Lake
by Dr. Ian Cutress on March 5, 2021 4:30 PM EST- Posted in
- CPUs
- Intel
- 14nm
- Xe-LP
- Rocket Lake
- Cypress Cove
- i7-11700K
CPU Tests: Simulation
Simulation and Science have a lot of overlap in the benchmarking world, however for this distinction we’re separating into two segments mostly based on the utility of the resulting data. The benchmarks that fall under Science have a distinct use for the data they output – in our Simulation section, these act more like synthetics but at some level are still trying to simulate a given environment.
DigiCortex v1.35: link
DigiCortex is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation, similar to a small slug.
The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
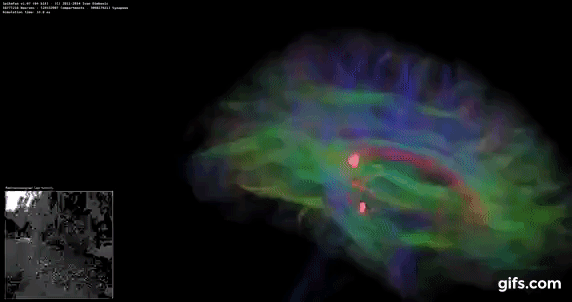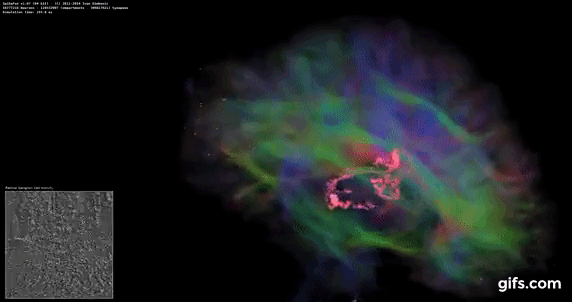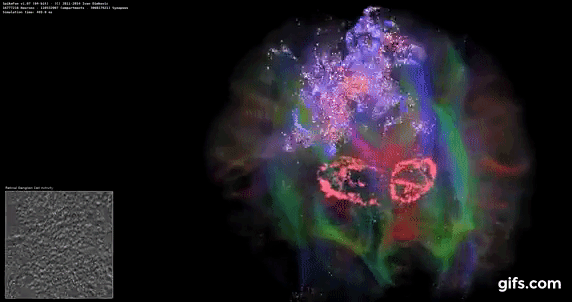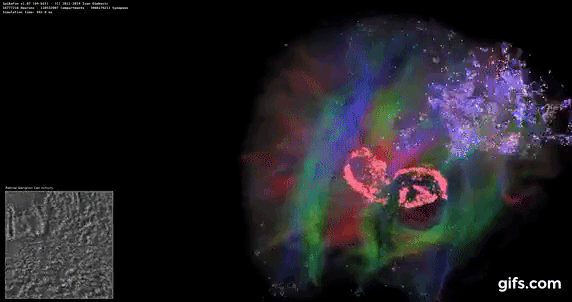
The software originally shipped with a benchmark that recorded the first few cycles and output a result. So while fast multi-threaded processors this made the benchmark last less than a few seconds, slow dual-core processors could be running for almost an hour. There is also the issue of DigiCortex starting with a base neuron/synapse map in ‘off mode’, giving a high result in the first few cycles as none of the nodes are currently active. We found that the performance settles down into a steady state after a while (when the model is actively in use), so we asked the author to allow for a ‘warm-up’ phase and for the benchmark to be the average over a second sample time.
For our test, we give the benchmark 20000 cycles to warm up and then take the data over the next 10000 cycles seconds for the test – on a modern processor this takes 30 seconds and 150 seconds respectively. This is then repeated a minimum of 10 times, with the first three results rejected. Results are shown as a multiple of real-time calculation.
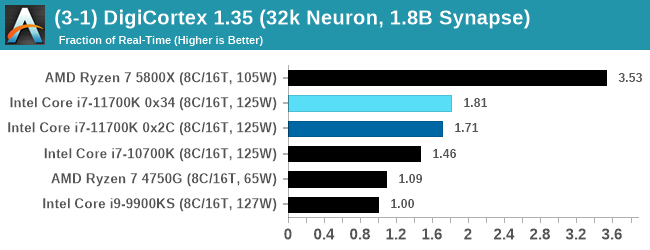
AMD's single chiplet design seems to get a big win here, but DigiCortex can use AVX-512 so the 11700K gets a healthy boost over the previous generation.
Dwarf Fortress 0.44.12: Link
Another long standing request for our benchmark suite has been Dwarf Fortress, a popular management/roguelike indie video game, first launched in 2006 and still being regularly updated today, aiming for a Steam launch sometime in the future.
Emulating the ASCII interfaces of old, this title is a rather complex beast, which can generate environments subject to millennia of rule, famous faces, peasants, and key historical figures and events. The further you get into the game, depending on the size of the world, the slower it becomes as it has to simulate more famous people, more world events, and the natural way that humanoid creatures take over an environment. Like some kind of virus.
For our test we’re using DFMark. DFMark is a benchmark built by vorsgren on the Bay12Forums that gives two different modes built on DFHack: world generation and embark. These tests can be configured, but range anywhere from 3 minutes to several hours. After analyzing the test, we ended up going for three different world generation sizes:
- Small, a 65x65 world with 250 years, 10 civilizations and 4 megabeasts
- Medium, a 127x127 world with 550 years, 10 civilizations and 4 megabeasts
- Large, a 257x257 world with 550 years, 40 civilizations and 10 megabeasts
DFMark outputs the time to run any given test, so this is what we use for the output. We loop the small test for as many times possible in 10 minutes, the medium test for as many times in 30 minutes, and the large test for as many times in an hour.
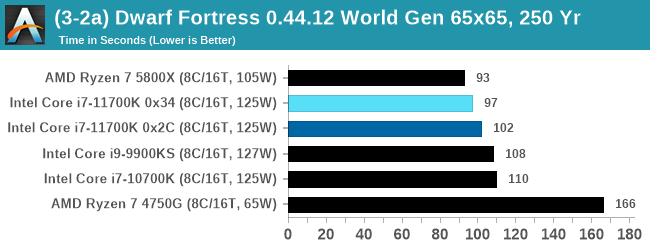
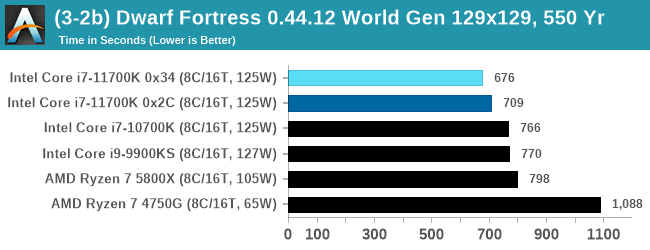
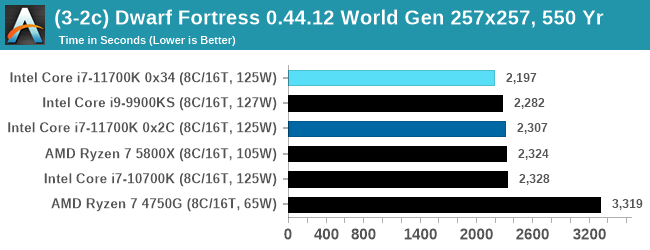
With the small worlds, the 11700K gets a small boost over previous Intel hardware, but this evens out as the worlds get bigger.
Dolphin v5.0 Emulation: Link
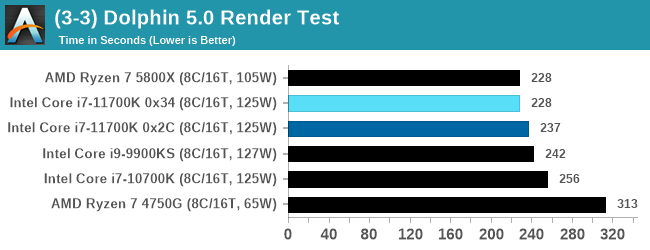
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in seconds, where the Wii itself scores 1051 seconds.
CPU Tests: Rendering
Rendering tests, compared to others, are often a little more simple to digest and automate. All the tests put out some sort of score or time, usually in an obtainable way that makes it fairly easy to extract. These tests are some of the most strenuous in our list, due to the highly threaded nature of rendering and ray-tracing, and can draw a lot of power. If a system is not properly configured to deal with the thermal requirements of the processor, the rendering benchmarks is where it would show most easily as the frequency drops over a sustained period of time. Most benchmarks in this case are re-run several times, and the key to this is having an appropriate idle/wait time between benchmarks to allow for temperatures to normalize from the last test.
Blender 2.83 LTS: Link
One of the popular tools for rendering is Blender, with it being a public open source project that anyone in the animation industry can get involved in. This extends to conferences, use in films and VR, with a dedicated Blender Institute, and everything you might expect from a professional software package (except perhaps a professional grade support package). With it being open-source, studios can customize it in as many ways as they need to get the results they require. It ends up being a big optimization target for both Intel and AMD in this regard.
For benchmarking purposes, we fell back to one rendering a frame from a detailed project. Most reviews, as we have done in the past, focus on one of the classic Blender renders, known as BMW_27. It can take anywhere from a few minutes to almost an hour on a regular system. However now that Blender has moved onto a Long Term Support model (LTS) with the latest 2.83 release, we decided to go for something different.

We use this scene, called PartyTug at 6AM by Ian Hubert, which is the official image of Blender 2.83. It is 44.3 MB in size, and uses some of the more modern compute properties of Blender. As it is more complex than the BMW scene, but uses different aspects of the compute model, time to process is roughly similar to before. We loop the scene for at least 10 minutes, taking the average time of the completions taken. Blender offers a command-line tool for batch commands, and we redirect the output into a text file.
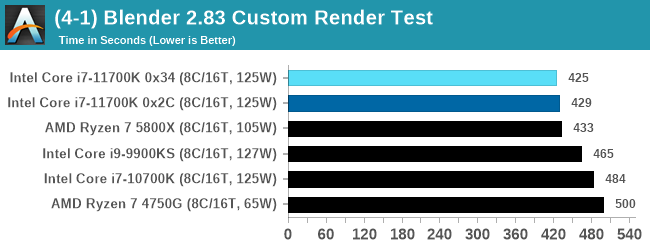
A marginal win for Intel in Blender is a good result, as well as a few % points over the 5.0 GHz 9900KS.
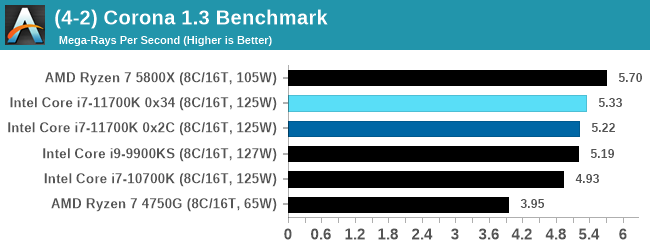
Corona 1.3: Link
Corona is billed as a popular high-performance photorealistic rendering engine for 3ds Max, with development for Cinema 4D support as well. In order to promote the software, the developers produced a downloadable benchmark on the 1.3 version of the software, with a ray-traced scene involving a military vehicle and a lot of foliage. The software does multiple passes, calculating the scene, geometry, preconditioning and rendering, with performance measured in the time to finish the benchmark (the official metric used on their website) or in rays per second (the metric we use to offer a more linear scale).
The standard benchmark provided by Corona is interface driven: the scene is calculated and displayed in front of the user, with the ability to upload the result to their online database. We got in contact with the developers, who provided us with a non-interface version that allowed for command-line entry and retrieval of the results very easily. We loop around the benchmark five times, waiting 60 seconds between each, and taking an overall average. The time to run this benchmark can be around 10 minutes on a Core i9, up to over an hour on a quad-core 2014 AMD processor or dual-core Pentium.
Crysis CPU-Only Gameplay
One of the most oft used memes in computer gaming is ‘Can It Run Crysis?’. The original 2007 game, built in the Crytek engine by Crytek, was heralded as a computationally complex title for the hardware at the time and several years after, suggesting that a user needed graphics hardware from the future in order to run it. Fast forward over a decade, and the game runs fairly easily on modern GPUs.
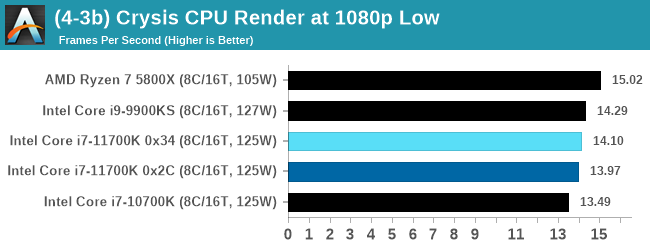
But can we also apply the same concept to pure CPU rendering? Can a CPU, on its own, render Crysis? Since 64 core processors entered the market, one can dream. So we built a benchmark to see whether the hardware can.
For this test, we’re running Crysis’ own GPU benchmark, but in CPU render mode. This is a 2000 frame test, with medium and low settings.
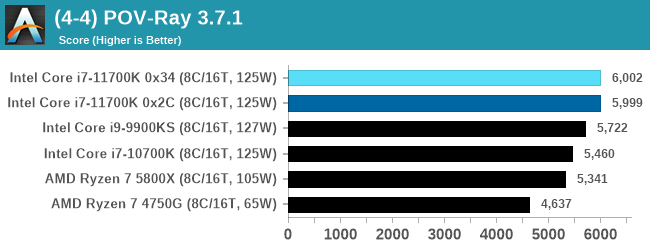
POV-Ray 3.7.1: Link
A long time benchmark staple, POV-Ray is another rendering program that is well known to load up every single thread in a system, regardless of cache and memory levels. After a long period of POV-Ray 3.7 being the latest official release, when AMD launched Ryzen the POV-Ray codebase suddenly saw a range of activity from both AMD and Intel, knowing that the software (with the built-in benchmark) would be an optimization tool for the hardware.
We had to stick a flag in the sand when it came to selecting the version that was fair to both AMD and Intel, and still relevant to end-users. Version 3.7.1 fixes a significant bug in the early 2017 code that was advised against in both Intel and AMD manuals regarding to write-after-read, leading to a nice performance boost.

The benchmark can take over 20 minutes on a slow system with few cores, or around a minute or two on a fast system, or seconds with a dual high-core count EPYC. Because POV-Ray draws a large amount of power and current, it is important to make sure the cooling is sufficient here and the system stays in its high-power state. Using a motherboard with a poor power-delivery and low airflow could create an issue that won’t be obvious in some CPU positioning if the power limit only causes a 100 MHz drop as it changes P-states.
V-Ray: Link
We have a couple of renderers and ray tracers in our suite already, however V-Ray’s benchmark came through for a requested benchmark enough for us to roll it into our suite. Built by ChaosGroup, V-Ray is a 3D rendering package compatible with a number of popular commercial imaging applications, such as 3ds Max, Maya, Undreal, Cinema 4D, and Blender.

We run the standard standalone benchmark application, but in an automated fashion to pull out the result in the form of kilosamples/second. We run the test six times and take an average of the valid results.
Cinebench R20: Link
Another common stable of a benchmark suite is Cinebench. Based on Cinema4D, Cinebench is a purpose built benchmark machine that renders a scene with both single and multi-threaded options. The scene is identical in both cases. The R20 version means that it targets Cinema 4D R20, a slightly older version of the software which is currently on version R21. Cinebench R20 was launched given that the R15 version had been out a long time, and despite the difference between the benchmark and the latest version of the software on which it is based, Cinebench results are often quoted a lot in marketing materials.
Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code bath. The results are output as a score from the software, which is directly proportional to the time taken. Using the benchmark flags for single CPU and multi-CPU workloads, we run the software from the command line which opens the test, runs it, and dumps the result into the console which is redirected to a text file. The test is repeated for a minimum of 10 minutes for both ST and MT, and then the runs averaged.
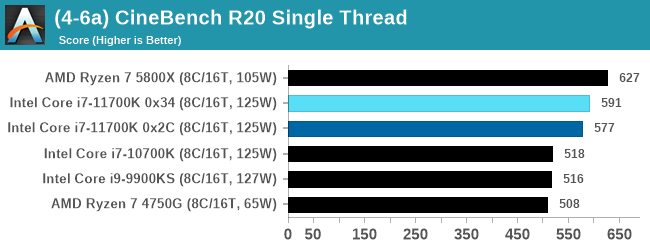
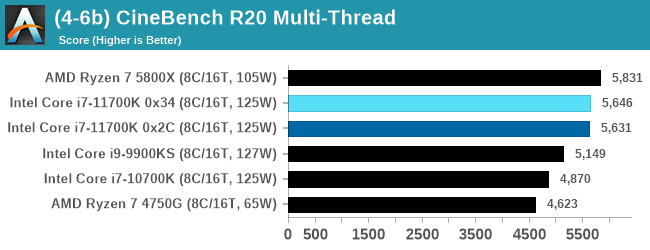
The improvement in Cinebench R20 is a good measure over previous generations of Intel. However mobile Tiger Lake scores 593 at 28 W, still ahead of the 11700K, and they are all behind AMD.








541 Comments
View All Comments
blppt - Saturday, March 13, 2021 - link
Not really---the Bulldozer design had far more problems than just the inadequate Windows scheduler---while "optimized" linux kernels gave better performance, the true issue with Bulldozer was that you had 8 relatively weak cores versus 4 strong cores from Intel, and at the time, coders were still struggling to optimize for anything over 2 cores.In a sense, the designers of Bulldozer REALLY misread the timeline of highly multithreaded coding taking over the market. Heck, even if it was released now alongside the equivalent Core 2 quads, it would still stink for the majority of users, because no game gets any significant advantage of 4+ physical cores even today---and most games still value high single thread/core performance.
Oxford Guy - Sunday, March 28, 2021 - link
'the true issue with Bulldozer was that you had 8 relatively weak cores versus 4 strong cores from Intel, and at the time, coders were still struggling to optimize for anything over 2 cores. In a sense, the designers of Bulldozer REALLY misread the timeline of highly multithreaded coding taking over the market.'My guess is that AMD designed Bulldozer for the enterprise market and didn't want to invest in an additional design more suited to the consumer desktop space. Instead, its additional design priority was the console scam (Jaguar). While that was a good move for AMD it wasn't beneficial for consumers, as consoles are a parasitic redundancy.
One thing many ignore is that Piledriver supercomputers occupied quite high spots in the world performance lists. Mostly that was due to the majority of their work being done by the GPUs, though. Even the original Bulldozer, in Opteron branding, was used in some.
The cheapness of Piledriver chips was also probably a factor in the adoption of the design for supercomputers. Turn down the voltage/wattage so that you're in the efficient part of the improved 32nm SOI node and rely almost completely on heavily threaded code when not running GPU-specific code... and voila — you have an alternative to the monopoly-priced Intel stuff.
But, on the desktop, Piledriver was a bad joke. That's because of its very poor single-thread performance mainly. Not everything can be multi-threaded and even if it is that can mean a speed regression sometimes. The slowness of the L3, the lack of enough operations caching... the design wasn't even all that optimized for multi-thread performance — especially FPU stuff. The cores were very deeply pipelined, designed to use very high clocks. They were not efficient with avoiding bubbles and such. I read that AMD relied too heavily on automated tools due to cost sensitivity.
My vague understanding of the design is that it was narrow and deep like the Pentium 4. Why AMD tried NetBurst 2.0 is beyond me. Even for the enterprise market it's a bad move because power efficiency is important there, especially with servers (rather than supercomputers which, I think, were more tolerant of high power usage – in terms of acceptable design requirements). Even turning down the clocks/voltage to get the best efficiency from the node doesn't fix the issue of the pipelining inefficiency (although hand-tuned code used for some enterprise/scientific stuff would mask that weakness more than general-purpose consumer-grade apps would).
usiname - Monday, March 8, 2021 - link
Intel know very well that is mistake, but alder lake's big cores are not much better in term of power consumption and 10nm quality wafers so their only choice is to keep the production of max 8 core mainstream. This is bad for them, because even 3 years after AMD show 16 core mainstream they can't and as our very well known Intel they will cheat by introduce their 16 core cpu with 8 fake cores. Even more, when they introduce their "super duper" 12900k with 16 cores they will set price higher than every amd main stream and this is triple win, cheap 8 core cpu for manufacturing, better binned with higher clocks and on price of $800-1000. If you think intel trying to do something new and innovative you are wrong.GeoffreyA - Monday, March 8, 2021 - link
You may well turn out to be right about 16 cores having 8 junk ones, and knowing Intel, that's how they operate, with smoke and mirrors when they can't compete properly.Hifihedgehog - Tuesday, March 9, 2021 - link
The irony here is how Intel used to give ARM smack for having inferior single core performance while they were surpassed in multicore by the likes of Qualcomm. I believe—paraphrasing—what they would say is not all cores are created equal. Well, it looks like Intel is trying to look like they are maintaining parity when they are really just giving us mostly crappy cores that can’t perform well at all.GeoffreyA - Tuesday, March 9, 2021 - link
Also, as others have pointed out before, the nomenclature is just there to obfuscate the whole picture. Not knowing anything much about Alder Lake, I did some searching and saw that it's Golden Cove + Gracemont. Wondering what exactly GC was, I searched a little but couldn't find the answer, so I'll guess it's just Sunny Cove with a new name stuck on.Bagheera - Monday, March 8, 2021 - link
the more I read about Intel's 10nm (check relevant articles on SemiWiki and Semi accurate), the more I feel ADL is designed as a workaround for the power/thermal limitations of their 10nm process, instead of being some sort of revelation for next gen performance.Note how TGL remains Intel's only viable product on 10nm at the moment, with Ice Lake SP now two years late. I think Intel knows their 10nm may never be ready for desktop parts, so ADL is a way to have a desktop product on 10nm except not really (it's more akin to a mobile part).
It will probably do fine for gaming, but highly doubtful it will be a meaningful competition to Zen 4 for the prosumer space.
blppt - Monday, March 8, 2021 - link
Bulldozer/Piledriver were a dumb design because they relied HEAVILY on highly-threaded applications to achieve their performance. Almost none of which existed in the late 2000s when they launched. Single thread/core performance was absolutely pathetic compared to Intel's offerings at the time (Sandy Bridge and on).Zan Lynx - Sunday, March 14, 2021 - link
And yet here we are today with 8 cores in game consoles and AMD's Mantle API being the basis of both DirectX 12 and Vulkan. Multicore was always the future and it was obvious even in 2003.blppt - Monday, March 15, 2021 - link
"And yet here we are today with 8 cores in game consoles and AMD's Mantle API being the basis of both DirectX 12 and Vulkan. Multicore was always the future and it was obvious even in 200"You're missing the point. Even TODAY, few (if any) games gain an advantage of more than 4 physical cores + 4 Virtual. It is still, to this day, far more advantageous for games to have 4 strong physical cores than 8 weak ones. The latter was Bulldozer.
Never mind back in 2011/2012.