AMD 3rd Gen EPYC Milan Review: A Peak vs Per Core Performance Balance
by Dr. Ian Cutress & Andrei Frumusanu on March 15, 2021 11:00 AM ESTDisclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
SPEC - Per-Core Win for "F"-Series 75F3
A metric that is actually more interesting than isolated single-thread performance, is actually per-thread performance in a fully loaded system. This actually is a measurement and benchmark figure that would greatly interest enterprises and customers which are running software or workloads that are possibly licensed on a per-core basis, or simply workloads that require a certain level of per-thread service level agreement in terms of performance.
It’s precisely this market that AMD is trying to target with its new “F”-series of processors, and this is where the new 75F3 comes into play. With 32 cores, 4 cores per chiplet with the full 256MB of L3 cache, and a base frequency of 2.95GHz, boosting up to 4.0GHz at a default 280W TDP, is the chip is squeezing out the maximum per-core performance while still offering a massive amount of multi-threaded performance.
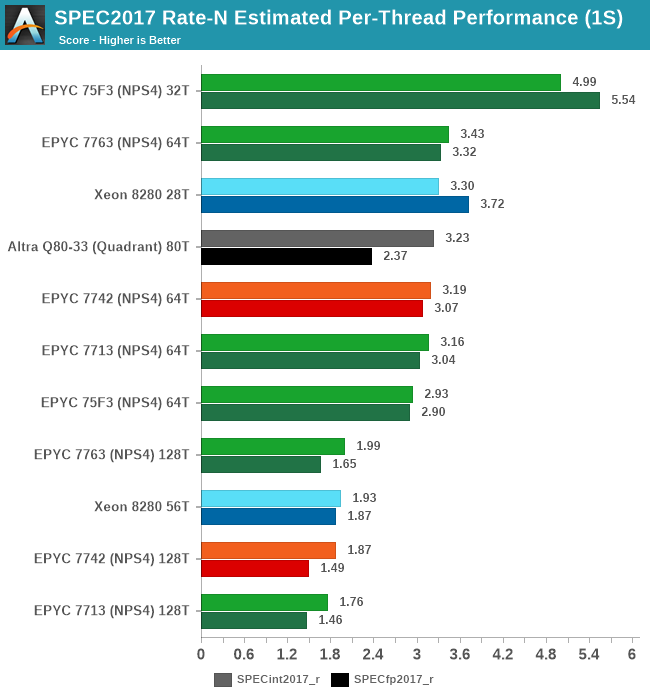
At full load, this ends up with a massive per-thread performance leadership on the part of the 75F3, landing 45% ahead of the 7763 and 51% ahead of the Intel Xeon 8280.
It’s to be noted that limiting the thread count of the higher core-count SKUs will also result in a better per-thread performance metric, for example running a 7713 with only 32 threads will result in a SPECint2017 estimated score of 4.30 – the 75F3 still has a 16% advantage there even though its boost clock is only 8.8% higher at the peak – meaning the 75F3 is achieving higher effective frequencies. Unfortunately, we didn’t have enough time to do the same experiment on the equal 280W 7763 part.
AMD discloses that the biggest generational gains for the Milan stack is found in the lower core-count models, where for example the 7313 and the 7343 outperforms the 7282 and 7302 by 25%. Reason for this is that for example the new 7313 features double the L3 cache, and all the new CPUs are boosting higher with respectively higher TDPs, increasing to 150/190W from 120/155W, as well as landing in at +50% higher price points when comparing generation to generation.








120 Comments
View All Comments
aryonoco - Tuesday, March 16, 2021 - link
Thanks for the excellent article Andrei and Ian. Really appreciate your work.Just wondering, is Johan no longer inlvolved in server reviews? I'll really miss him.
Andrei Frumusanu - Saturday, March 20, 2021 - link
Johan is no longer part of AT.SanX - Tuesday, March 16, 2021 - link
In summary, the difference in performance 9 vs 8 for (Milan vs Rome) means they are EQUAL. Not a single specific application which shows more than that. So much for the many months of hype and blahblah.tyger11 - Tuesday, March 16, 2021 - link
Okay, now give us the new Zen 3 Threadripper Pro!AusMatt - Wednesday, March 17, 2021 - link
Page 4 text: "a 255 x 255 matrix" should read: "a 256 x 256 matrix".hmw - Friday, March 19, 2021 - link
What was the stepping for the Milan CPUs? B0? or B1?mkbosmans - Saturday, March 20, 2021 - link
These inter-core synchronisation latency plots are slightly misleading, or at least not representative of "real software". By fixing the cache line that is used to the first core in the system and then ping-ponging it between to other cores you do not measure core-core latency, but rather core-to-cacheline-to-core, as expressed in the article. This is not how inter-thread communication usually works (in well-designed software).Allocating the cache line on the memory local to one of the ping-pong threads would make the plot more informative (although a bit more boring).
mode_13h - Saturday, March 20, 2021 - link
Are you saying a single memory address is used for all combinations of core x core?Ultimately, I wonder if it makes any difference which NUMA domain the address is in, for a benchmark like this. Once it's in L1 cache, that's what you're measuring, no matter the physical memory address.
Also, I take issue with the suggestion that core-to-core communication necessarily involves memory in one of the core's NUMA domains. A lot of cases where real-world software is impacted by core-to-core latency involves global mutexes and atomic counters that won't necesarily be local to either core.
mkbosmans - Saturday, March 20, 2021 - link
Yes, otherwise the SE quadrant (socket 2 to socket 2 communication) would look identical to the NW quadrant, right?It does matter on which NUMA node the address is in, this is exactly what is addressed later in the article about Xeon having a better cache coherency protocol where this is less of an issue.
From the software side, I was more thinking of HPC applications where a situation of threads exchanging data that is owned by one of them is the norm, e.g. using OpenMP or MPI. That is indeed a different situation from contention on global mutexes.
mode_13h - Saturday, March 20, 2021 - link
How often is MPI used for communication *within* a shared-memory domain? I tend to think of it almost exclusively as a solution for inter-node communication.