Imagination Announces B-Series GPU IP: Scaling up with Multi-GPU
by Andrei Frumusanu on October 13, 2020 4:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- SoCs
- IP
Introducing IMGIC - A better frame-buffer compression
Besides the multi-GPU scalability, another big feature introduction to the B-Series is the addition of a completely new image compression algorithm, simply dubbed IMGIC, or Imagination Image Compression.
Compression is an integral part of modern GPUs as otherwise the designs would simply be memory bandwidth starved. To date, Imagination has been using PVRIC to achieve this. The problem with PVRIC was that it was a relatively uncompetitive compression format, falling behind in data compression ratio compared to other competitor techniques such as Arm’s AFBC (Arm Frame-Buffer Compression). This resulted in IMG GPUs using up more bandwidth than a comparable Arm GPU.


IMGIC is a completely new and redesigned compression algorithm that replaces PVRIC. Imagination touts this as the most advanced image compression technology, offering extreme bandwidth savings and a lot more flexibility compared to previous PVRIC designs. Amongst the flexibility aspect of things, IMGIC can now work on individual pixels instead of just smaller tiles or pixel groups.
Furthermore, the new algorithm is said to be 8x simpler than PVRIC, meaning the hardware implementation is also much simplified and achieves a significant are area reduction.
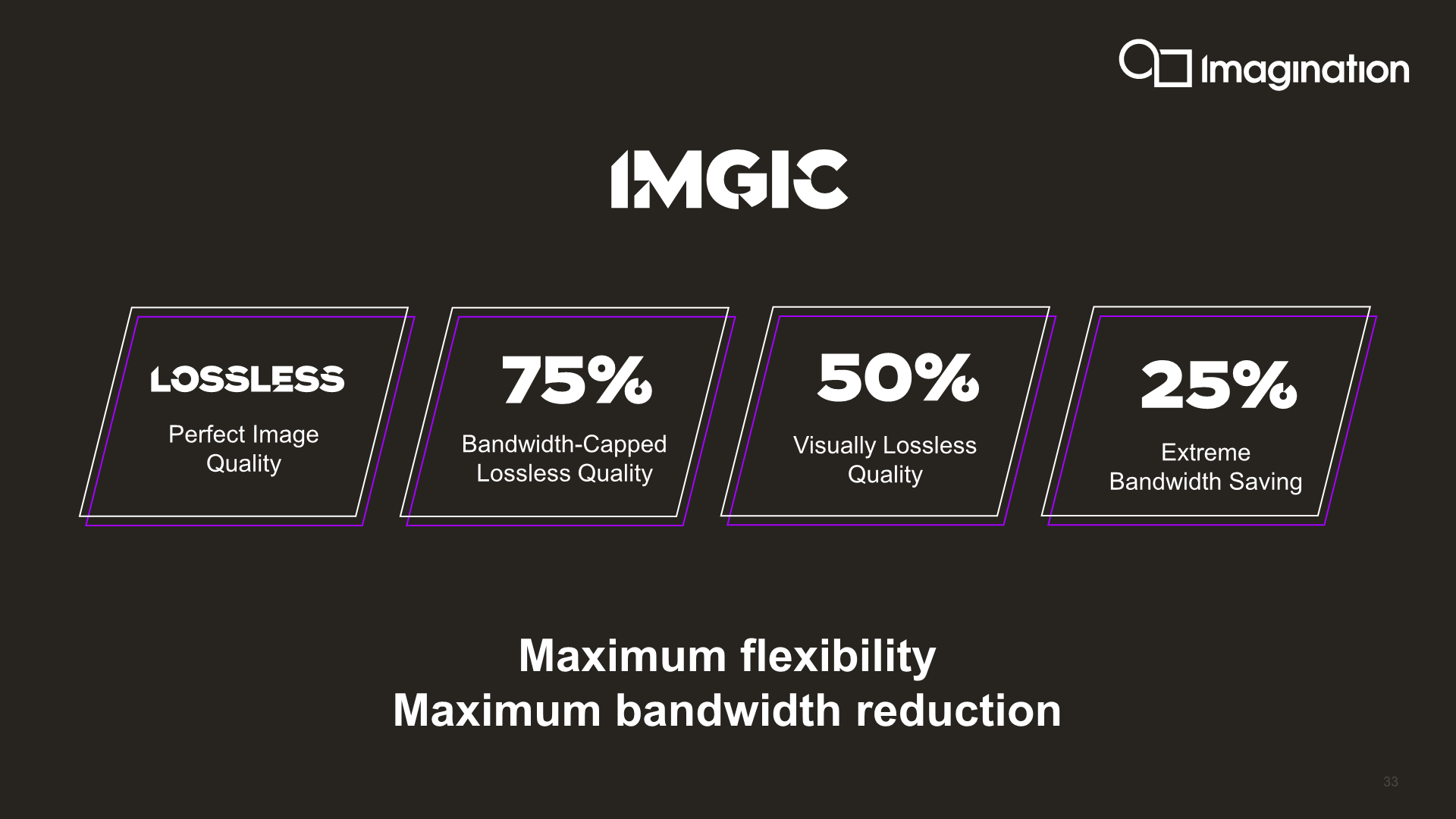
The new implementation gives vendors more scaling options, adding compression ratios down to a lossy 25% for extreme bandwidth savings. SoC vendors can use this to alleviate bandwidth starved scenarios or QoS scenarios where other IPs on the SoC should take priority.

Overall, the B-Series now offers a 35% reduction in bandwidth compared to the A-Series and previous generation Imagination GPU architectures, which is a rather large improvement given that memory bandwidth is a costly matter, both in terms of actual silicon cost as well as energy usage.








74 Comments
View All Comments
tkSteveFOX - Wednesday, October 14, 2020 - link
I don't think those sub $100 GPUs can beat the integrated graphics. They are there for office stations to support 3-4 monitors, nothing more.Mat3 - Wednesday, October 14, 2020 - link
The TBDR architecture has always allowed for efficient multi-core solutions, since they bin all the triangles before rasterization and work then tile by tile. Each core can work on different tiles. IMG has been touting this benefit for literally decades already, I'm not sure what is so different here. The Naomi 2 arcade board from over 20 years ago is a simple implementation of this.The other concern for scaling it up to high-end desktop levels is always the same; the number of triangles that would need to be binned for a modern a desktop game is much, much higher than a mobile game.
myownfriend - Wednesday, October 14, 2020 - link
I never understood why the polygon counts are considered an issue for TBRs.I know GPUs like the RTX 3080 have peak primitives counts of about 10.2 billion with boost clocks but I'm pretty sure actual game triangle counts never really get that high. If you divide that by 60 fps then we're looking at a peak of about 170 million per frame with a current target resolution of Ultra HD which is 8,294,400 pixels. Even accounting for back-facing and overlapping geometry, do any games really have 20 times more primitives than rendered pixels?
supdawgwtfd - Thursday, October 15, 2020 - link
"into different work tiles that can then the other “slave” GPUs can pull from in order to work on"My brain exploded from trying to read this...
Seriously. Get a damn editor or even a basic proof reader!