ATI Radeon X800 Pro and XT Platinum Edition: R420 Arrives
by Derek Wilson on May 4, 2004 10:28 AM EST- Posted in
- GPUs
The Pixel Shader Engine
On par with what we have seen from NVIDIA, ATI's top of the line card is offering a GPU with a 16x1 pixel pipeline architecture. This means that it is able to render up to 16 single textured pixels in parallel per clock. As previously alluded to, R420 divides its pixel pipes into groups of four called quads. The new line of ATI GPUs will offer anywhere from one to four quad pipelines. The R3xx architecture offers an 8x1 pixel pipeline layout (grouped into two quad pipelines), delivering half of R420's pixel processing power per clock. For both R420 and R3xx, certain resources are shared between individual pixel pipelines in each quad. It makes a lot of sense to share local memory among quad members, as pixels near eachother on the screen should have (especially texture) data with a high locality of reference. At this level of abstraction, things are essentially the same as NV40's architecture.
Of course, it isn't enough to just look how many pixel pipelines are available: we must also discover how much work each pipeline is able to get done. As we saw in our final analysis of what went wrong with NV3x, the internals of a shader unit can have a very large impact on the ability of the GPU to schedule and execute shader code quickly and efficiently.
At our first introduction, the inside of R420's pixel pipeline was presented as a collection of 2 vector units, 2 scalar units, and one texture unit that can all work in parallel. We've seen the two math and one texture layout of NV40's pixel pipeline, but does this mean that R420 will be able to completely blow NV40 out of the water? In short, no: it's all about what kind of work these different units can do.
Lifting up the hood, we see that ATI has taken a different approach to presenting their architecture than NVIDIA. ATI's presentation of 2 vector units (which are 3 wide at 72bits), 2 scalar units (24bits), and a texture unit may be more reflective of their implementation than what NVIDIA has shown (but we really can't know this without many more low level details). NVIDIA's hardware isn't quite as straight forward as it may end up looking to software. The fact is that we could look at the shader units in NV40's pixel pipeline in the same way as ATI's hardware (with the exception of the fact that the texture unit shares some functionality with one of the math units). We could also look at NV40 architecture as being 4 2-wide vector units or 2 4-wide vector units (though this is still an over simplification as there are special cases NVIDIA's compiler can exploit that allow more work to be done in parallel). If ATI had decided to present it's architecture in the same way as NVIDIA, we would have seen 2 shader math units and one completely independent texture unit.
In order to gain better understanding, here is a diagram of the parallelism and functionality of the shader units within the pixel pipelines of R420 and NV40:
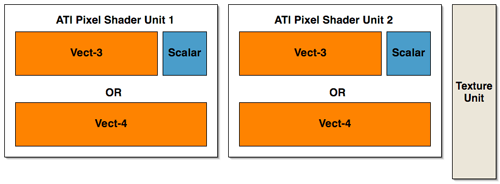
ATI has essentially three large blocks that can push up to 5 operations per clock cycle
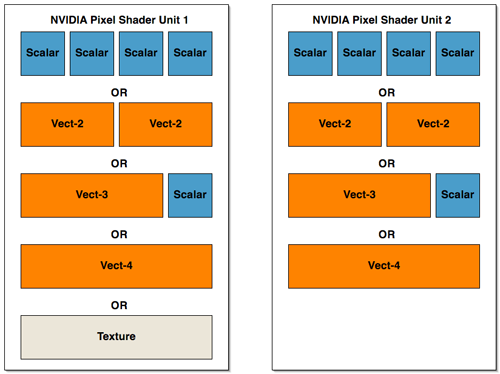
NV40 can be seen two blocks of a more amorphous configuration (but there are special cases that allow some of these parts to work at the same time within each block.
Interestingly enough, there haven't been any changes to the block diagram of a pixel pipeline at this level of detail from R3xx to R420.
The big difference in the pixel pipe architectures that gives the R420 GPU a possible upper hand in performance over NV40 is that texture operations can be done entirely in parallel with the other math units. When NV40 needs to execute a texture operation, it looses much of its math processing power (the texturing unit cannot operate totally independently of the first shader unit in the NV40 pixel pipeline). This is also a feature of R3xx that carried over to R420.
![]()
Understanding what this all means in terms of shader performance depends on the kind of code developers end up writing. We wanted to dedicate some time to hand mapping some shader code to both architecture's pixel pipelines in order to explain how each GPU handled different situations. Trial and error have led us to the conclusion that video card drivers have their work cut out for them when trying to optimize code; especially for NV40. There are multiple special cases that allow NVIDIA's architecture to schedule instructions during texturing operations on the shared math/texture unit, and some of the "OR" cases from our previous diagram of parallelism can be massaged into "and" cases when the right instructions are involved. This also indicates that performance gains due to compiler optimizations could be in NV40's future.
Generally, when running code with mixed math and texturing (with a little more math than texturing) ATI will lead in performance. This case is probably the most indicative of real code.
The real enhancements to the R420 pixel pipeline are deep within the engine. ATI hasn't disclosed to us the number of internal registers their architectures have, or how many pixels each GPU can maintain in flight at any given time, or even cache hit/miss latencies. We do know that, in addition to the extra registers (32 constant and 32 temp registers up from 12) and longer length shaders (somewhere between 512 and 1536 depending on what's being done) available to developers on R420, the number of internal registers has increased and the maximum number of pixels in flight has increased. These facts are really important in understanding performance. The fundamental layout of the pixel pipelines in R420 and NV40 are not that different, but the underlying hardware is where the power comes from. In this case, the number of internal pipeline stages in each pixel pipeline, and the ability of the hardware to hide the latency of a texture fetch are of the utmost importance.
The bottom line is that R420 has the potential to execute more PS 2.0 instructions per clock than NVIDIA in the pixel pipeline because of the way it handles texturing. Even though NVIDIA's scheduler can help to allow more math to be done in parallel with texturing, NV40's texture and math parallelism only approaches that of ATI. Combine that with the fact that R420 runs at a higher clock speed than NV40, and even more pixel shader work can get done in the same amount of time on R420 (which translates into the possibility for frames being rendered faster under the right conditions).
Of course, when working with fp32 data, NV40 is doing 25% more "work" per operation, and it's likely that the support for fp32 from the front of the shader pipeline to the back contributes greatly to the gap in the transistor count (as well as performance numbers). When fp16 is enabled in NV40, internal register pressure is decreased, and less work is being done than in fp32 mode. This results in improved performance for NV40, but questions abound as to real world image quality from NVIDIA's compiler and precision optimized shaders (we are currently exploring this issue and will be following up with a full image quality analysis of now current generation hardware).
As an extension of the fp32 vs. fp24 vs. fp16 debate, NV40's support of Shader Model 3.0 puts it at a slight performance disadvantage. By supporting fp32 all the way through the shader pipeline, flow control, fp16 to the framebuffer and all the other bells and whistles that have come along for the ride, NV40 adds complexity to the hardware, and size to the die. The downside for R420 is that it now lags behind on the feature set front. As we pointed out earlier, the only really new features of the R420 pixel shaders are: higher instruction count shader programs, 32 temporary registers, and a polygon facing register (which can help enable two sided lighting).
To round out the enhancements to the R420's pixel pipeline, ATI's F-Buffer has been tweaked. The F-Buffer is what ATI calls the memory that stores pixels that have come out of the pixel shader but still require another pass (or more) thorough the pixel shader pipeline in order to finish being processed. Since the F-Buffer can require anywhere from no memory to enough memory to handle every pixel coming down the pipeline, ATI have built "improved" memory management hardware into the GPU rather than relegating this task to the driver.








95 Comments
View All Comments
rms - Tuesday, May 4, 2004 - link
"the near-to-be-released goodlooking PS 3.0 Far Cry update "When is that patch scheduled for? I recall seeing some rumour it was due in September...
rms
Fr0zeN - Tuesday, May 4, 2004 - link
Yeah I agree, the GT looks like it's gonna give the x800P a run for its money. On a side note, the differences between P and XT versions seem to be greater than r9800's, hmm.In the end it's the most overclockable $200 card that'll end up in my comp. There's no way I'm paying $500 for something that I can compensate for by turning the rez down to 10x7... Raw benchmarks mean nothing if it doesn't oc well!
Doop - Tuesday, May 4, 2004 - link
The cards seem very close, I tend to favor nVidia now since they have superior multi monitor and professional 3D drivers and I regret buying my Fire GL X1.It's strange ATi didn't announce a 16 pipeline card orginally, it will be interesting to see in a month or two who actually ends up delivering cards.
I mean if they're being made in significant quantities they'll be at your local store with a reduced 'street' price but if it's just a paper launch they'll just be at Alienware, Dell (with a new PC only) or $500 if you can find one.
jensend - Tuesday, May 4, 2004 - link
#17, the Serious Engine has nothing to do with the Q3 engine; Nvidia's superior OpenGL performance is not dependent on any handful of engines' particular quirks.Zobar is right; contra Jibbo, the increased flexibility of PS3 means that for many 2.0 shader programs a PS3 version can achieve equivalent results with a lesser performance hit.
As far as power goes, I'm surprised NV made such a big deal out of PSU requirements, as its new cards (except the 6800U Extremely Short Production Run Edition/6850U/Whatever they end up calling that part) compare favorably wattage-wise to the 5950U and don't pull all that much more power than the 9800XT. Both companies have made a big performance per watt leap, and it'll be interesting to see how the mid-range and value cards compare in this respect.
blitz - Tuesday, May 4, 2004 - link
"Of course, we will have to wait and see what happens in that area, but depending on what the test results for our 6850 Ultra end up looking like, we may end up recommending that NVIDIA push their prices down slightly (or shift around a few specs) in order to keep the market balanced."It sounds as if you would be giving nvidia advice on their pricing strategy, somehow I don't think they would listen nor be influenced by your opinion. It could be better phrased that you would advise consumers to wait for prices to drop or look elsewhere for better price\performance ratio.
Cygni - Tuesday, May 4, 2004 - link
Hmmmm, interesting. I really dont see where anyone can draw the conclusion that the x800 Pro is CLEARLY the winner. The 6800 GT and x800 Pro traded game wins back and forth. There doesnt seem to be any clear cut winner to me. Wolf, JediA, X2, F1C, and AQ3 all went clearly to the GT... this isnt open and shut. Alot of the other tests were split depending on resolution/AA. On the other hand, I dont think you can say that the GT is clearly better than the x800 Pro either.Personally, I will buy whichever one hits a reasonable price point first. $150-200. Both seem to be pretty equal, and to me, price matters far more.
kherman - Tuesday, May 4, 2004 - link
BRING ON DOOM 3!!!!!!We all know inside that this is what ID was waiting for!
Diesel - Tuesday, May 4, 2004 - link
------------------I think it is strange that the tested X800XT is clocked at 520 Mhz, while the 6800U, that is manufactured by the same taiwanese company and also has 16 pipelines, is set at 400 Mhz.
------------------
This could be because NV40 has 222M transistors vs. R420 at 160M transistors. I think the amount of power required and heat generated is proportional to transistor count and clock speed.
edub82 - Tuesday, May 4, 2004 - link
I know this is an ATI article but that 6800 GT is looking very attractive. It beats the x800Pro on a fairly regular basis is a single slot and molex connector card and is starting at 400 and hopefully will go down a few dollars ;) in 6 months when i want to upgrade.Slaanesh - Tuesday, May 4, 2004 - link
"Clearly a developer can have much nicer quality and exotic effects if he/she exploits these, but how many gamers will have a PS3.0 card that will run these extremely complex shaders at high resolutions and AA/AF without crawling to single-digit fps? It's my guess that it will be *at least* a year until games show serious quality differentiation between PS2.0 and PS3.0. But I have been wrong in the past..."--------
I dunnow.. When Morrowind got released, only he few GF3 cards on the market were able to show the cool pixel shader water effects and they did it well; at that time I was really pissed I went for the cheaper Geforce2 Ultra although it had some better benchmarks at a much lower price. I don't think I want make that mistake again and pay the same amount of money for a card that doesnt support the latest technology..