The iPhone XS & XS Max Review: Unveiling the Silicon Secrets
by Andrei Frumusanu on October 5, 2018 8:00 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- iPhone XS
- iPhone XS Max
The A12 Vortex CPU µarch
When talking about the Vortex microarchitecture, we first need to talk about exactly what kind of frequencies we’re seeing on Apple’s new SoC. Over the last few generations Apple has been steadily raising frequencies of its big cores, all while also raising the microarchitecture’s IPC. I did a quick test of the frequency behaviour of the A12 versus the A11, and came up with the following table:
| Maximum Frequency vs Loaded Threads Per-Core Maximum MHz |
||||||
| Apple A11 | 1 | 2 | 3 | 4 | 5 | 6 |
| Big 1 | 2380 | 2325 | 2083 | 2083 | 2083 | 2083 |
| Big 2 | 2325 | 2083 | 2083 | 2083 | 2083 | |
| Little 1 | 1694 | 1587 | 1587 | 1587 | ||
| Little 2 | 1587 | 1587 | 1587 | |||
| Little 3 | 1587 | 1587 | ||||
| Little 4 | 1587 | |||||
| Apple A12 | 1 | 2 | 3 | 4 | 5 | 6 |
| Big 1 | 2500 | 2380 | 2380 | 2380 | 2380 | 2380 |
| Big 2 | 2380 | 2380 | 2380 | 2380 | 2380 | |
| Little 1 | 1587 | 1562 | 1562 | 1538 | ||
| Little 2 | 1562 | 1562 | 1538 | |||
| Little 3 | 1562 | 1538 | ||||
| Little 4 | 1538 | |||||
Both the A11 and A12’s maximum frequency is actually a single-thread boost clock – 2380MHz for the A11’s Monsoon cores and 2500MHz for the new Vortex cores in the A12. This is just a 5% boost in frequency in ST applications. When adding a second big thread, both the A11 and A12 clock down to respectively 2325 and 2380MHz. It’s when we are also concurrently running threads onto the small cores that things between the two SoCs diverge: while the A11 further clocks down to 2083MHz, the A12 retains the same 2380 until it hits thermal limits and eventually throttles down.
On the small core side of things, the new Tempest cores are actually clocked more conservatively compared to the Mistral predecessors. When the system just had one small core running on the A11, this would boost up to 1694MHz. This behaviour is now gone on the A12, and the clock maximum clock is 1587MHz. The frequency further slightly reduces to down to 1538MHz when there’s four small cores fully loaded.
Much improved memory latency
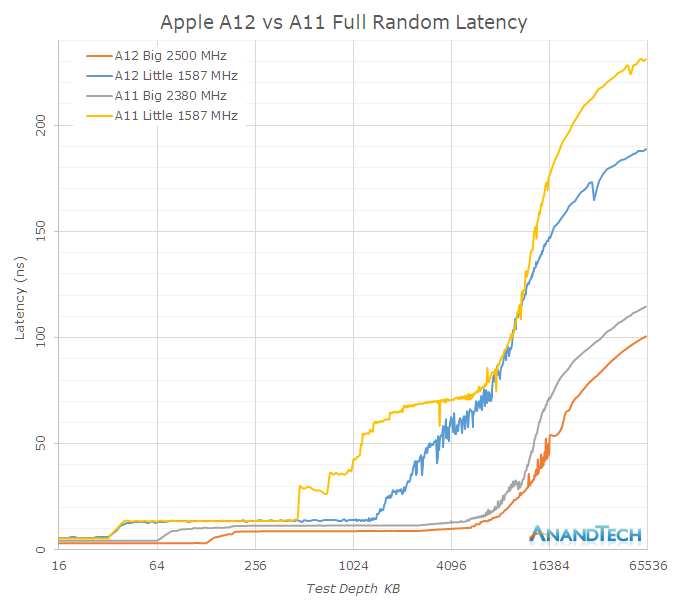
As mentioned in the previous page, it’s evident that Apple has put a significant amount of work into the cache hierarchy as well as memory subsystem of the A12. Going back to a linear latency graph, we see the following behaviours for full random latencies, for both big and small cores:
The Vortex cores have only a 5% boost in frequency over the Monsoon cores, yet the absolute L2 memory latency has improved by 29% from ~11.5ns down to ~8.8ns. Meaning the new Vortex cores’ L2 cache now completes its operations in a significantly fewer number of cycles. On the Tempest side, the L2 cycle latency seems to have remained the same, but again there’s been a large change in terms of the L2 partitioning and power management, allowing access to a larger chunk of the physical L2.
I only had the test depth test up until 64MB and it’s evident that the latency curves don’t flatten out yet in this data set, but it’s visible that latency to DRAM has seen some improvements. The larger difference of the DRAM access of the Tempest cores could be explained by a raising of the maximum memory controller DVFS frequency when just small cores are active – their performance will look better when there’s also a big thread on the big cores running.
The system cache of the A12 has seen some dramatic changes in its behaviour. While bandwidth is this part of the cache hierarchy has seen a reduction compared to the A11, the latency has been much improved. One significant effect here which can be either attributed to the L2 prefetcher, or what I also see a possibility, prefetchers on the system cache side: The latency performance as well as the amount of streaming prefetchers has gone up.
Instruction throughput and latency
| Backend Execution Throughput and Latency | ||||||||
| Cortex-A75 | Cortex-A76 | Exynos-M3 | Monsoon | Vortex | |||||
| Exec | Lat | Exec | Lat | Exec | Lat | Exec | Lat | |
| Integer Arithmetic ADD |
2 | 1 | 3 | 1 | 4 | 1 | 6 | 1 |
| Integer Multiply 32b MUL |
1 | 3 | 1 | 2 | 2 | 3 | 2 | 4 |
| Integer Multiply 64b MUL |
1 | 3 | 1 | 2 | 1 (2x 0.5) |
4 | 2 | 4 |
| Integer Division 32b SDIV |
0.25 | 12 | 0.2 | < 12 | 1/12 - 1 | < 12 | 0.2 | 10 | 8 |
| Integer Division 64b SDIV |
0.25 | 12 | 0.2 | < 12 | 1/21 - 1 | < 21 | 0.2 | 10 | 8 |
| Move MOV |
2 | 1 | 3 | 1 | 3 | 1 | 3 | 1 |
| Shift ops LSL |
2 | 1 | 3 | 1 | 3 | 1 | 6 | 1 |
| Load instructions | 2 | 4 | 2 | 4 | 2 | 4 | 2 | |
| Store instructions | 2 | 1 | 2 | 1 | 1 | 1 | 2 | |
| FP Arithmetic FADD |
2 | 3 | 2 | 2 | 3 | 2 | 3 | 3 |
| FP Multiply FMUL |
2 | 3 | 2 | 3 | 3 | 4 | 3 | 4 |
| Multiply Accumulate MLA |
2 | 5 | 2 | 4 | 3 | 4 | 3 | 4 |
| FP Division (S-form) | 0.2-0.33 | 6-10 | 0.66 | 7 | >0.16 | 12 | 0.5 | 1 | 10 | 8 |
| FP Load | 2 | 5 | 2 | 5 | 2 | 5 | ||
| FP Store | 2 | 1-N | 2 | 2 | 2 | 1 | ||
| Vector Arithmetic | 2 | 3 | 2 | 2 | 3 | 1 | 3 | 2 |
| Vector Multiply | 1 | 4 | 1 | 4 | 1 | 3 | 3 | 3 |
| Vector Multiply Accumulate | 1 | 4 | 1 | 4 | 1 | 3 | 3 | 3 |
| Vector FP Arithmetic | 2 | 3 | 2 | 2 | 3 | 2 | 3 | 3 |
| Vector FP Multiply | 2 | 3 | 2 | 3 | 1 | 3 | 3 | 4 |
| Vector Chained MAC (VMLA) |
2 | 6 | 2 | 5 | 3 | 5 | 3 | 3 |
| Vector FP Fused MAC (VFMA) |
2 | 5 | 2 | 4 | 3 | 4 | 3 | 3 |
To compare the backend characteristics of Vortex, we’ve tested the instruction throughput. The backend performance is determined by the amount of execution units and the latency is dictated by the quality of their design.
The Vortex core looks pretty much the same as the predecessor Monsoon (A11) – with the exception that we’re seemingly looking at new division units, as the execution latency has seen a shaving of 2 cycles both on the integer and FP side. On the FP side the division throughput has seen a doubling.
Monsoon (A11) was a major microarchitectural update in terms of the mid-core and backend. It’s there that Apple had shifted the microarchitecture in Hurricane (A10) from a 6-wide decode from to a 7-wide decode. The most significant change in the backend here was the addition of two integer ALU units, upping them from 4 to 6 units.
Monsoon (A11) and Vortex (A12) are extremely wide machines – with 6 integer execution pipelines among which two are complex units, two load/store units, two branch ports, and three FP/vector pipelines this gives an estimated 13 execution ports, far wider than Arm’s upcoming Cortex A76 and also wider than Samsung’s M3. In fact, assuming we're not looking at an atypical shared port situation, Apple’s microarchitecture seems to far surpass anything else in terms of width, including desktop CPUs.








253 Comments
View All Comments
Andrei Frumusanu - Saturday, October 6, 2018 - link
Eh no, it's single thread comparisons everywhere.Alistair - Saturday, October 6, 2018 - link
Thank you for making that clear. See my below comment with links, I put your data into a chart to compare. Is it fair to say IPC for the A12 in integers, is up to 64 percent faster?Hifihedgehog - Saturday, October 6, 2018 - link
Awesome! Thanks for the clarification. So my own education, is SPECint2006 a single-threaded test by its very nature? Can it be configured for multithreaded as well? If so, do you have multithreaded results forthcoming as well? I would love to see where Apple falls in this benchmark in that area as well.Andrei Frumusanu - Saturday, October 6, 2018 - link
SPECspeed is the score of running a single instance, SPECrate is running as many as there are cores on a system.It's not possible to run SPECrate on iOS anyhow without some very major hacky modifications of the benchmark because of the way it's ported without running in its own process. For Android devices it's possible, but I never really saw much interest or value for it.
Hifihedgehog - Saturday, October 6, 2018 - link
What about joules and watts? This is what is confusing me now. Something that seems a bit suspect to me is that the average energy and joule totals are not consistently lower together. That is, expect a device that has a lower average power usage to over the duration of the test to draw less total joules of energy. Mathematically speaking, I would naturally expect this especially in the case of higher benchmark scores since the lower power would be over a shorter space of time, meaning less total energy drawn.Andrei Frumusanu - Saturday, October 6, 2018 - link
The amount of Joules drawn depends on the average power and performance (time) of the benchmark.If a CPU uses 4 watts and gives 20 performance (say 5 minute to complete), it will use less energy than a CPU using 2 watts and giving 8 performance (12.5 minutes to complete), for example.
Dredd67 - Saturday, October 6, 2018 - link
I live in France and have to deal with intel radios since a while. I'm totally baffled to read all the comments about poor reception, dropped calls, wifi going crazy like this is news.This problem has been there since the beginning of Apple using intel chips ! It's just now that Americans have to use them also that it might finallybe adressed (please keep complaining, raise awareness, file a class action, whatever it takes) but you don't realize the pain these past years have been using an iphone elsewhere in the world...
For the record, I just gave my 7 (intel chip) to my daughter who broke here phone and reverted back to an old 6plus I kept for such cases (it also uses qualcomm). In the family I'm now the only only getting rock solid wifi, no dropped calls, consistent signal strenght, on a 4+ years old phone. And all this time I thought my carrier was messing around, my orbis were crap, or I just fumbled with my router settings.
Shame on you Apple, shame on you.
Oh and don't get me started on the camera: is this really what people want ? I think it's getting worse and worse, not better. Completely artifical images, looking more like cartoons than photographs. Same for Samsung and Google's phones. Hav a look at the P20 pro for a reality check. This is what photos should look like (contrast, colors - not really dependant on the sensor size).
Great review though.
ex2bot - Sunday, October 7, 2018 - link
The Halite app devs showed off an interesting technique they’re using or working on for the XS they call SmartRAW that may offer more control over the over saturation / lower contrast issues, etc.s.yu - Monday, October 8, 2018 - link
"Hav a look at the P20 pro for a reality check."?Your reality is the smeared textureless crap with oversharpening contours along object edges? Unbelievable.
serendip - Saturday, October 6, 2018 - link
Could these amazing CPU gains be translated to a midrange chip? Technically Android could run on Apple SoCs because they're all ARM licensed cores but porcines would gain flying abilities before that ever happened.It's too bad Android users are stuck with the best that ARM and Qualcomm can do, which isn't much compared to Apple's semi design team.