Arm's Cortex-A76 CPU Unveiled: Taking Aim at the Top for 7nm
by Andrei Frumusanu on May 31, 2018 3:01 PM EST- Posted in
- CPUs
- Arm
- Smartphones
- Mobile
- SoCs
- Cortex-A76
Cortex A76 µarch - Frontend
Starting off with a rough overview of the Cortex A76 microarchitectural diagram we see the larger functional blocks. The A76 doesn’t look too different than other Arm processors in this regard and the differences come only with details that Arm is willing to divulge. To overly simplify it, this is a superscalar out-of-order core with a 4-wide decode front-end with 8 execution ports in the backend with a total implementation pipeline depth of 13 stages with the execution latencies of a 11 stage core.

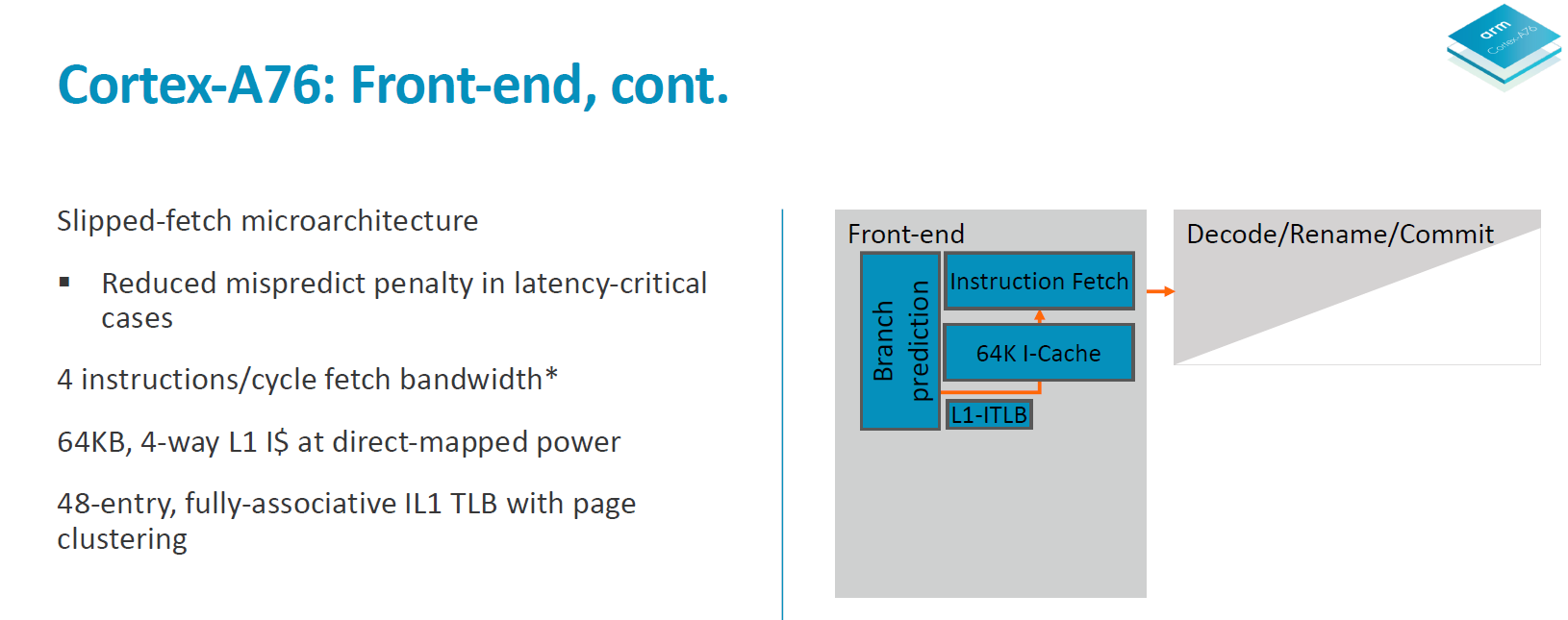
In the front-end, Arm has created a new predict/fetch unit that it calls a “predict-directed fetch”, meaning the branch prediction unit feeds into the instruction fetch unit. This is a divergence from past Arm µarches and it allows for both higher performance and lower power consumption.

The branch prediction unit is what Arm calls a first in the industry in adopting a hybrid indirect predictor. The predictor is decoupled from the fetch unit and its supporting large structures operate separate from the rest of the machine – likely what this means is that it will be easier to clock-gate during operation to save on power. The branch predictor is supported by 3-level branch target caches; a 16-entry nanoBTB, a 64-entry microBTB and a 6000 entry main BTB. Arm claimed back in the A73 and A75 generations of branch predictors were able to nearly predict all taken branches so this new unit in the A76 seems to be one level above that in capability.
The branch unit operates at double the bandwidth of the fetch unit – it operates on 32B/cycle meaning up to 8 32b instructions per cycle. This feeds a fetch queue in front of the instruction fetch consisting of 12 “blocks”. The fetch unit operates at 16B/cycle meaning 4 32b instructions. The branch unit operating at double the throughput makes it possible to get ahead of the fetch unit. What this serves is that in the case of a mispredict it can hide branch bubbles in the pipeline and avoid stalling the fetch unit and the rest of the core. The core is said to able to cope with up to 8 misses on the I-side.
I mentioned at the beginning that the A76 is a 13-stage implementation with the latency of an 11-stage core. What happens is that in latency-critical paths the stages can be overlapped. One such cycle happens between the second cycle of the branch predict path and the first cycle of the fetch path. So effectively while there’s 4 (2+2) pipeline stages on the branch and fetch, the core has latencies of down to 3 cycles.
On the decode and rename stages we see a throughput of 4 instructions per cycle. The A73 and A75 were respectively 2 and 3-wide in their decode stages so the A76 is 33% wider than the last generation in this aspect. It was curious to see the A73 go down in decode width from the 3-wide A72, but this was done to optimise for power efficiency and “leanness” of the pipeline with goals of improving the utilisation of the front-end units. With the A76 going 4-wide, this is also Arms to date widest microarchitecture – although it’s still extremely lean when putting it into juxtaposition with competing µarches from Samsung or Apple.
The fetch unit feeds a decode queue of up to 16 32b instructions. The pipeline stages here consist of 2 cycles of instruction align and decode. It looks here Arm decided to go back to a 2-cycle decode as opposed to the 1-cycle unit found on the A73 and A75. As a reminder the Sophia cores still required a secondary cycle on the decode stage when handling instructions utilising the ASIMD/FP pipelines so Arm may have found other optimisation methods with the A76 µarch that warranted this design decision.
The decode stage takes in 4 instructions per cycle and outputs macro-ops at an average ratio of 1.06Mops per instruction. Entering the register rename stage we see heavy power optimisation as the rename units are separated and clock gated for integer/ASIMD/flag operations. The rename and dispatch are a 1 cycle stage which is a reduction from the 2-cycle rename/dispatch from the A73 and A75. Macro-ops are expanded into micro-ops at a ratio of 1.2µop per instruction and we see up to 8µops dispatched per cycle, which is an increase from the advertised 6µops/cycle on the A75 and 4µops/cycle on the A73.
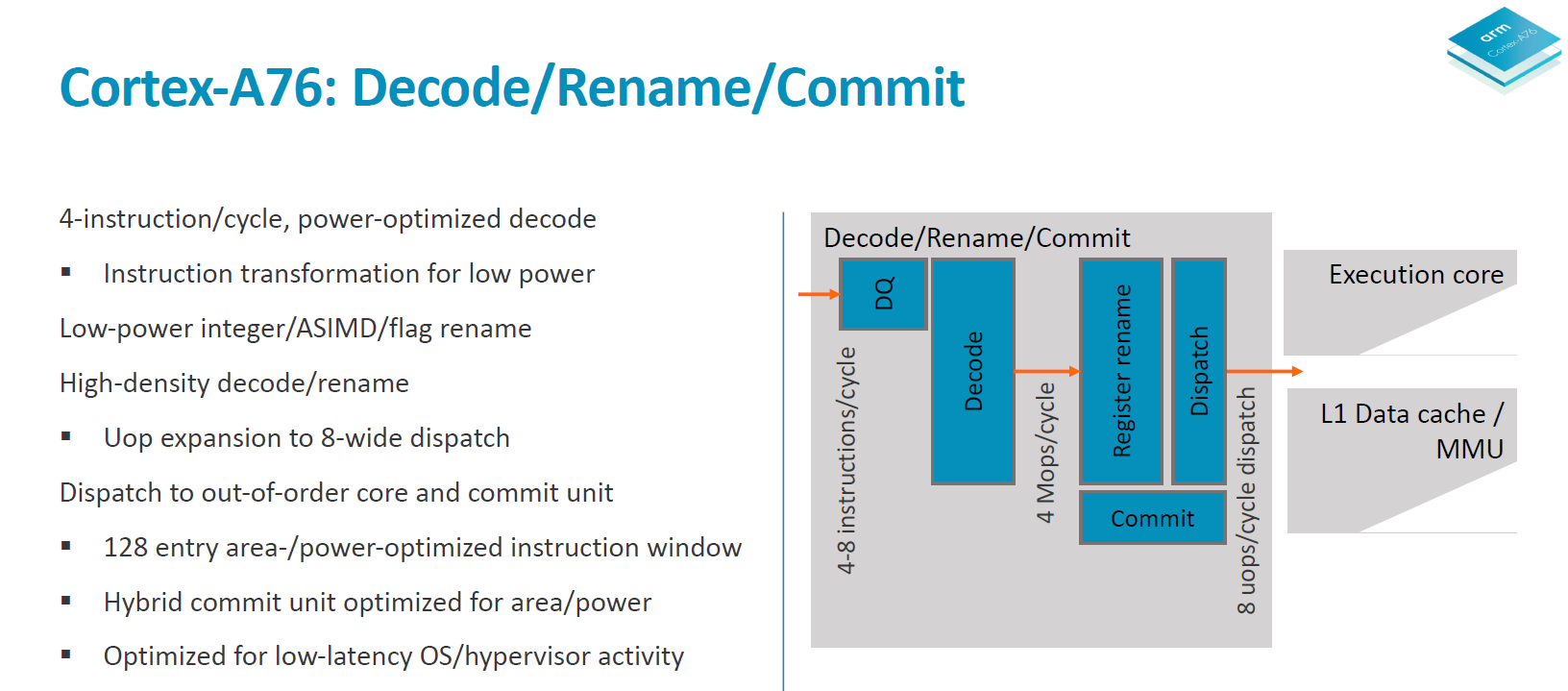
The out-of-order window commit size of the A76 is 128 and the buffer is separated into two structures responsible for instruction management and register reclaim, called a hybrid commit system. Arm here made it clear that it wasn’t focusing on increasing this aspect of the design as it found it as a terrible return on investment when it comes to performance. It is said that the performance scaling is 1/7th – meaning a 7% increase of the reorder buffer only results in a 1% increase in performance. This comes at great juxtaposition compared to for example Samsung's M3 cores with a very large 224 ROB.
As a last note on the front-end, Arm said to have tried to optimised the front-end for lowest possible latency for hypervisor activity and system calls, but didn’t go into more details.








123 Comments
View All Comments
vladx - Friday, June 1, 2018 - link
That's weird, in most speed tests I've seen Android flagships beat iPhones in all but graphics-intensive apps like games and video editing.varase - Saturday, June 2, 2018 - link
Those tests are usually serially launching a bunch of apps, then round-robining.It's probably more a demonstration that Android phones have more RAM.
StrangerGuy - Sunday, June 3, 2018 - link
Yup, that totally has to do with hardware and not thing to do with UI optimizations and design choices = Apple sux lololBut hey, somebody in this world needs to get their daily dose of retarded Youtube clickbait shit videos. Bonus originality points when it's Apple-hating.
jospoortvliet - Wednesday, June 6, 2018 - link
Yeah, app developers make sure to keep the Android versions lighter to not let performance completely fall apart on all the many cheap 8x a53 SOC's out there... fi d a real equivalent app that does heavy stuff like render a large pdf or generate video's out of a bunch of pics and videos. I mean, really the same. Not sure if faster CPU and storage will not make a huge diff then...B3an - Thursday, May 31, 2018 - link
Do Anandtech writers know the meaning of the word "several"? I keep seeing it said on here, when you actually mean a "couple" or a "few" because you mean 2 or 3.StormyParis - Friday, June 1, 2018 - link
"several" means "more than one" so I'm not sure who's having a vocabulary issue. Or rather, I am.nico_mach - Friday, June 1, 2018 - link
In American English, it's coloquially taken as meaning more than a few (sounds like seven and his progression is correct, couple<few<several). But it's not universally understood that way. Several is perfectly understandable imo.If you want to quibble, the phrase 'my projects' in the third to last paragraph should be 'my projections'.
Gunbuster - Thursday, May 31, 2018 - link
Someone forget to update the PowerPoint deck full of "Laptop class performance" after the big nothing burger that is win 10 on ARM?nico_mach - Friday, June 1, 2018 - link
That was such a disappointing set of products. Just the price of them for the performance and spec.lilmoe - Thursday, May 31, 2018 - link
Nope. Still don't agree that efficiency at max clocks is indicator of anything in a smartphone form factor. Total power draw per worked is where it's at.This announcement shouldn't be comparable with the current 9810. I don't believe the a76 would fair well on 10nm, and definitely not in a quad core - high cache configuration. Samsung rushed the design; neither the OS/firmware nor the process were ready for that chip, but it still was competitive, despite not being to my liking. It would have kicked butt running windows on arm though.
The a76 and a12 at 7nm will be competing against the m4 at 7nm EUV. I don't want to get ahead of myself, but I have my money on Samsung. Here's to a GS10 released in one SoC configuration without holding any of its features or performance back.