AMD Ryzen 9 5980HS Cezanne Review: Ryzen 5000 Mobile Tested
by Dr. Ian Cutress on January 26, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- Vega
- Ryzen
- Zen 3
- Renoir
- Notebook
- Ryzen 9 5980HS
- Ryzen 5000 Mobile
- Cezanne
CPU Tests: Synthetic and SPEC
Most of the people in our industry have a love/hate relationship when it comes to synthetic tests. On the one hand, they’re often good for quick summaries of performance and are easy to use, but most of the time the tests aren’t related to any real software. Synthetic tests are often very good at burrowing down to a specific set of instructions and maximizing the performance out of those. Due to requests from a number of our readers, we have the following synthetic tests.
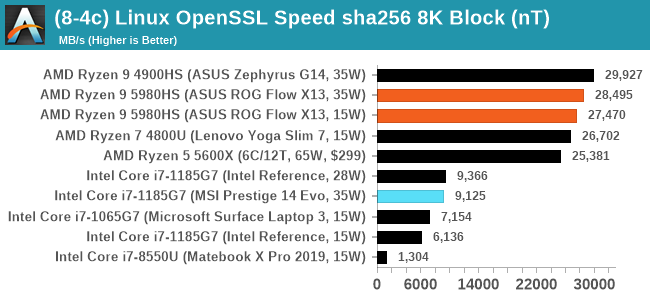
Linux OpenSSL Speed: SHA256
One of our readers reached out in early 2020 and stated that he was interested in looking at OpenSSL hashing rates in Linux. Luckily OpenSSL in Linux has a function called ‘speed’ that allows the user to determine how fast the system is for any given hashing algorithm, as well as signing and verifying messages.
OpenSSL offers a lot of algorithms to choose from, and based on a quick Twitter poll, we narrowed it down to the following:
- rsa2048 sign and rsa2048 verify
- sha256 at 8K block size
- md5 at 8K block size
For each of these tests, we run them in single thread and multithreaded mode. All the graphs are in our benchmark database, Bench, and we use the sha256 results in published reviews.

GeekBench 5: Link
As a common tool for cross-platform testing between mobile, PC, and Mac, GeekBench is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
Unfortunately we are not going to include the Intel GB5 results in this review, although you can find them inside our benchmark database. The reason behind this is down to AVX512 acceleration of GB5's AES test - this causes a substantial performance difference in single threaded workloads that thus sub-test completely skews any of Intel's results to the point of literal absurdity. AES is not that important of a real-world workload, so the fact that it obscures the rest of GB5's subtests makes overall score comparisons to Intel CPUs with AVX512 installed irrelevant to draw any conclusions. This is also important for future comparisons of Intel CPUs, such as Rocket Lake, which will have AVX512 installed. Users should ask to see the sub-test scores, or a version of GB5 where the AES test is removed.

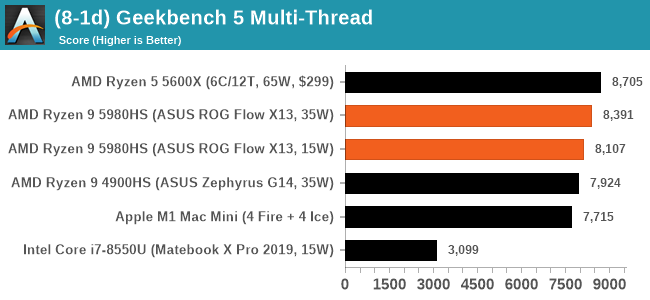
To clarify the point on AES. The Core i9-10900K scores 1878 in the AES test, while 1185G7 scores 4149. While we're not necessarily against the use of accelerators especially given that the future is going to be based on how many and how efficient these accelerators work (we can argue whether AVX-512 is efficient compared to dedicated silicon), the issue stems from a combi-test like GeekBench in which it condenses several different (around 20) tests into a single number from which conclusions are meant to be drawn. If one test gets accelerated enough to skew the end result, then rather than being a representation of a set of tests, that one single test becomes the conclusion at the behest of the others, and it's at that point the test should be removed and put on its own. GeekBench 4 had memory tests that were removed for Geekbench 5 for similar reasons, and should there be a sixth GeekBench iteraction, our recommendation is that the cryptography is removed for similar reasons. There are 100s of cryptography algorithms to optimize for, but in the event where a popular tests focuses on a single algorithm, that then becomes an optimization target and becomes meaningless when the broader ecosystem overwhelmingly uses other cryptography algorithms.
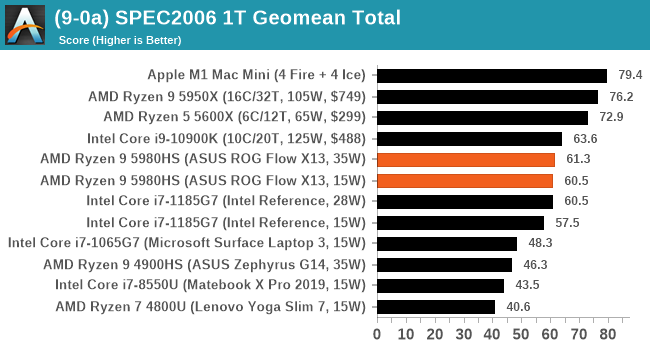
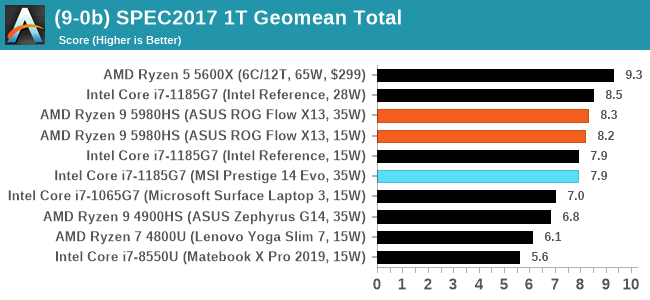
CPU Tests: SPEC
SPEC2017 and SPEC2006 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by our own Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing is good enough. SPEC2006 is deprecated in favor of 2017, but remains an interesting comparison point in our data. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates from our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark. All of the major vendors, AMD, Intel, and Arm, all support the way in which we are testing SPEC.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
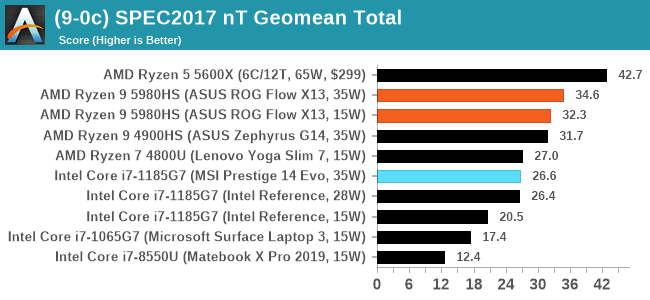
For each of the SPEC targets we are doing, SPEC2006 rate-1, SPEC2017 speed-1, and SPEC2017 speed-N, rather than publish all the separate test data in our reviews, we are going to condense it down into a few interesting data points. The full per-test values are in our benchmark database.








218 Comments
View All Comments
Smell This - Tuesday, January 26, 2021 - link
LOL @ ZoZo ___ he is messin' with you, ts
You are correct in that Dr Su and AMD has played yet another "Rope-A-Dope" on the competition. I suspect RDNA2/Navi II will raise its pretty head after the "Lexa" cores run their course. It has been a productive run.
There are Radeon pro CNDA1 cores floating around that will likely evolve into the RX 6500 RDNA2/Navi IIs discreet replacements for Lexa. These will be the Display Core Next: 3.0 // Video Core Next: 3.0 arch associated with the Big Navi.
And ... I don't think AMD is being lazy. I think the Zen2/Zen3 APU product stack is being developed as yet to be revealed. Home / Office / Creator ? There is a Radeon Pro Mac Navi Mobile with RDNA1 discreet video w/HBM2.
We will see how the 6xxx APUs evolve. Grab your popcorn!
TelstarTOS - Tuesday, January 26, 2021 - link
lazy, definitely lazy.vortmax2 - Saturday, January 30, 2021 - link
One sees lazy, another sees smart business decision.samal90 - Friday, February 12, 2021 - link
The APU in 2022 will use RDNA 2 finally. Expect a substantial GPU performance lift next year with the new Rembrandt chip.Spunjji - Thursday, January 28, 2021 - link
A console APU is not a PC APU - they have completely different design constraints and memory architectures. Vega was used here because it allowed AMD to bring Zen 3 APUs to market faster than they managed with Zen 2 - it's all mentioned in the review that you're commenting on......sandeep_r_89 - Friday, January 29, 2021 - link
The consoles don't use iGPUs.......most likely, RDNA2 design so far hasn't been designed for low power usage, it's focused more on high performance. Once they do the work to create a low power version, it can appear in iGPUs, laptop dGPUs, low end desktop dGPUs etc.Netmsm - Tuesday, January 26, 2021 - link
any hope for Intel?Deicidium369 - Wednesday, January 27, 2021 - link
LOL. Any hope for AMD?Releases Zen 3, RDNA2 and consoles - and only grows revenue $240M over Q3.... Didn't even gross $10B last year.
Meanwhile Intel posts 5 YEARS of record growth...
Spunjji - Thursday, January 28, 2021 - link
A discussion of a company's technological competitiveness is not a discussion of their financial health. Any dolt knows this, why do you pretend we can't see you moving the goalposts in *every single comment section*?Spunjji - Thursday, January 28, 2021 - link
This post is even more hilarious in the context of AMD's financial disclosure today 😁