AMD Zen 3 Ryzen Deep Dive Review: 5950X, 5900X, 5800X and 5600X Tested
by Dr. Ian Cutress on November 5, 2020 9:01 AM ESTCPU Tests: Synthetic
Most of the people in our industry have a love/hate relationship when it comes to synthetic tests. On the one hand, they’re often good for quick summaries of performance and are easy to use, but most of the time the tests aren’t related to any real software. Synthetic tests are often very good at burrowing down to a specific set of instructions and maximizing the performance out of those. Due to requests from a number of our readers, we have the following synthetic tests.
Linux OpenSSL Speed: SHA256
One of our readers reached out in early 2020 and stated that he was interested in looking at OpenSSL hashing rates in Linux. Luckily OpenSSL in Linux has a function called ‘speed’ that allows the user to determine how fast the system is for any given hashing algorithm, as well as signing and verifying messages.
OpenSSL offers a lot of algorithms to choose from, and based on a quick Twitter poll, we narrowed it down to the following:
- rsa2048 sign and rsa2048 verify
- sha256 at 8K block size
- md5 at 8K block size
For each of these tests, we run them in single thread and multithreaded mode. All the graphs are in our benchmark database, Bench, and we use the sha256 and md5 results in published reviews.




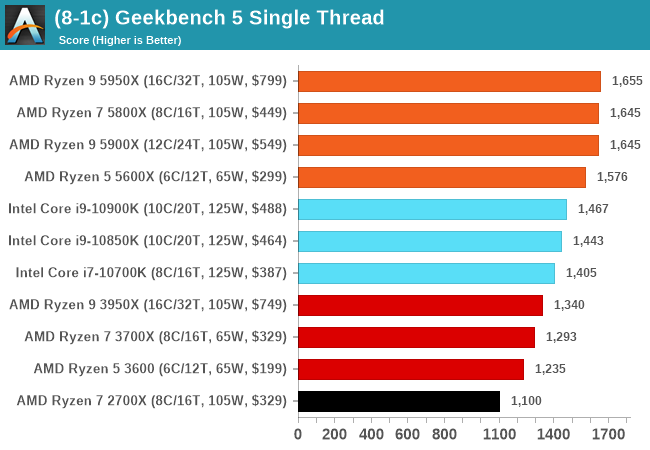
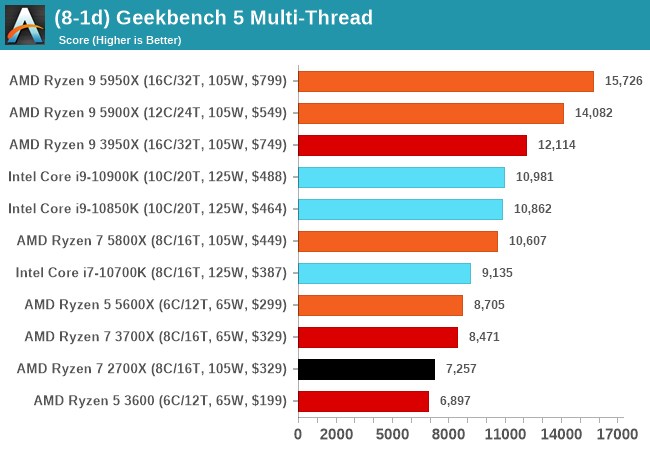
GeekBench 5: Link
As a common tool for cross-platform testing between mobile, PC, and Mac, GeekBench is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic, and a lot of users often put a lot of weight behind the test due to the fact that it is compiled across different platforms (although with different compilers).
We have both GB5 and GB4 results in our benchmark database. GB5 was introduced to our test suite after already having tested ~25 CPUs, and so the results are a little sporadic by comparison. These spots will be filled in when we retest any of the CPUs.








339 Comments
View All Comments
Orkiton - Thursday, November 5, 2020 - link
Please Anandtech, up ryzen and up epic your servers, it's ages here to load a page...PrionDX - Thursday, November 5, 2020 - link
Mmm nice warm code bath, very relaxing> Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code bath.
prophet001 - Thursday, November 5, 2020 - link
How you gonna test FFXIV and not WoW.-______________-
Mr Perfect - Thursday, November 5, 2020 - link
Guys, could you please define acronyms the first time they are used in an article? Take page three for example, it touches on a BTB, TAGE and ITA, but only ITA is defined. I have no idea what a BTB or TAGE is. If they where defined on page two and I missed them, feel free to ignore me.name99 - Saturday, November 7, 2020 - link
BTB= Branch Target Buffer. Holds the addresses where a branch will go if it taken.TAGE= (tagged geometric something-or-other) name is not important; what matters is that it's currently the most accurate known branch predictor. Comes in a few variants, was 1st published around 2007 by Andre Seznec who has since gone on to show how it can be used for damn well everything! (Value prediction, indirect branch, prefetching, washing windows, you name it.)
Apple seems to have been first to implement, maybe as early as the A7, certainly very soon in the A series.
Now everybody uses it, but only in the last year or so has everyone really got on board. (Actually to be precise Seznec suggested that Intel is using TAGE based on their performance characteristics, but I don't think Intel have confirmed this. And ARM probably are but again unconfirmed. IBM is confirmed, and now AMD.)
Even if you know the basic algorithm for direction prediction is TAGE, that still doesn't make everyone equal. There are MANY extra aspects where everyone is different. The most obvious is how much storage is given to the branch predictor, but other less obvious aspects include
- how do you predict indirect branches? State of the art is ITTAGE, but that doesn't mean everyone is using it.
- how do you update your branch prediction storage (ie how fast do corrections get from the backend into the predicting mechanism at the front end)
- how do you implement your L2 storage and second-stage prediction?
- what extra "specialist" predictors do you have? (These are things like special-case predictors for loops.)
quantcon - Thursday, November 5, 2020 - link
Yeah, it's actually kinda nuts, considering Intel convinced us years ago that we've hit the point of diminishing returns and there are hardly any IPC improvements to be had.Spunjji - Sunday, November 8, 2020 - link
Seems like they needed to believe that...DanD85 - Thursday, November 5, 2020 - link
This just goes on to prove yet again how crucial a healthy competition benefits everyone. Intel has been stagnating for more than a decade. Imagine where we would have been performance-wise if we had got this ~40% increase every 3 years. Intel only have themselves to blame. They are the chipzillla, the gatekeeper and the choker of the whole industry!lmcd - Monday, November 9, 2020 - link
40% is a bit disingenuous. Most of the gap in desktop is chiplet design. Notice how mobile, while AMD-favored, is still competitive? It's just a bad bet from Intel going with stacked packaging before same-package flat chiplet, and the packaging techniques for both are very new. There aren't 40% improvements on the table going forward, Bulldozer and Piledriver were both just awful and AMD didn't ever release full desktop Steamroller or Excavator (which were fine, not great). Zen 1 left a lot on the table for such a big increase as well.GeoffreyA - Tuesday, November 10, 2020 - link
If you place Zen at Haswell's level, it took AMD three years to reach Zen 3 (from the consumer's point of view). On Intel's side, it's taken six years to go from Haswell to Sunny Cove.Even in the early tick-tock days, when more massive changes could be put in, it was usually two years apart for microarchitecture: Core (2006), Nehalem (2008), Sandy Bridge (2010/11), etc.
Whether there's a lot more juice in the tank for Zen remains to be seen. In my opinion I think there is: Z3's out-of-order structures are still quite conservative, compared to Sunny Cove, which it beats, so there's possibility of more widening there. I also think their split scheduler design, inherited from the Athlon, will allow them to scale more easily. Of course, I know the engineers in Haifa must be cooking up something potent too. Either way, exciting stuff.