The NVIDIA GeForce GTX 1660 Ti Review, Feat. EVGA XC GAMING: Turing Sheds RTX for the Mainstream Market
by Ryan Smith & Nate Oh on February 22, 2019 9:00 AM ESTTU116: When Turing Is Turing… And When It Isn’t
Diving a bit deeper into matters, we have the new TU116 GPU at the heart of the GTX 1660 Ti. While NVIDIA does not announce future products in advance, you can expect that this will be the first of at least a couple of GPUs in what’s now the TU11x family, as NVIDIA is going to want to follow the same streamlined strategy for the eventual successors to GP107 and possible GP108.
TU116 is an interesting piece of kit, both because of the decisions that lead to this point and because of both the drawbacks and advantages of excising some of Turing’s functionality. As mentioned earlier in this article, NVIDIA has made a very deliberate decision to cut out their RTX functionality – the ray tracing cores and tensor cores – in order to produce a GPU that’s better suited for traditional rendering. The end result is a smaller, cheaper to produce GPU. But it also means that NVIDIA has to change how they go about promoting cards based on this GPU.

With a die size of 284mm2, TU116 tells a story in and of itself. This makes it 40% smaller than the next-smallest Turing GPU, TU106. Similarly, the transistor count has come down from 10.8 billion to 6.6 billion. This greatly improves the manufacturability of the GPU and drives down its costs, especially since NVIDIA will be going into more competitive markets with it than the other TU10x GPUs. Still, TU116 is some 42% bigger than the 200mm2 GP106 die that it replaces, so even though it’s more efficient, NVIDIA is still dealing with a significant increase in die size on a generation-by-generation basis.
Unfortunately, TU116 doesn’t give us a terribly good baseline for determining how much of a TU10x SM was composed of RTX hardware. TU116 doesn’t just drop the RTX hardware in its SMs, but it’s a smaller design overall; fewer SMs, fewer memory channels, and fewer ROPs. So we can’t fully separate the savings of dropping RTX from the savings of making a lighter GPU in general. However it’s interesting to note that on a relative basis, the transistor count difference between TU116 and TU106 is almost exactly the same as GP106 and GP104: there are 39% fewer transistors when stepping down. So later on it will give us an opportunity to look at performance and see if the performance gap between the GTX 1660 Ti and RTX 2070 – the full-fat cards of their respective GPUs – is anything like the sizable gap between the GTX 1060 6GB and the GTX 1080.
| NVIDIA Turing GPU Comparison | ||||||
| TU102 | TU104 | TU106 | TU116 | |||
| CUDA Cores | 4608 | 3072 | 2304 | 1536 | ||
| SMs | 72 | 48 | 36 | 24 | ||
| Texture Units | 288 | 192 | 144 | 96 | ||
| RT Cores | 72 | 48 | 36 | N/A | ||
| Tensor Cores | 576 | 384 | 288 | N/A | ||
| ROPs | 96 | 64 | 64 | 48 | ||
| Memory Bus Width | 384-bit | 256-bit | 256-bit | 192-bit | ||
| L2 Cache | 6MB | 4MB | 4MB | 1.5MB | ||
| Register File (Total) | 18MB | 12MB | 9MB | 6MB | ||
| Architecture | Turing | Turing | Turing | Turing | ||
| Manufacturing Process | TSMC 12nm "FFN" | TSMC 12nm "FFN" | TSMC 12nm "FFN" | TSMC 12nm "FFN" | ||
| Die Size | 754mm2 | 545mm2 | 445mm2 | 284mm2 | ||
But getting back to architecture, this launch is one of a handful of times we’ve seen NVIDIA use dissimilar GPUs in their consumer cards, and it’s a situation without a good parallel. NVIDIA had done plenty of non-homogenous families in the past, but typically the black sheep of the family is the high-end server GPU, e.g. GP100, where it gets additional features not found in the consumer lineup. Instead the Turing family ends up having a split right down the middle.
The good news for consumers is that, outside of RTX functionality, TU116 and its ilk – which for the sake of simplicity I’m going to call Turing Minor from here on out – is functionally equivalent to TU102/TU104/TU106 (Turing Major). Turing Minor has the exact same DirectX feature set, the exact same core compute architecture (right on down to cache sizes), the exact same video and display blocks, etc. The RT and tensor cores really are the only thing that’s changed.
The situation looks much the same for programmers & developers as well: on the current press drivers the GTX 1660 TI reports itself as a Compute Capability 7.5 card – the same CC version as all of the Turing Major cards – so developers won’t have to even compile separate code for Turing Minor cards. So long as their code can handle a lack of tensor cores, at least.
(As a brief aside, as a performance exercise we ran the tensor version of our HGEMM benchmark on the GTX 1660 Ti. And it completed?! Performance was a bit lower, at 10.8 TFLOPS versus 11 TFLOPS with tensors disabled, but it did complete. Which indicates that either NVIDIA has been less than forthcoming on TU116, or in order to keep all Turing parts on CC 7.5, they are sending tensor ops through the CUDA cores on Turing Minor cards)
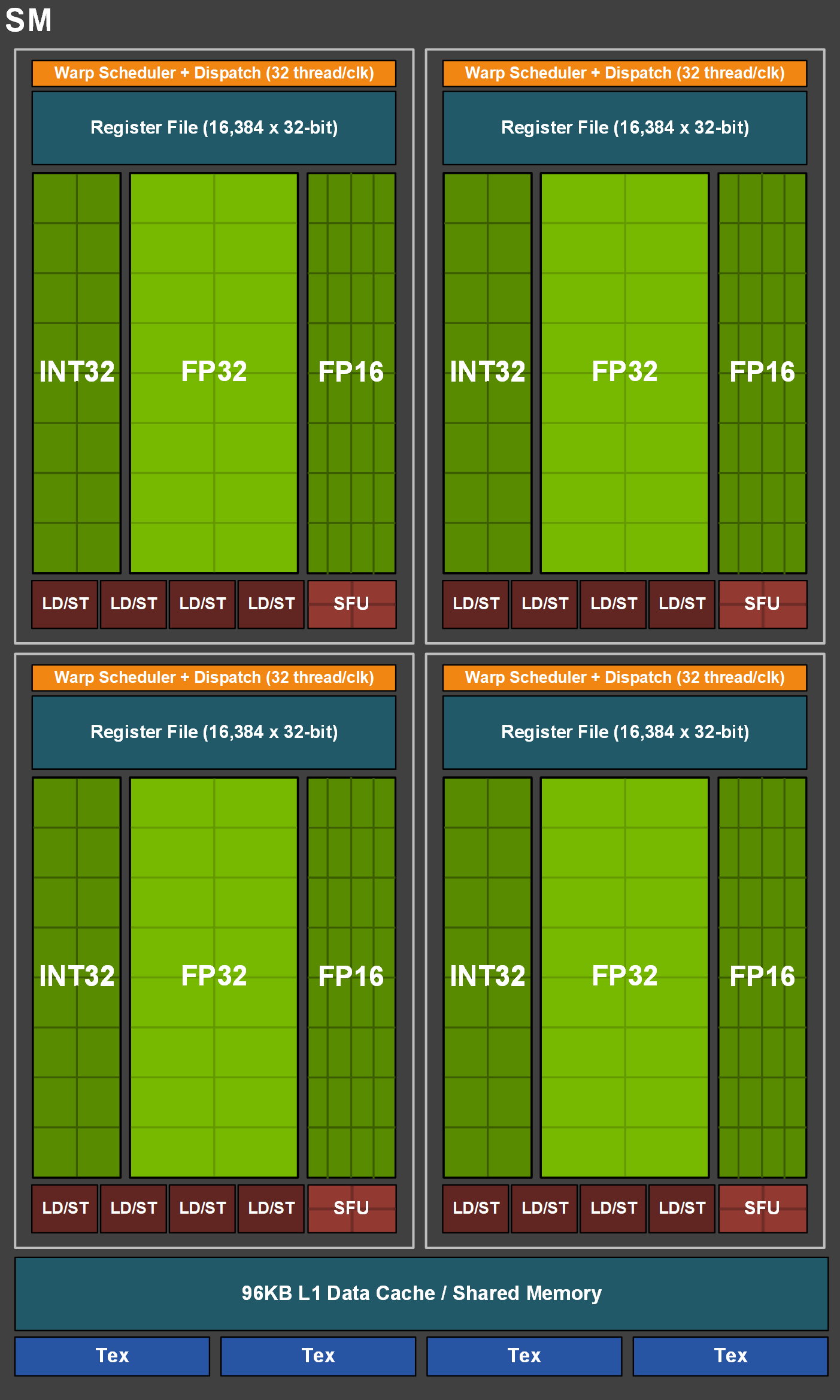
Looking at the TU116 SM, what we find is something almost identical to the SM diagrams used for Turing Major, with the SM arranged into 4 partitions, each with their own warp schedule and set of CUDA cores, while all 4 partitions share the L1 cache and texture units. Cache sizes and register file sizes are all unchanged here, so average throughput and register pressure are similarly unchanged as well. The one standout is that in replacing the tensor cores in their diagram, NVIDIA has opted to draw in FP16 cores, which is a bit of a stretch given what we know about the Turing architecture. NVIDIA only sent out this diagram yesterday, so I’m still checking with them to see if this is the company taking a creative liberty to highlight Turing’s other functionality, or if there’s more to it that NVIDIA is downplaying to keep things simple (ala Kepler and GK104).
Update: NVIDIA has gotten back to me this morning. As it turns out, the FP16 cores in the diagram are quite literal. For more information, please see below.
The Curious Case of FP16: Tensor Cores vs. Dedicated Cores
Even though Turing-based video cards have been out for over 5 months now, every now and then I’m still learning something new about the architecture. And today is one of those days.
Something that escaped my attention with the original TU102 GPU and the RTX 2080 Ti was that for Turing, NVIDIA changed how standard FP16 operations were handled. Rather than processing it through their FP32 CUDA cores, as was the case for GP100 Pascal and GV100 Volta, NVIDIA instead started routing FP16 operations through their tensor cores.
The tensor cores are of course FP16 specialists, and while sending standard (non-tensor) FP16 operations through them is major overkill, it’s certainly a valid route to take with the architecture. In the case of the Turing architecture, this route offers a very specific perk: it means that NVIDIA can dual-issue FP16 operations with either FP32 operations or INT32 operations, essentially giving the warp scheduler a third option for keeping the SM partition busy. Note that this doesn’t really do anything extra for FP16 performance – it’s still 2x FP32 performance – but it gives NVIDIA some additional flexibility.
Of course, as we just discussed, the Turing Minor does away with the tensor cores in order to allow for a learner GPU. So what happens to FP16 operations? As it turns out, NVIDIA has introduced dedicated FP16 cores!
These FP16 cores are brand new to Turing Minor, and have not appeared in any past NVIDIA GPU architecture. Their purpose is functionally the same as running FP16 operations through the tensor cores on Turing Major: to allow NVIDIA to dual-issue FP16 operations alongside FP32 or INT32 operations within each SM partition. And because they are just FP16 cores, they are quite small. NVIDIA isn’t giving specifics, but going by throughput alone they should be a fraction of the size of the tensor cores they replace.
To users and developers this shouldn’t make a difference – CUDA and other APIs abstract this and FP16 operations are simply executed wherever the GPU architecture intends for them to go – so this is all very transparent. But it’s a neat insight into how NVIDiA has optimized Turing Minor for die size while retaining the basic execution flow of the architecture.
Now the bigger question in my mind: why is it so important to NVIDIA to be able to dual-issue FP32 and FP16 operations, such that they’re willing to dedicate die space to fixed FP16 cores? Are they expecting these operations to be frequently used together within a thread? Or is it just a matter of execution ports and routing? But that is a question we’ll have to save for another day.
Turing Minor: Turing Sans RTX
For better or worse, the launch of GTX 1660 Ti and Turing Minor means that NVIDIA has needed to adjust how they go about promoting the new cards and the Turing architecture. While Turing launched with a laundry list of features, most of which had nothing to do with RTX, the broader consumer zeitgeist definitely focused on RTX and for good reason: compared to all of the low-level architectural changes under the hood, ray tracing, DLSS, and other RTX features are a lot more visible, and for NVIDIA they were easier to promote. This means that for Turing Minor NVIDIA instead has to focus on the low-level architectural improvements in Turing, which I think is great since these were largely overlooked at the Turing launch.

While I won’t recap our entire Turing deep dive here, relative to Pascal The big difference here is the numerous steps NVIDIA has taken to improve their IPC and overall efficiency. For example, Turing made the surprising move to ditch regular forms of Instruction Level Parallelism (ILP) by dropping the second warp scheduler dispatch port. Instead, each warp scheduler fires off a single set of instructions on each clock, taking advantage of the fact that it takes 2 (or more) clocks to issue a full warp in order to interleave a second instruction in.
This ILP change goes hand-in-hand with partitioning the SM into 4 blocks instead of 2, which serves to help better control resource contention among the warps and CUDA cores. In fact at a high level, a Turing SM looks a lot more like some of NVIDIA’s server-focused GPUs than their consumer-focused GPUs; there’s a lot more plumbing here in various forms to support the CUDA cores and to help them achieve better performance, rather than just throwing more CUDA cores at the problem. The net result is that while we don’t have metrics from NVIDIA, I fully expect that the ratio of supporting hardware and glue logic to CUDA cores is significantly higher on Turing than it was GP106 Pascal. Though by the same token, I expect the SMs as a whole are larger than Pascal’s as well, which is certainly reflected in the die size.
A big part of this change, in turn, is the fact that NVIDIA broke out their Integer cores into their own block. Previously a separate branch of the FP32 CUDA cores, the INT32 cores can now be addressed separately from the FP32 cores, which combined with instruction interleaving allows NVIDIA to keep both occupied at the same time. Now make no mistake: floating point math is still the heart and soul of shading and GPU compute, however integer performance has been slowly increasing in importance over time as well, especially as shaders get more complex and there’s increased usage of address generation and other INT32 functions. This change is a big part of the IPC gains NVIDIA is claiming for Turing architecture.
Speaking of CUDA cores, like all other Turing parts, TU116 and Turing Minor get NVIDIA’s fast FP16 functionality. This means that these GPUs can process FP16 operations at twice the rate of FP32 operations – via the GPU’s dedicated FP16 cores – which for GTX 1660 Ti works out to 11 TFLOPS of performance. Using FP16 shaders in PC games is still relatively new – the baseline 8th gen consoles don’t support it and NVIDIA previously limited this feature to server parts – but it’s more widely used in mobile games where FP16 support is common. There, as it will be in the PC space, FP16 shaders allow for developers to trade off between performance and shader precision by using a lower precision format; not all shader programs require a full FP32’s worth of precision, and when done right it can improve performance and reduce memory bandwidth needs without any real image quality impact.
Meanwhile, looking at the rest of the GPU, the memory and cache system is a bit of a grab bag. On the one hand, Turing implements NVIDIA’s latest lossless memory compression technology. This has proven to be one of NVIDIA’s bigger advantages over AMD, and continues to allow them to get away with less memory bandwidth than we’d otherwise expect some of their GPUs to need. The actual savings vary from game to game, but for the GTX 2080 Ti launch, NVIDIA reported that they were seeing reductions in traffic between 18% and 33%
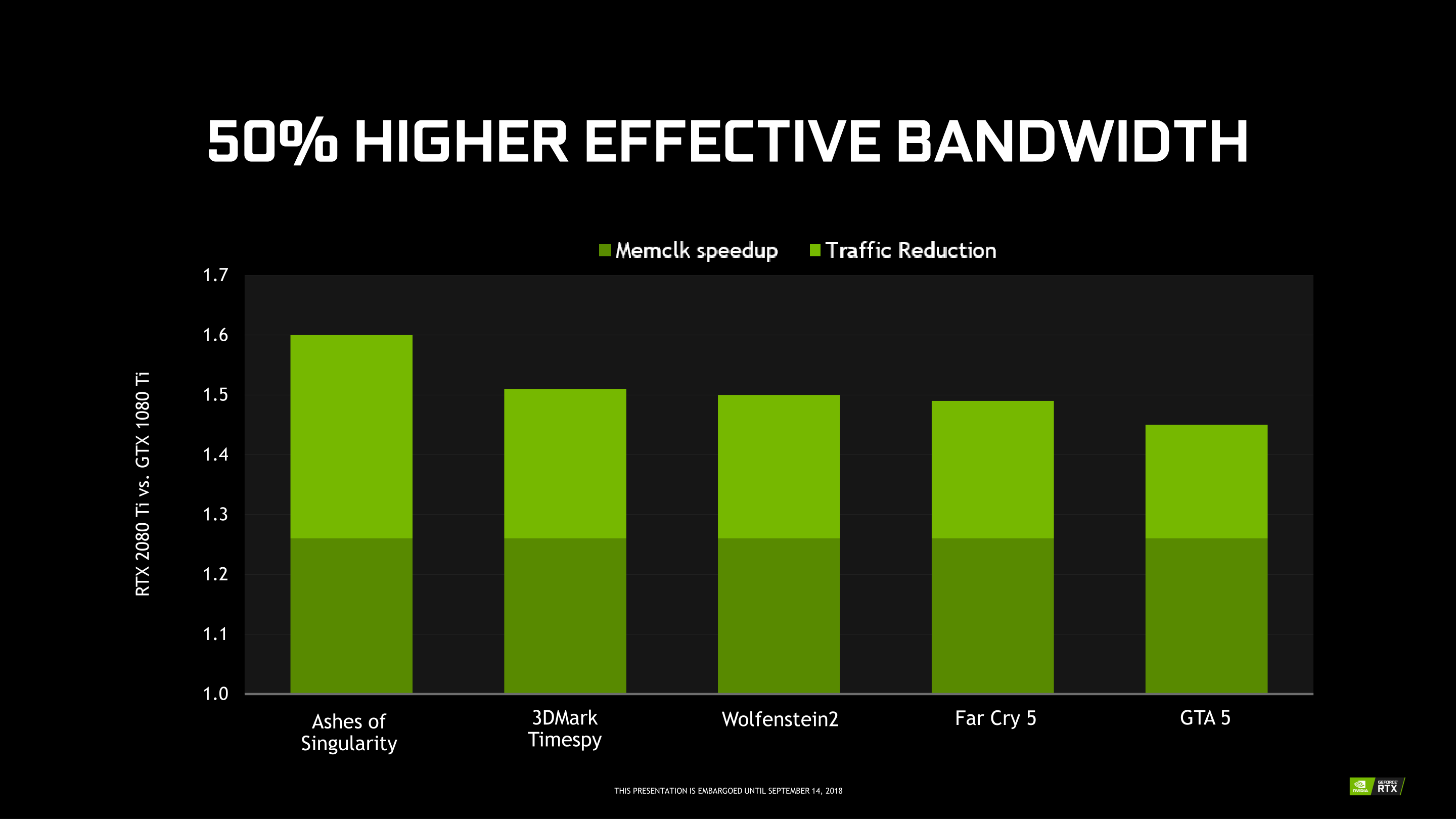
From the RTX 2080 Ti Launch
However, distinct to TU116 versus its Turing Major siblings, the latest GPU has a less L2 cache per ROP partition. Turing Major GPUs all have 512KB of L2 cache per partition, giving TU106 a total of 4MB of L2, for example. TU116 on the other hand has just 256KB of L2 per partition for a total of 1.5MB of L2, which happens to be the same amount of cache and cache ratios as on GP106. The performance impact of this is hard to measure given all of the other changes in the GPU, but clearly NVIDIA had traded off some die size at the cost of some increases in cache misses. The wildcard in all of this being how much the additional bandwidth of GDDR6 helps to offset those misses.
Finally on the graphics front, Turing Minor also retains Turing’s adaptive shading capabilities. Not unlike RTX, this is a new feature that is going to take some time to get adopted, so we’ve only seen a handful of games (such as Wolfenstein II) implement it thus far. But by reducing the pixel shader granularity/rate used at various points in a scene, the technology makes it possible to improve performance by reducing the overall shading workload.
The trick with adaptive shading – and why it’s a feature rather than an immediate and transparent means of improving performance – is that it’s making a very direct quality/speed tradeoff with pixel shaders; the reduced shading rate can reduce the overall image quality by reducing clarity and creating aliasing artifacts. So developers are still in their infancy playing with the technology to figure out where they can use it without noticeably hurting image quality. In practice I expect we’re going to see it more widely deployed in VR games at first, as the tech is much easier to use there (reduce the rate anywhere the user isn’t looking), as opposed to traditional games.

The end result of all of this is that while Turing Minor has some very important feature differences from Turing Major, at the end of the day it’s still Turing. NVIDIA for their part is going to have to grapple with the fact that not all of their current-generation cards feature RTX functionality, but that’s going to be marketing’s problem. As for consumers, unless you’re specifically seeking out NVIDIA’s ray tracing and tensor core functionality, GTX 1660 Ti is just another Turing.








157 Comments
View All Comments
Fallen Kell - Friday, February 22, 2019 - link
I don't have any such hopes for Navi. The reason is that AMD is still competing for the console and part of that is maintaining backwards compatibility for the next generation of consoles with the current gen. This means keeping all the GCN architecture so that graphics optimizations coded into the existing games will still work correctly on the new consoles without the need for any work.GreenReaper - Friday, February 22, 2019 - link
Uh... I don't think that follows. Yes, it will be a bonus if older games work well on newer consoles without too much effort; but with the length of a console refresh cycle, one would expect a raw performance improvement sufficient to overcome most issues. But it's not as if when GCN took over from VLIW, older games stopped working; architecture change is hidden behind the APIs.Korguz - Friday, February 22, 2019 - link
Fallen Kell" The reason is that AMD is still competing for the console and part of that is maintaining backwards compatibility for the next generation of consoles with the current gen. "
prove it... show us some links that state this
Korguz - Friday, February 22, 2019 - link
CiccioB" GCN was dead at its launch time"
prove it.. links showing this, maybe .....
CiccioB - Saturday, February 23, 2019 - link
Aahahah.. prove it.9 years of discounted sell are not enough to show you that GCN simply started as half a generation old architecture to end as a generation obsolete one?
Yes, you may recall the only peak glory in GCN life, that is Hawaii, which was so discounted that made nvidia drop the price of their 780Ti. After that move AMD just brought up a fail after the other, starting with Fiji and it's monster BOM cost just to reach the much cheaper GM200 based cards and following with Polaris (yes, the once labeled "next AMD generation is going to dominate") and then again with Vega and Vega VII is not different.
What have you not understood that AMD has to use whatever technology available to get a performance near that of a 2080? What do you think will be the improvements nvidia will achieve once they will move to 7nm (or 7nm+)?
Today AMD is incapable to get to nvidia performances and they also lack their modern features. GCN at 7nm can be as fast a a 1080Ti that is 3 years older. Despite the AMD card still uses more power, which still shows how inefficient GCN architecture is.
That's why I hope Navi is a real improvement, or we will be left with nvidia monopoly as at 7nm it will really have more than generation of advantage, seen it will be much more efficient and still having new features that AMD will then add only in 3 or 4 years from now.
Korguz - Saturday, February 23, 2019 - link
links to what you stated ??? sounds a little like just your opinion, with no links....considering that AMD doesnt have the deep pockets that Nvidia has, or the part that amd has to find the funds to R&D BOTH gpus, AND gpus, while nvida can put all the funds that can into R&D, it seems to me that AMD has done ok for that that have had to to work with over the years, with Zen doing well in the CPU space, they might start to have a little more funds to put back into their products, and while i havent read much about Navi, i am also hopeful that it may give nvidia some competition, as we sure do need it...
CiccioB - Monday, February 25, 2019 - link
It seems you lack the basic intelligence to understand the facts that can be seen by anyone else.You just have hopes that are based on "your opinion", not facts.
"they might start to have a little more funds to put back into their products". Well, last quarter with Zen selling like never before they managed to have a 28 millions net income.
Yes, you read right. 28. Nvidia with all its problems got more than 500. Yes, you read right. About 20 times more.
The facts are 2 (this are numbers based on facts, not opinion, and you can create interpretations on facts, not your hopes of the future):
- AMD is selling Ryzen CPU at a discount like GPUs and boths have a 0.2% net margin
- The margins they have on CPU can't compensate the looses they have in the GPU market, and seen that they manage to make some money with console only when there are some spike of requests, I am asking you when and from what AMD will get new funds to pay something.
You see, it's not that really "a hope" believing that AMD is loosing money for every Vega they sell seen the cost of the BOM with respect to the costs of the competition. Negating this is a "hope it is not real", not a sensible way to ask for "facts".
You have to know at least basic facts before coming here to ask for links on basic things that everyone that knows this market already knows.
If you want to start looking less idiot than you do by asking constantly for "proves and links", just start reading quarter results and see what are the effects of the long period strategies both companies have achieved.
Then, if you have a minimum of technical competence (which I doubt) look at what AMD does with its mm^2 and Watts and what nvidia does.
Then come again to ask for "links" where I can tell you that AMD architecture is one generation behind (and will be probably left once nvidia will pass to 7nm.. unless Navi is not GCN).
Do you have other intelligent questions to pose?
Korguz - Wednesday, February 27, 2019 - link
right now.. your facts.. are also just your opinion, i would like to see where you get your facts, so i can see the same, thats why i asked for links...again.. AMD is fighting 2 fronts, CPUs AND gpus.. Nvida.. GPU ONLY, im not refuting your " facts " about how much each is earning...its obvious... but.. common sense says.. if one company has " 20 times " more income then the other.. then they are able to put more back into the business, then the other... that is why, for the NHL at least, they have have salary caps, to level the playing field so some teams, cant " buy " their way to winning... thats just common sense...
" AMD is selling Ryzen CPU at a discount like GPUs and boths have a 0.2% net margin "
and where did you read this.. again.. post a link so we can see the same info... where did you read how much it costs AMD to make losing money on each Vega GPU ?? again.. post links so we can see the SAME info you are...
" You have to know at least basic facts before coming here to ask for links on basic things that everyone that knows this market already knows. " and some would like to see where you get these " facts " that you keep talking about... thats basic knowledge.
" if you have a minimum of technical competence " actually.. i have quite a bit of technical competence, i build my own comps, even work on my own car when i am able to. " look at what AMD does with its mm^2 and Watts and what nvidia does. " that just shows nvidia's architecture is just more efficient, and needs less power for that it does...
lastly.. i have been civil and polite to you in my posts.. resorting to name calling and insults, does not prove your points, or make your supposed " facts " and more real. quite frankly.. resorting to name calling and insults, just shows how immature and childish you are.. that is a fact
CiccioB - Thursday, February 28, 2019 - link
Did you read last (and understood) AMD latest quarter results?
Have you seen the total cost of production and the relative net income?
Have you an idea of how the margin is calculated (yes, it takes into account the production costs that are reported in the quarter results)?
Have you understood half of what I have written when based on facts that AMD just made $28 of NET income last quarter there are 2 possible ways of seeing the cause of those pitiful numbers? One is that AMD is discounting every product (GPU and CPU) to a ridiculous margin, the other that Zen is sold at a profit while GPUs are not? Or you may try to hypnotize the third view, that they are selling Zen at a loss and GPU with a big margin. Anything is good, but at leas one of these is true. Take the one you prefer and then try to think which one requires less artificial hypothesis to be true (someone once said that the best solution is most often the most simple one).
That demonstrates that nvidia architecture is simply one generation head, as what changes from a generation to the other is usually the performance you can get from a certain die are which sucks a certain amount of energy and just is the reason because a x80 level card today costs >$1000. If you can get the same 1080Ti performance (and so I'm not considering the new features nvidia has added to Turing) by using a complete new PP node, more current and HBM just 3 years later, then you may arrive at the conclusion that something is not working correctly on what you have created.
So my statement that GCN was dead at launch (when a 7970 was on par with a GTX680 which was smaller and uses much less energy) just finds it perfect demonstration in Vega 20 where GCN is simply 3 years back with a BOM costing at least twice that of the 1080Ti (and still using more energy).
Now, if you can't understand the minimum basic facts and your hope is that their interpretation using a completely genuine and coherent thesis is wrong and requires "fact and links", than it is no my problem.
Continue to hope that what I wrote is totally rubbish and that you are the one with the right answer to this particular situation. However what I said is completely coherent with t e facts that we have been witnessing from GCN launch up to now.
Korguz - Friday, March 1, 2019 - link
" Have you seen the total cost of production and the relative net income? "no.. thats is why i asked you to post where you got this from, so i can see the same info, what part do YOU not understand ?
" based on facts that AMD just made $28 of NET income last quarter" because you continue to refuse to even mention where you get these supposed facts from, i think your facts, are false.
" One is that AMD is discounting every product (GPU and CPU) to a ridiculous margin"
and WHERE have you read this??? has any one else read this, and can verify it?? i sure dont remember reading anything about this, any where
what does being hypnotized have to do with anything ?? do you even know what hypnotize means ?
just in case, this is what it means :
to put in the hypnotic state.
to influence, control, or direct completely, as by personal charm, words, or domination: The speaker hypnotized the audience with his powerful personality.
again.. resorting to being insulting means you are just immature and childish....
look.. you either post links, or mention where you are getting your facts and info from, so i can also see the SAME facts and info with out having to spend hours looking.. so i can make the the same conclusions, or, admit, you CANT post where you get your facts and info from, because, they are just your opinion, and nothing else.. but i guess asking a child to mention where they get their facts and info from, so one can then see the same facts and info, is just to much to ask...