The AMD Radeon VII Review: An Unexpected Shot At The High-End
by Nate Oh on February 7, 2019 9:00 AM ESTRadeon VII & Radeon RX Vega 64 Clock-for-Clock Performance
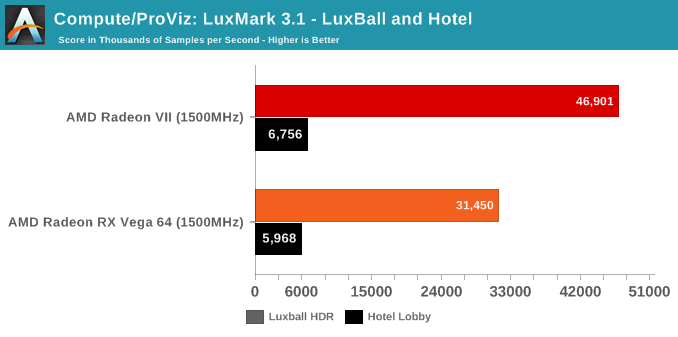
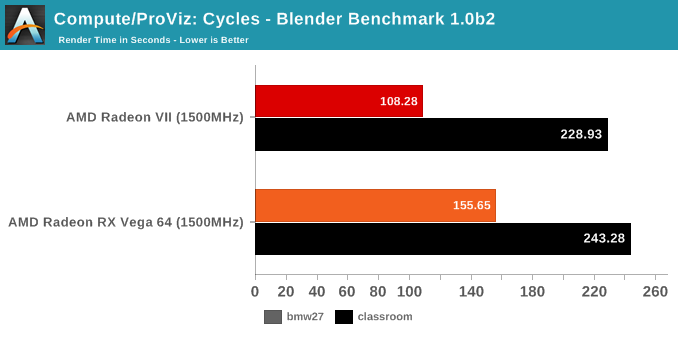
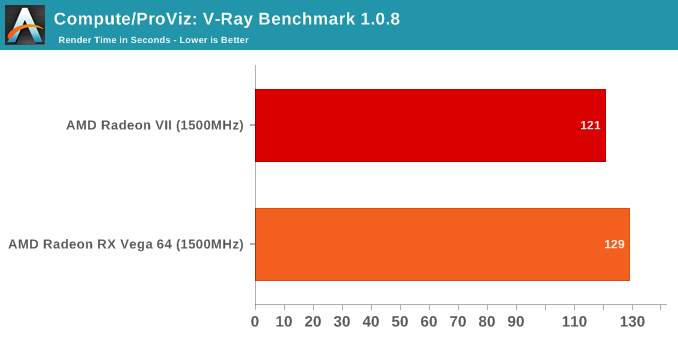
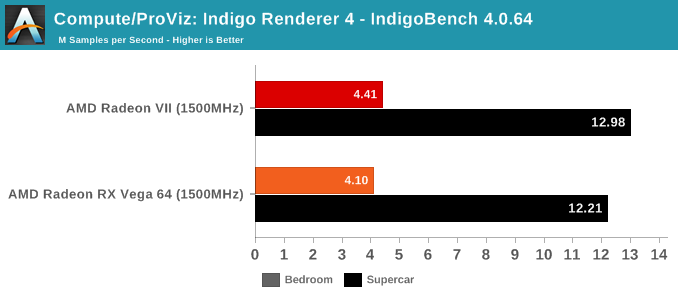
With the variety of changes from the Vega 10 powered RX Vega 64 to the new Radeon VII and its Vega 20 GPU, we wanted to take a look at performance and compute while controlling for clockspeeds. In this way, we can peek at any substantial improvements or differences in pseudo-IPC. There's a couple caveats here; obviously, because the RX Vega 64 has 64 CUs while the Radeon VII has only 60 CUs, the comparison is already not exact. The other thing is that "IPC" is not the exact metric measured here, but more so how much graphics/compute work is done per clock cycle and how that might translate to performance. Isoclock GPU comparisons tend to be less useful when comparing across generations and architectures, as like in Vega designers often design to add pipeline stages to enable higher clockspeeds, but at the cost of reducing work done per cycle and usually also increasing latency.
For our purposes, the incremental nature of 2nd generation Vega allays some of those concerns, though unfortunately, Wattman was unable to downclock memory at this time, so we couldn't get a set of datapoints for when both cards are configured for comparable memory bandwidth. While the Vega GPU boost mechanics means there's not a static pinned clockspeed, both cards were set to 1500MHz, and both fluctuated from 1490 to 1500MHZ depending on workload. All combined, this means that these results should be taken as approximations and lacking granularity, but are useful in spotting significant increases or decreases. This also means that interpreting the results is trickier, but at a high level, if the Radeon VII outperforms the RX Vega 64 at a given non-memory bound workload, then we can assume meaningful 'work per cycle' enhancements relatively decoupled from CU count.
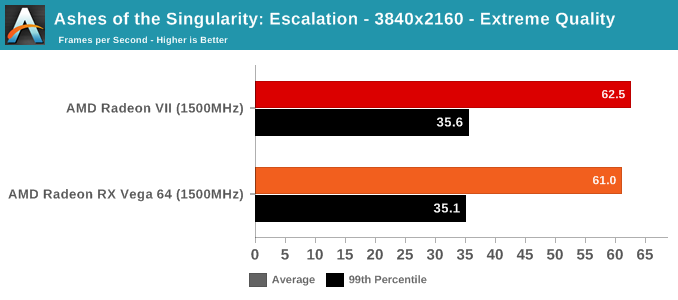
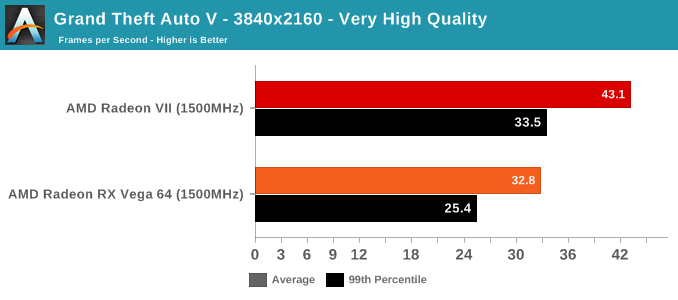
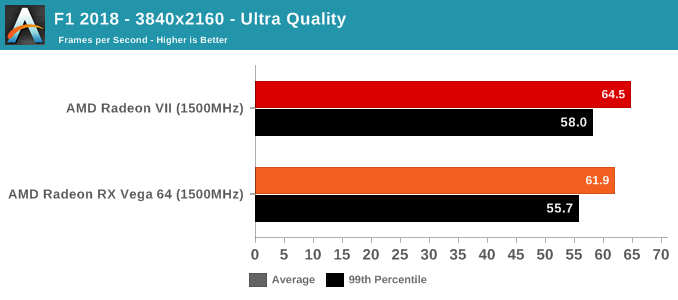
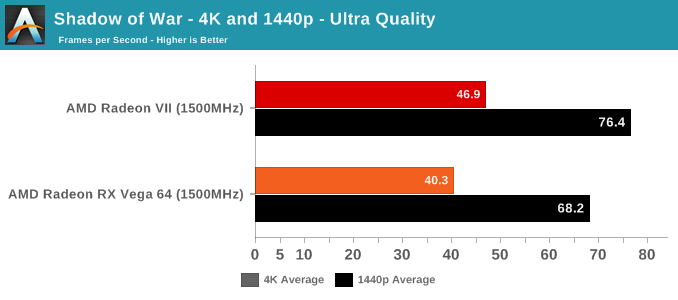
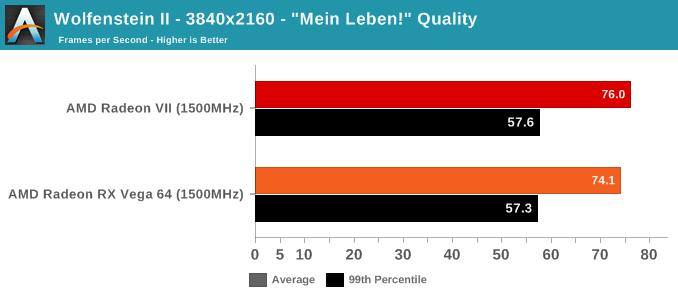
As mentioned above, we were not able to control for the doubled memory bandwidth. But in terms of gaming, the only unexpected result is with GTA V. As an outlier, it's less likely to be an indication of increased gaming 'work per cycle,' and more likely to be related to driver optimization and memory bandwidth increases. GTA V has historically been a title where AMD hardware don't reach the expected level of performance, so regardless there's been room for driver improvement.
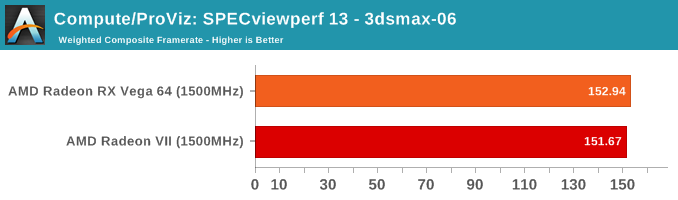
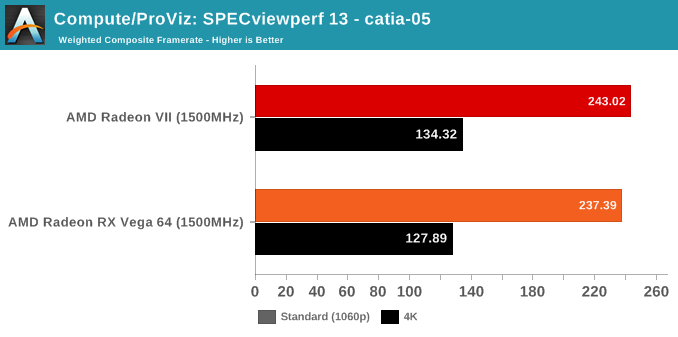
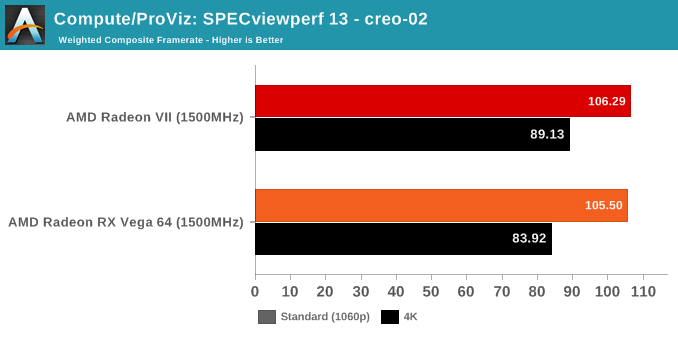
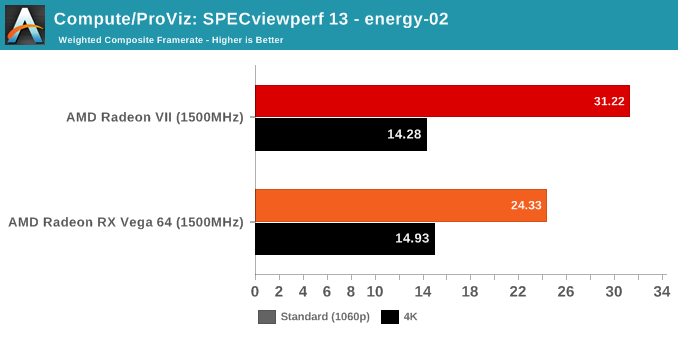
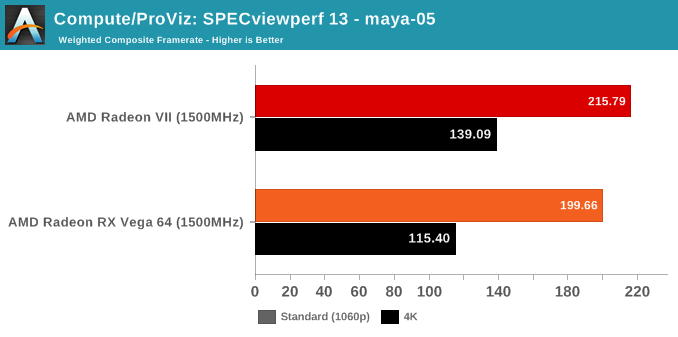
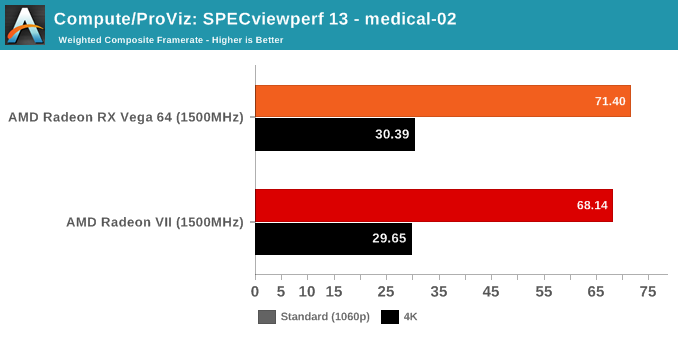
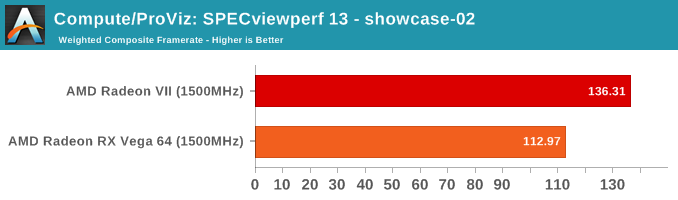
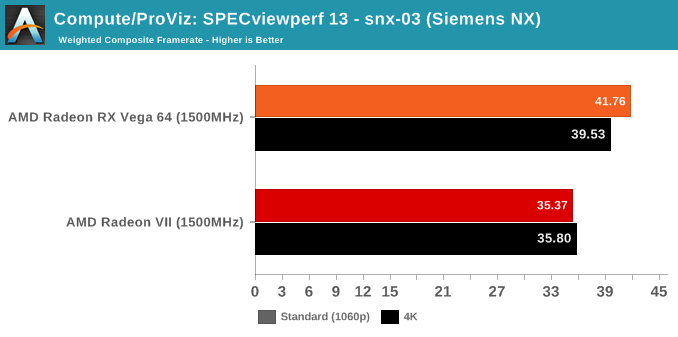
SPECviewperf is a slightly different story, though.








289 Comments
View All Comments
Alistair - Thursday, February 7, 2019 - link
Because everyone is already playing Anthem at 4k 60fps with a $400 card? Ray tracing is totally useless and we need way more rasterization performance per dollar than we have right now. Give me a 7nm 2080 ti without the RT cores for $699 and then we'll talk.eva02langley - Friday, February 8, 2019 - link
Fair, the main objective of gaming GPU are shaders per $. Gameworks gimmick are not something I call a selling factor... and Nvidia is forced to cook their books because of it.RSAUser - Thursday, February 7, 2019 - link
Why are you adding the Final Fantasy benchmark when it has known bias issues?Zizy - Thursday, February 7, 2019 - link
Eh, 2080 is slightly better for games and costs the same, while unfortunately MATLAB supports just CUDA so I can't even play with compute.Hul8 - Thursday, February 7, 2019 - link
On page 19, the "Load GPU Temperatur - FurMark" graph is duplicated.Ryan Smith - Thursday, February 7, 2019 - link
Thanks. The FurMark power graph has been put back where it belongs.schizoide - Thursday, February 7, 2019 - link
Man, I've never seen such a hostile response to an Anandtech article. People need to relax, it's just a videocard.I don't see this as a win for AMD. Using HBM2 the card is expensive to produce, so they don't have a lot of freedom to discount it. Without a hefty discount, it's louder, hotter, and slower than a 2080 at the same price. And of course no ray-tracing, which may or may not matter, but I'd rather have it just in case.
For OpenCL work it's a very attractive option, but again, that's a loser for AMD because they ALREADY sold this card as a workstation product for a lot more money. Now it's discounted to compete with the 2080, meaning less revenue for AMD.
Even once the drivers are fixed, I don't see this going anywhere. It's another Vega64.
sing_electric - Thursday, February 7, 2019 - link
There's still a lot of people for whom a Radeon Instinct was just never going to happen, INCLUDING people who might have a workstation where they write code that will mostly run on servers, and it means you can run/test your code on your workstation with a fairly predictable mapping to final server performance.As Nate said in the review, it's also very attractive to academics, which benefits AMD in the long run if say, a bunch of professors and grad students learn to write ML/CL on Radeon before say, starting or joining companies.
schizoide - Thursday, February 7, 2019 - link
Yes, it's attractive to anyone who values OpenCL performance. They're getting workstation-class hardware on the cheap. But that does devalue AMD's workstation productline.Manch - Thursday, February 7, 2019 - link
Not really. The instinct cards are still more performant. They tend to be bought by businesses where time/perf is more important than price/perf.