The Armari Magnetar X64T Workstation OC Review: 128 Threads at 4.0 GHz, Sustained!
by Dr. Ian Cutress on September 9, 2020 12:00 PM EST- Posted in
- Desktop
- Systems
- AMD
- OC Systems
- ThreadRipper
- 3990X
- Armari
- Magnetar
- X64T
- Rendering
Science and Simulation Performance
Beyond rendering workloads, we also have a number of key math-heavy specific workloads that systems like the Magnetar X64T were designed for.
AES Encoding
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.

Our test here has a limit of only using 64 threads, which the X64T takes to full effect applying maximum frequency across all the cores.
Agisoft Photoscan 1.3.3: link
Photoscan stays in our benchmark suite from the previous benchmark scripts, but is updated to the 1.3.3 Pro version. As this benchmark has evolved, features such as Speed Shift or XFR on the latest processors come into play as it has many segments in a variable threaded workload.
The concept of Photoscan is about translating many 2D images into a 3D model - so the more detailed the images, and the more you have, the better the final 3D model in both spatial accuracy and texturing accuracy. The algorithm has four stages, with some parts of the stages being single-threaded and others multi-threaded, along with some cache/memory dependency in there as well. For some of the more variable threaded workload, features such as Speed Shift and XFR will be able to take advantage of CPU stalls or downtime, giving sizeable speedups on newer microarchitectures.

For the update to version 1.3.3, the Agisoft software now supports command line operation. Agisoft provided us with a set of new images for this version of the test, and a python script to run it. We’ve modified the script slightly by changing some quality settings for the sake of the benchmark suite length, as well as adjusting how the final timing data is recorded. The python script dumps the results file in the format of our choosing. For our test we obtain the time for each stage of the benchmark, as well as the overall time.

Because Photoscan is a more varied workload, the gains from something like this are more niche.
3D Particle Movement v2.1: Non-AVX and AVX2/AVX512
This is the latest version of the benchmark designed to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. This involves randomly moving particles in a 3D space using a set of algorithms that define random movement. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in.
The initial version of v2.1 is a custom C++ binary of my own code, flags are in place to allow for multiple loops of the code with a custom benchmark length. By default this version runs six times and outputs the average score to the console, which we capture with a redirection operator that writes to file.
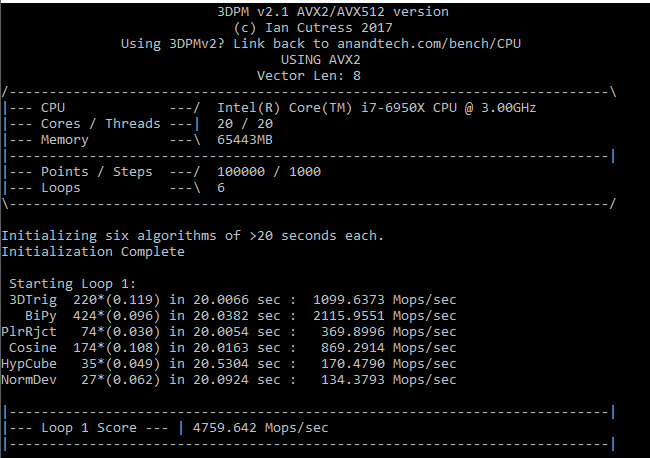
An example run on an i7-6950X
For v2.1, we also have a fully optimized AVX2/AVX512 version, which uses intrinsics to get the best performance out of the software. This was done by a former Intel AVX-512 engineer who now works elsewhere. According to Jim Keller, there are only a couple dozen or so people who understand how to extract the best performance out of a CPU, and this guy is one of them. To keep things honest, AMD also has a copy of the code, but has not proposed any changes.
The 3DPM test is set to output millions of movements per second, rather than time to complete a fixed number of movements. This way the data represented becomes a linear when performance scales and easier to read as a result.

Because the Intel processors have AVX-512, they win here. This is one of the fundamental differences that might put people in the direction of an Intel system, should their code be AVX-512 accelerated. For AVX-2 code paths, the Magnetar gets another 36% lead over the stock processor.
NAMD 2.13 (ApoA1): Molecular Dynamics
One of the popular science fields is modelling the dynamics of proteins. By looking at how the energy of active sites within a large protein structure over time, scientists behind the research can calculate required activation energies for potential interactions. This becomes very important in drug discovery. Molecular dynamics also plays a large role in protein folding, and in understanding what happens when proteins misfold, and what can be done to prevent it. Two of the most popular molecular dynamics packages in use today are NAMD and GROMACS.
NAMD, or Nanoscale Molecular Dynamics, has already been used in extensive Coronavirus research on the Frontier supercomputer. Typical simulations using the package are measured in how many nanoseconds per day can be calculated with the given hardware, and the ApoA1 protein (92,224 atoms) has been the standard model for molecular dynamics simulation.
Luckily the compute can home in on a typical ‘nanoseconds-per-day’ rate after only 60 seconds of simulation, however we stretch that out to 10 minutes to take a more sustained value, as by that time most turbo limits should be surpassed. The simulation itself works with 2 femtosecond timesteps.

NAMD requires a lot more core-to-core communication as well as memory access, and so we reach an asymptotic limit in our test here.
DigiCortex v1.35: link
DigiCortex is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation, similar to a small slug.
The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
I reached out to the author of the software, who has added in several features to make the software conducive to benchmarking. The software comes with a series of batch files for testing, and we run the ‘small 64-bit nogui’ version with a modified command line to allow for ‘benchmark warmup’ and then perform the actual testing.
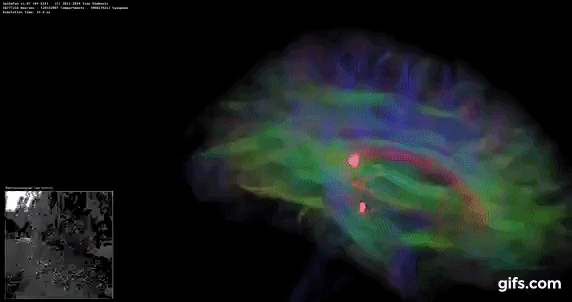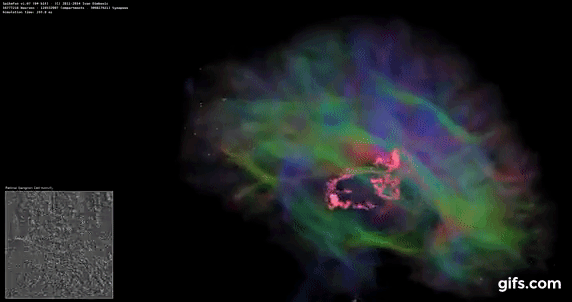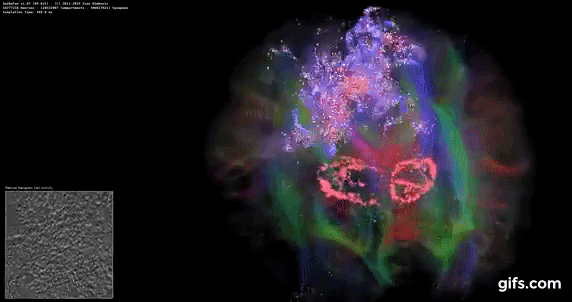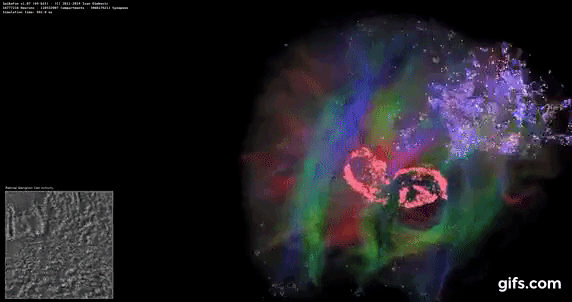
The software originally shipped with a benchmark that recorded the first few cycles and output a result. So while fast multi-threaded processors this made the benchmark last less than a few seconds, slow dual-core processors could be running for almost an hour. There is also the issue of DigiCortex starting with a base neuron/synapse map in ‘off mode’, giving a high result in the first few cycles as none of the nodes are currently active. We found that the performance settles down into a steady state after a while (when the model is actively in use), so we asked the author to allow for a ‘warm-up’ phase and for the benchmark to be the average over a second sample time.
For our test, we give the benchmark 20000 cycles to warm up and then take the data over the next 10000 cycles seconds for the test – on a modern processor this takes 30 seconds and 150 seconds respectively. This is then repeated a minimum of 10 times, with the first three results rejected.
We also have an additional flag on the software to make the benchmark exit when complete (which is not default behavior). The final results are output into a predefined file, which can be parsed for the result. The number of interest for us is the ability to simulate this system in real-time, and results are given as a factor of this: hardware that can simulate double real-time is given the value of 2.0, for example.
The final result is a table that looks like this:

Digicortex is another memory access asymptotic benchmark, however with more focus on the memory and interconnect latency as well. The differences between the X64T we tested and the stock 3990X likely come down to the memory configuration.
SPEC2017rate
For a final benchmark, I want to turn to SPEC. Due to the nature of running SPEC2017 rate with all 128 threads, the run-time for this benchmark is over 16 hours, and so we've had to prioritize other testing to speed up the review process. We only did a single cycle of SPEC2017rate128, however we did score the following:
- Average SPEC2017int rate 128 (estimated): 254.8
- Average SPEC2017fp rate 128 (estimated): 234.0
The full sub-test results are in Bench. We normally showcase the results as a geomean as well, to which the Magnetar X64T scores 164.1, which compared to Intel's 28 core, which scores 111.1.








96 Comments
View All Comments
WaltC - Wednesday, September 9, 2020 - link
Very impressive box!...;) Great write-up, too! Great job, Ian--your steady diet of metal & silicon is really producing obvious positive results! I would definitely want to go with a different motherboard, though. Even the GB x570 Aorus Master has received ECC ram support with the latest bios featuring the latest couple of AGESA's from AMD--so it seems like a shoe-in for a TR motherboard. I agree it's kind of an odd exclusion from AMD for TR. But, I suppose if you want ECC support and lots more ram support you'll need to step up to EPYC and its associated motherboards. This is a real pro-sumer offering and the price--well, everything about it--seems right on the money, imo. I really like the three-year warranty and the included service to change out coolant fluid every three years--very nice! If I used water cooling that is the only kind of fluid I would want to use--some of these el cheapo concoctions will eat up a radiator in a year or less! Enjoyed the article--thanks again...;)Makaveli - Wednesday, September 9, 2020 - link
"Ideally AMD would need a product that pairs the 8-channel + ECC support with a processor overclock."But why?
I maybe wrong here but when you are spending 10k+ on a build isn't stability more important than overclocking?
MenhirMike - Wednesday, September 9, 2020 - link
Overclocking doesn't have to be unstable - and for some workloads, the extra performance is worth the effort to find the limits and beef up the cooling solution.Ian Cutress - Thursday, September 10, 2020 - link
Had a chat with Armari. The system was built with the OC requirements in mind, and customized to support that. They're using a PBO-based overclock as well, and they've been really impressed with how AMD's latest variation of PBO can optimize the DVFS of the chip to keep the system stable regardless of workload (as long as heat is managed). In my testing, there was zero instability. I was told by Armari that they can build 10, 20, or 50 systems in a row without having any stability issues coming from the processor, and that binning the CPU is almost virtually non-existant.Everett F Sargent - Wednesday, September 9, 2020 - link
So, such a waste of power, time and money.Anyone can build TWO 3990X systems for less then half the price AND less then half the power consumption with each of them easily getting ~90% of the benchmarks.
That is with a top of the line titanium PSU, top of the line MB, top of the line 2TB SSD, top of the line Quadro RTX 4000 (oh damn paying 5X for the 6000 for only less then 2X the performance, what a b1tch, not), top of the line ... everything.
So ~1.8X of the total performance at ~1.8X the cost (sale pricing for all components otherwise make that ~1.9X the cost) and ~0.9X of the total power consumption.
But, you say, an ~15KUS system pays for itself, in less then 1E−44 seconds, even. Magnetarded indeed. /:
TallestGargoyle - Thursday, September 10, 2020 - link
That's a pretty disingenuous stance. Yes, you can split the performance across multiple systems, likely for cheaper, but that ignores general infrastructure requirements, like having multiple locations to set up a system in, having enough power outlets to run them all, being capable of splitting the workload across multiple systems.Not every workload can support distributed processing. Not every office has the space for a dedicated rack of systems churning away. Not every workload can sufficiently run on a half-performing GPU, even if the price is only a fifth of the one used here.
If your only metric is price-to-performance, then yes, this isn't the workstation for you. But this clearly isn't hitting a price-to-performance metric. It's focusing on the performance.
Tomatotech - Thursday, September 10, 2020 - link
Something something chickens and oxen.Or was it something something sports cars and 49-ton trucks? I’ll go yell at clouds instead.
Spunjji - Friday, September 11, 2020 - link
Perish the thought that someone might order one of these with a Quadro 4000 and obviate his biggest gripe (not that it would solve the potential problem of fitting a dataset into 8GB of RAM instead of 24GB)Everett F Sargent - Saturday, September 12, 2020 - link
Well there is that 20% VAT that pushes the actual system price to ~$17K US so dividing by two ~$8.5K per system minus the cost of a RTX 4000 at ~1K US gives one ~$6K US sans graphics card (remember I said build two systems with RTX 4000 at ~$7K US).So I have about ~$2.5K per system for a graphics card. Which easily gives one RTX 5000 per build at ~$2K US. Whiich is 2/3 of the RTX 6000.
But, if the GPU benchmarks are all eventually CPU bound, which appears to be the case here in this review, then yes I get two systems at ~$8K US or ~$16K US for two systems, in other words, I get to build a 3900X system for about ~$1K US to boot..
So no, I would rather see benchmarks at 4K, mind you (as these were at standard HD) with different GPU options. Basically, I would want to use my money wisely (assuming at a minimum a 3990X CPU at ~$4K US as the entry point).
Therefore, this review is totally useless to anyone interested in efficiency (which should normally include everyone) and costs (ditto).
TallestGargoyle - Monday, September 14, 2020 - link
That still doesn't take into account the issues I brought up initially with owning and running two systems.