The Samsung Galaxy S10+ Snapdragon & Exynos Review: Almost Perfect, Yet So Flawed
by Andrei Frumusanu on March 29, 2019 9:00 AM ESTInference Performance: APIs, Where Art Thou?
Having covered the new CPU complexes of both new Exynos and Snapdragon SoCs, up next is the new generation neural processing engines in each chip.
The Snapdragon 855 brings big performance improvements to the table thanks to a doubling of the HVX units inside the Hexagon 690 DSP. The HVX units in the last two generations of Snapdragon chips were the IP blocks who took the brunt of new integer neural network inferencing work, an area the IP is specifically adept at.
The new tensor accelerator inside of the Hexagon 690 was shown off by Qualcomm at the preview event back in January. Unfortunately one of the issues with the new block is that currently it’s only accessible through Qualcomm’s own SDK tools, and currently doesn’t offer acceleration for NNAPI workloads until later in the year with Android Q.
Looking at a compatibility matrix between what kind of different workloads are able to be accelerated by various hardware block in NNAPI reveals are quite sad state of things:
| NNAPI SoC Block Usage Estimates | |||
| SoC \ Model Type | INT8 | FP16 | FP32 |
| Exynos 9820 | GPU | GPU | GPU |
| Exynos 9810 | GPU? | GPU | CPU |
| Snapdragon 855 | DSP | GPU | GPU |
| Snapdragon 845 | DSP | GPU | GPU |
| Kirin 980 | GPU? | NPU | CPU |
What stands out in particular is Samsung’s new Exynos 9820 chipset. Even though the SoC promises to come with an NPU that on paper is extremely powerful, the software side of things make it as if the block wouldn’t exist. Currently Samsung doesn’t publicly offer even a proprietary SDK for the new NPU, much less NNAPI drivers. I’ve been told that Samsung looks to address this later in the year, but how exactly the Galaxy S10 will profit from new functionality in the future is quite unclear.
For Qualcomm, as the HVX units are integer only, this means only quantised INT8 inference models are able to be accelerated by the block, with FP16 and FP32 acceleration falling back what should be GPU acceleration. It’s to be noted my matrix here could be wrong as we’re dealing with abstraction layers and depending on the model features required the drivers could run models on different IP blocks.
Finally, HiSilicon’s Kirin 980 currently only offers NNAPI acceleration for FP16 models for the NPU, with INT8 and FP32 models falling back to the CPU as the device are seemingly not using Arm’s NNAPI drivers for the Mali GPU, or at least not taking advantage of INT8 acceleration ine the same way Samsung's GPU drivers.
Before we even get to the benchmark figures, it’s clear that the results will be a mess with various SoCs performing quite differently depending on the workload.
For the benchmark, we’re using a brand-new version of Andrey Ignatov’s AI-Benchmark, namely the just released version 3.0. The new version tunes the models as well as introducing a new Pro-Mode that most interestingly now is able to measure sustained throughput inference performance. This latter point is important as we can have very different performance figures between one-shot inferences and back-to-back inferences. In the former case, software and DVFS can vastly overshadow the actual performance capability of the hardware as in many cases we’re dealing with timings in the 10’s or 100’s of milliseconds.
Going forward we’ll be taking advantage of the new benchmark’s flexibility and posting both instantaneous single inference times as well sequential throughput inference times; better showcasing and separating the impact of software and hardware capabilities.
There’s a lot of data here, so for the sake of brevity I’ll simply put up all the results up and we’ll go over the general analysis at the end:
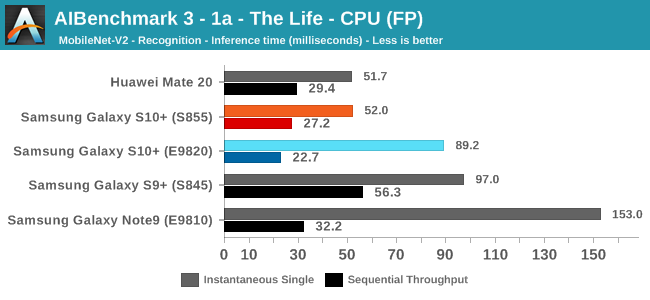
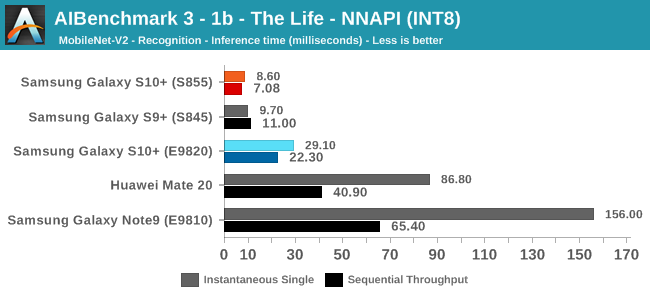
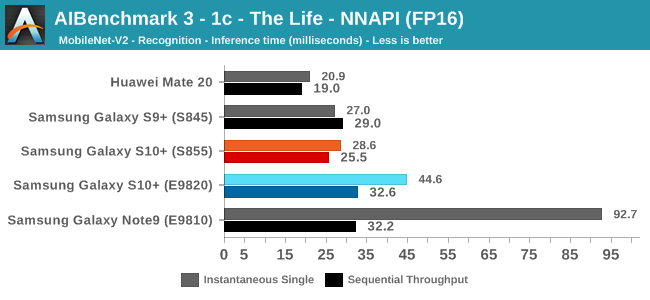
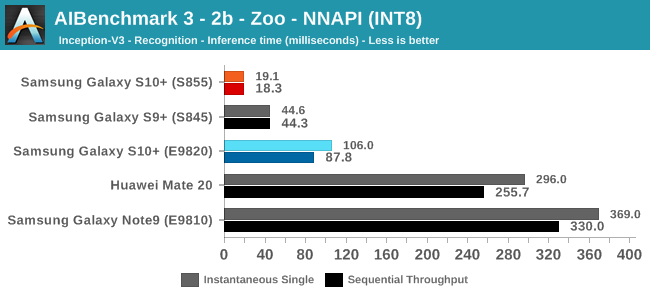
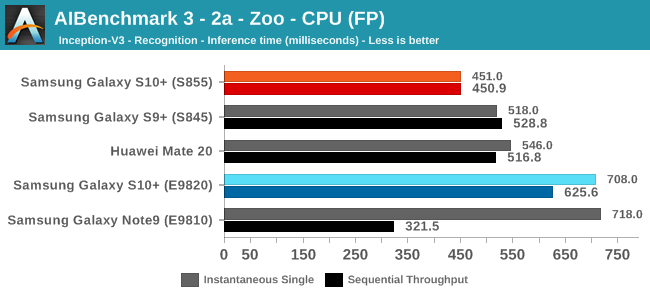
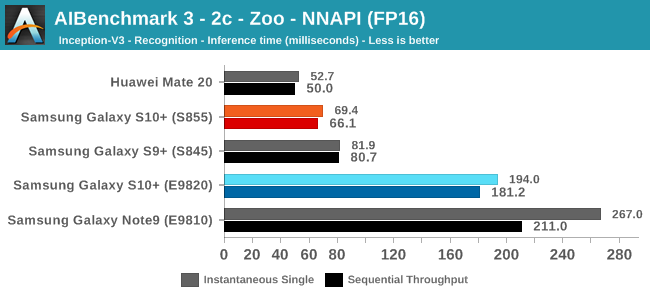
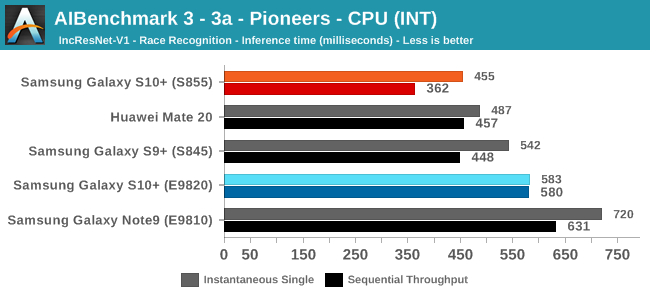
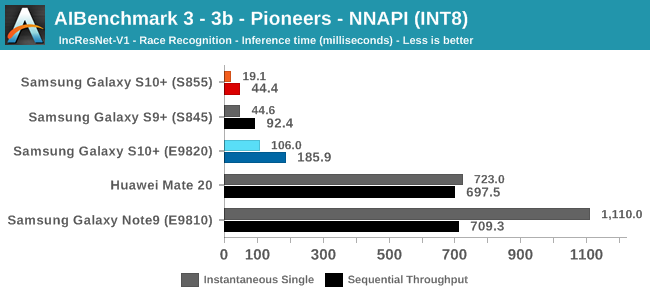
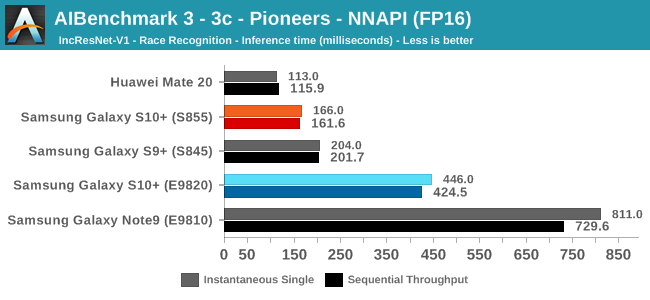
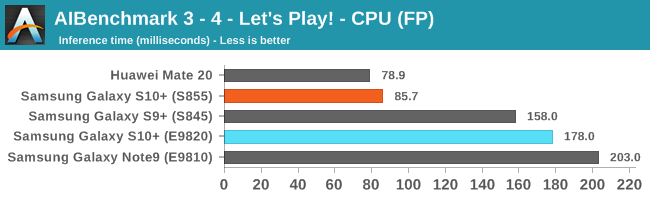
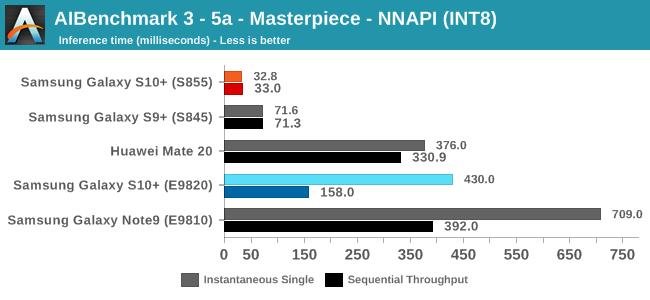
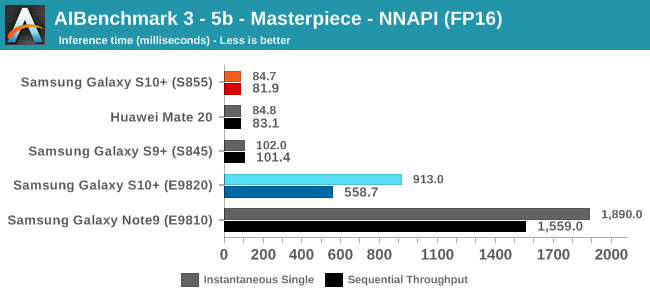
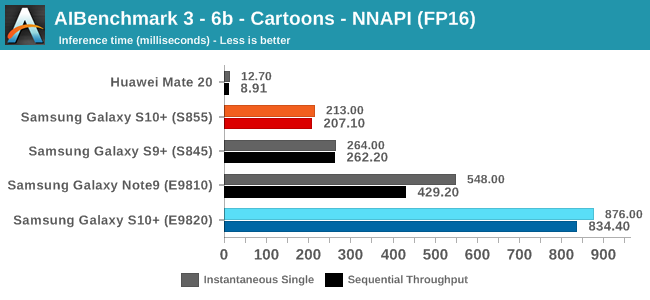
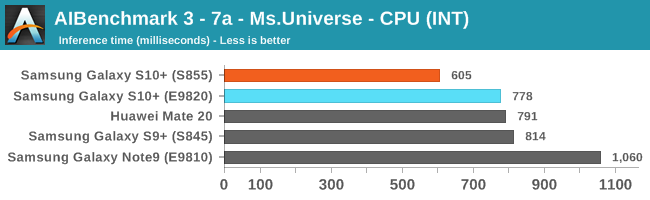
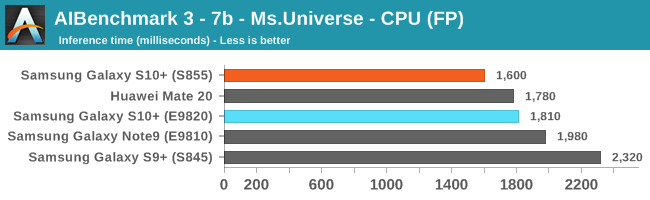
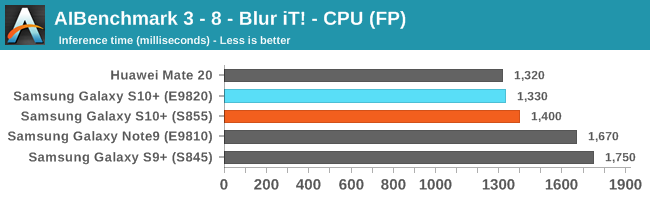
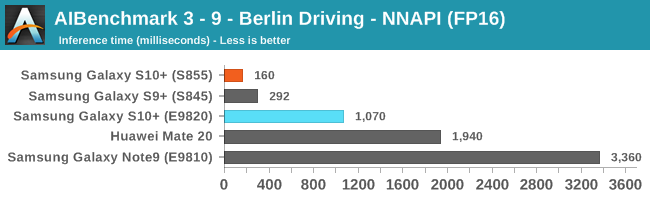
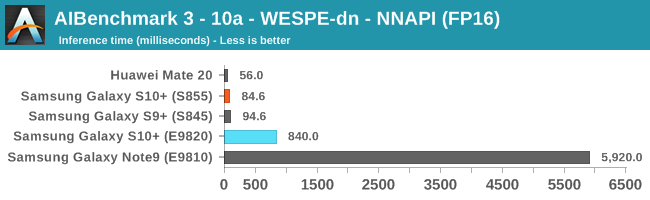
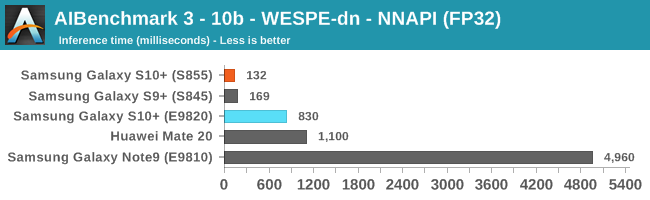
As initially predicted, the results are extremely spread across all the SoCs.
The new tests also include workloads that are solely using TensorFlow libraries on the CPU, so the results not only showcase NNAPI accelerator offloading but can also serve as a CPU benchmark.
In the CPU-only tests, we see the Snapdragon 855 and Exynos 9820 being in the lead, however there’s a notable difference between the two when it comes to their instantaneous vs sequential performance. The Snapdragon 855 is able to post significantly better single inference figures than the Exynos, although the latter catches up in longer duration workloads. Inherently this is a software characteristic difference between the two chips as although Samsung has improved scheduler responsiveness in the new chip, it still lags behind the Qualcomm variant.
In INT8 workloads there is no contest as Qualcomm is far ahead of the competition in NNAPI benchmarks simply due to the fact that they’re the only vendor being able to offload this to an actual accelerator. Samsung’s Exynos 9820 performance here actually has also drastically improved thanks to the new Mali G76’s new INT8 dot-product instructions. It’s odd that the same GPU in the Kirin 980 doesn’t show the same improvements, which could be due to not up-to-date Arm GPU NNAPI drives on the Mate 20.
The FP16 performance crown many times goes to the Kirin 980 NPU, but in some workloads it seems as if they fall back to the GPU, and in those cases Qualcomm’s GPU clearly has the lead.
Finally for FP32 workloads it’s again the Qualcomm GPU which takes an undisputed lead in performance.
Overall, machine inferencing performance today is an absolute mess. In all the chaos though Qualcomm seems to be the only SoC supplier that is able to deliver consistently good performance, and its software stack is clearly the best. Things will evolve over the coming months, and it will be interesting to see what Samsung will be able to achieve in regards to their custom SDK and NNAPI for the Exynos NPU, but much like Huawei’s Kirin NPU it’s all just marketing until we actually see the software deliver on the hardware capabilities, something which may take longer than the actual first year active lifespan of the new hardware.








229 Comments
View All Comments
cha0z_ - Tuesday, April 9, 2019 - link
My exynos note 9 running android 9 also scores a lot higher vs his scores.nicolaim - Friday, March 29, 2019 - link
I have the S7. This is the first new model that's tempting me to upgrade, so Samsung must be doing something right. I don't like the curved sides, nor the badly placed power button, but everything else seems quite good.zeeBomb - Friday, March 29, 2019 - link
Ah, I forgot how good Andrei’s review on hardware is. Great stuff man, always detailed and straight to the point.Awful - Friday, March 29, 2019 - link
Am I the only one that finds the spec2006 graphs a real chore to decipher/get a picture of relative performance from? It might just be that on the 1080p screen I'm reading them on I have to scroll down to see which extremely similar colored bar is which.The usual anandtech graphs on the other page are much easier going though.
jospoortvliet - Saturday, March 30, 2019 - link
Well it is showing something complicated so no surprise it is a complex graph. I find that after a few you get used to reading them and they are certainly by far the best representation of this set of information I have seen anywhere.name99 - Saturday, March 30, 2019 - link
Actually I do hope that subsequent versions of the memory latency/bandwidth graphs are normalized to all have the same axes (in both directions).It's surprisingly difficult to compare one graph with another given that they're all scaled slightly differently :-(
tipoo - Sunday, March 31, 2019 - link
It's also quite hard to make out "spotted" from "more spotted" in the legend. As much as more data is cool I think in these cases it would be best to pare down what's in the graph so the legend and bar colors are more easily identifiable, and then post the full results elsewhere.Awful - Friday, March 29, 2019 - link
Also, any chance of including portrait mode evaluation? Seems like a bit of an omission for evaluating the camera...XelaChang - Friday, March 29, 2019 - link
Thanks! Been waiting for it.SwordOS - Friday, March 29, 2019 - link
correct the phone specs please, the s10e doesn't heave the heart rate monitor and none of the s10s has the iris scanner