Linux and L2 Cache; Sempron vs. Athlon
by Kristopher Kubicki on August 18, 2004 2:29 AM EST- Posted in
- Linux
John The Ripper
We used John the Ripper (JTR) 1.6.37 as a loose benchmark of encryption/hashing. The 1.6 "stable" branch for JTR is actually very dated, so we used the much more updated 1.6.37 tree instead. There are fewer hand coded ASM routines in the 1.6.37 release which allows us to better directly compare our processors.
Just like the chess benchmarks from before, we used four different configurations to compile JTR. The first configuration is identical to "make linux-x86-any-elf" target.
- Configuration 1.) -O2
- Configuration 2.) -O3
- Configuration 3.) -O2 -march
- Configuration 4.) -O3 -march
Obviously, we used the athlon arch flag for the Athlon XP processor and k8 for the Athlon 64.
![John The Ripper 1.6.37 - DES [24/32 4K]](https://images.anandtech.com/graphs/linux and l2 cache sempron vs _081704110838/3577.png)
![John The Ripper 1.6.37 - Blowfish (x32) [32/64]](https://images.anandtech.com/graphs/linux and l2 cache sempron vs _081704110838/3578.png)
![John The Ripper 1.6.37 - MD5 [32/64 X2]](https://images.anandtech.com/graphs/linux and l2 cache sempron vs _081704110838/3579.png)
It is likely that JTR uses some optimized ASM code for the Athlon XP, which is why we see such good marks for a two year old CPU.
OpenSSL
The most comprehensive OpenSSL "speed" benchmarks can be downloaded as separate text files (Athlon 2200+, Athlon 64 3000+, Sempron 3100+) but we also provided some graphical mappings below.
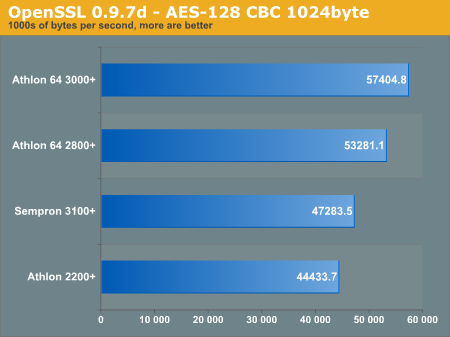
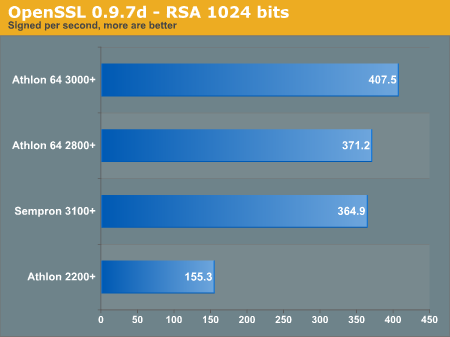
The AES speed test scales very well across AMD's budget computing line, and we really see the additional L2 cache increasing thoroughput. However, we go down one graph to see that signing RSA keys had very little performance increase with the 512KB L2 cache.








59 Comments
View All Comments
KristopherKubicki - Saturday, August 21, 2004 - link
Aces options actually degrade performance on our test machine.Kristopher
KristopherKubicki - Saturday, August 21, 2004 - link
I am not making these up... really.Xeon 3.6GHz EM64T, 1GB DDR2-400, TSCP 1.8.1
=================================================================
linux:~/work/tscp181 # /opt/gcc-mainline/bin/gcc -v
Reading specs from /opt/gcc-mainline/lib64/gcc/x86_64-suse-linux/3.4.1/specs
Configured with: ../configure --enable-threads=posix --prefix=/opt/gcc-mainline --with-local-prefix=/usr/local --infodir=/opt/gcc-mainline/share/info --mandir=/opt/gcc-mainline/share/man --libdir=/opt/gcc-mainline/lib64 --libexecdir=/opt/gcc-mainline/lib64 --enable-languages=c,c++,f77,objc,java,ada --enable-checking --enable-libgcj --with-gxx-include-dir=/opt/gcc-mainline/include/g++ --with-slibdir=/lib64 --with-system-zlib --enable-shared --enable-__cxa_atexit x86_64-suse-linux
Thread model: posix
gcc version 3.4.1 20040508 (prerelease) (SuSE Linux)
=================================================================
-O3 -funroll-loops -frerun-cse-after-loop -march=nocona
Nodes per second: 388145 (Score: 1.596)
-O2 -funroll-loops -frerun-cse-after-loop -march=nocona
Nodes per second: 365722 (Score: 1.504)
-O3 -funroll-loops -frerun-cse-after-loop
Nodes per second: 378021 (Score: 1.555)
-O2 -funroll-loops -frerun-cse-after-loop
Nodes per second: 365722 (Score: 1.504)
-O3 -march=nocona -funroll-loops -fomit-frame-pointer -ffast-math -fprofile-arcs
Nodes per second: 311526 (Score: 1.281)
-O2 -march=nocona -funroll-loops -fomit-frame-pointer -ffast-math -fprofile-arcs
Nodes per second: 299173 (Score: 1.230)
-O2 -funroll-loops -fomit-frame-pointer -ffast-math -fprofile-arcs
Nodes per second: 279724 (Score: 1.150)
-O3 -funroll-loops -fomit-frame-pointer -ffast-math -fprofile-arcs
Nodes per second: 299173 (Score: 1.230)
Matthew Daws - Saturday, August 21, 2004 - link
Not true. These options are on at least GCC 3.2.2, and on the P4 system I have access to (it's a university computer) I get 422K nodes/sec using the above compiler settings from Ace's.--Matt
KristopherKubicki - Saturday, August 21, 2004 - link
Matthew Daws: Again, he is using GCC 3.4.1 which has huge optimizations and is something we havent moved over to yet.Kristopher
ThePlagiarmaster - Saturday, August 21, 2004 - link
Oops, forgot, MS says 1st half 2005 now for Win64. So we can expect it in June...ROFL. Still the Semprons will be eaten for lunch then by next xmas by 64bit chips that are only $20 more right now. Then again, AMD could just solve the problem by turning on 64bit for Semprons :)Plag
Matthew Daws - Saturday, August 21, 2004 - link
Kris,Sorry to keep harping on here. But if you look over at Ace's:
http://www.aceshardware.com/forum?read=115094123
You'll find the compiler options you need to get much better results (I'm getting 291K now, on a 2GHz celeron). The general opinion is that TSCP favours the P4 without some careful compiler work. The Athlon numbers, with stock compiler options, are probably OK. But the P4 numbers in the older article seem very low...
--Matt
ThePlagiarmaster - Saturday, August 21, 2004 - link
I'm having a hard time with any recommendation of the sempron over 64bit cpus that are only 10% more (we're talking like $20 here). Nobody will use more than 4gb with these. Thats a given. However, the 64bitness can't be overlooked. Look at the examples AMD has already showed (recently for example). That panorama filter they showed with 57% improvement in speed, and the other thing in the same news post showing 47% improvement. AFAIK neither of these were using more than 4GB. This is with a BETA Win64!http://www.amd.com/us-en/Corporate/VirtualPressRoo...
These are only two examples of TONS that will be on the way shortly (immediately following the OS from MS that is). Intel is now backing this stuff too. Expect more 64bit ports, especially with MS finally getting off the collective ARSES and saying windows64 will be done this year (nah, I say jan/feb...but the point's still valid). This stuff is coming (encryption shows HUGE benefits, and zipping too with nowhere near 4GB), why cut yourself from the game for $20? If $20 is going to break your bank, you have no business buying a PC. Spend it on your kids diapers or shoes instead...LOL
Plag
Matthew Daws - Saturday, August 21, 2004 - link
Kris,I found the following in the source file main.c for TSCP 1.8.1:
/* Score: 1.000 = my Athlon XP 2000+ */
Checking, this means that the author gets circa 243K nodes/sec with his Athlon XP 2000+. I think, in light of this, that my numbers seem correct and yours seem way of base.
Cheers, --Matt
balzi - Saturday, August 21, 2004 - link
Helloooo.. !!!! am I using a mute account??is there any answer to the muddle of benchmark graphs.. please humour me by actually saying something.. Even 'I couldn't be stuffed fixing them' would be good.
thanks
PrinceGaz - Friday, August 20, 2004 - link
40-bit physical address space is 1TB, the 48-bit virtual address space allows for a range of up to 256TB. I think that should be sufficient for the lifetime of the Opteron / Athlon 64.