Arm's Cortex-A76 CPU Unveiled: Taking Aim at the Top for 7nm
by Andrei Frumusanu on May 31, 2018 3:01 PM EST- Posted in
- CPUs
- Arm
- Smartphones
- Mobile
- SoCs
- Cortex-A76
Performance & Power Projections
Now that we’ve had more insight into the A76’s microarchitecture – there’s always a disconnect between theoretical performance based on overlying µarch and how it ends up in practice. We’re first going to look at ISO-process and ISO-frequency comparisons which means the generational performance improvements between the cores with otherwise identical factors such as memory subsystems.
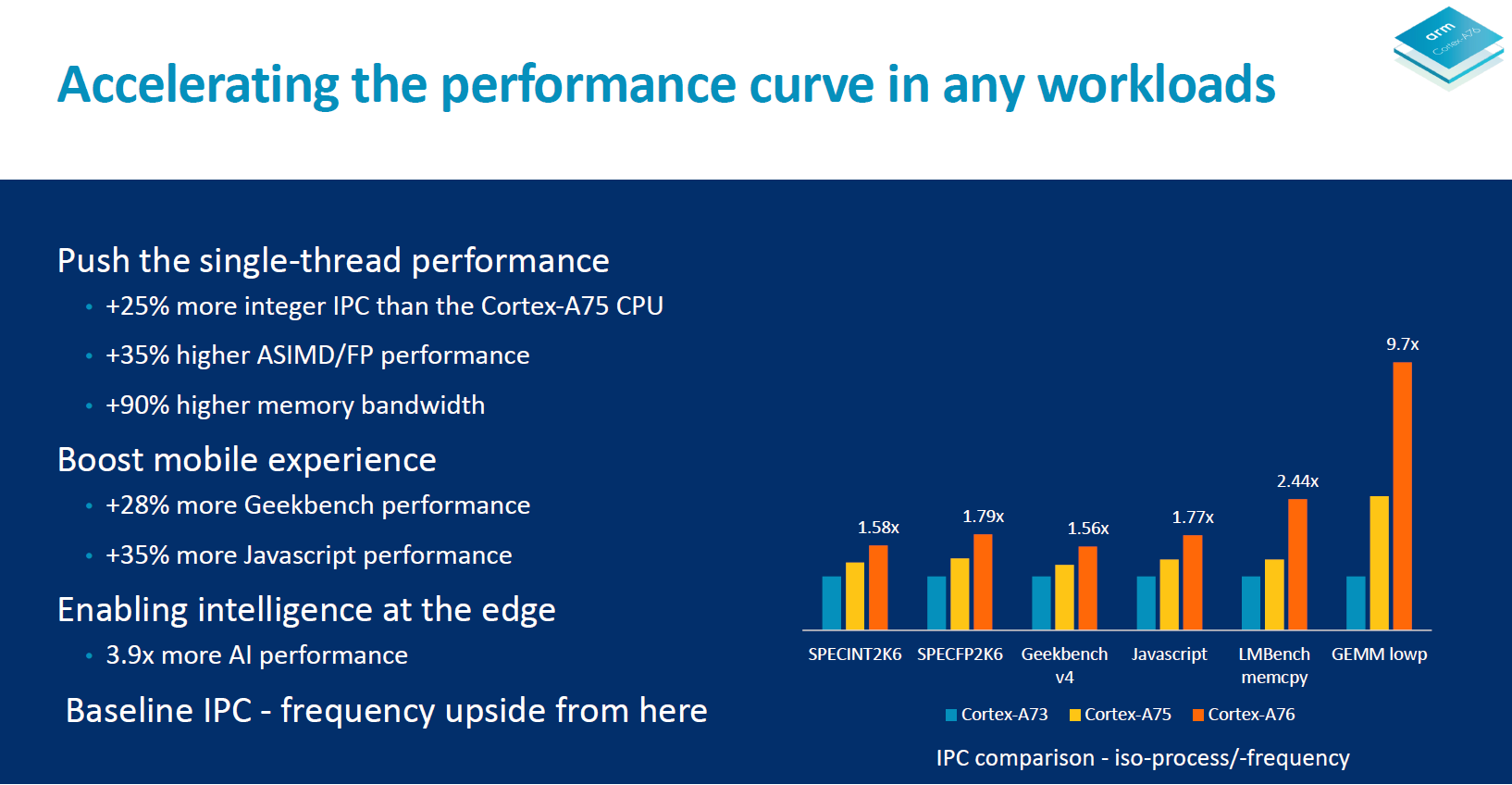
In terms of general IPC Arm promises a ~25% increase in integer workloads and a ~35% increase in ASIMD/floating point workloads. Together with up to 90% higher memory bandwidth figures compared to the A75 the A76 is then meant to provide around a 28% increase in GeekBench4 and 35% more JavaScript performance (Octane, JetStream). In AI inferencing workloads the doubled ASIMD 128-bit capabilities of the A76 serves to quadruple the general matrix multiply performance in half precision formats.
These performance figures are respectable but not quite earth-shattering considering the tone of the improvements of the µarch. However it’s to note that we’re expecting the A76 to come first be deployed in flagship SoCs on TSMC’s 7nm process which allows for increased clocks.

Here Arm’s projections is that we’ll be seeing the A76 clocked at up to 3GHz on 7nm, which in turn will result in higher improvements. Quoted figures are 1.9x in integer and 2.5x in floating point subscores of GeekBench4 while we should be expecting total score increases of 35%.
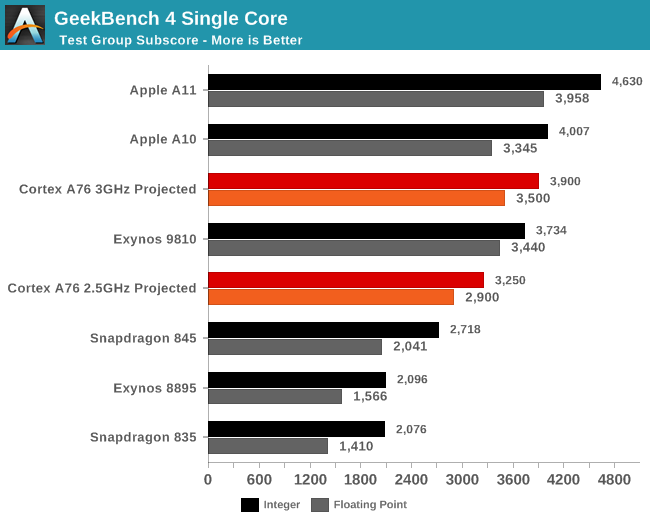
What this means in terms of absolute numbers is projected in the above graph. Baselining on the performance of the Snapdragon 835 and Snapdragon 845 a future SoC with an A76, 512KB L2’s and 2MB L3 would fall in around the GeekBench4 performance of the Exynos 9810 depending if the target 3GHz is reached.
In the past Arm has been overly optimistic when releasing frequency targets – for example the A73 was first projected at up to 2.8GHz and the Cortex A75 projected at up to 3GHz. In the end both ended up at no higher than 2.45GHz and 2.8GHz.
I’ve talked to a vendor about this and it seems Arm doesn’t take into consideration all corners when doing timing signoff, and in particular vendors have to take into consideration process variations which result in differently binned units, some of which might not reach the target frequencies. As mobile chips generally aren’t performance binned but rather power binned, vendors need to lower the target clock to get sufficient volume for commercialisation which results in slightly reduced clocks compared to what Arm usually talks about.
For the first A76 implementations in mobile devices I’m adamant that we won’t be seeing 3GHz SKUs but rather frequencies around 2.5GHz. Arm is still confident that we’ll see 3GHz SoCs but I’m going to be rather on the conservative side and be talking about 2.5GHz and 3GHz projections alongside each other, with the latter more of a projection of future higher TDP platforms.
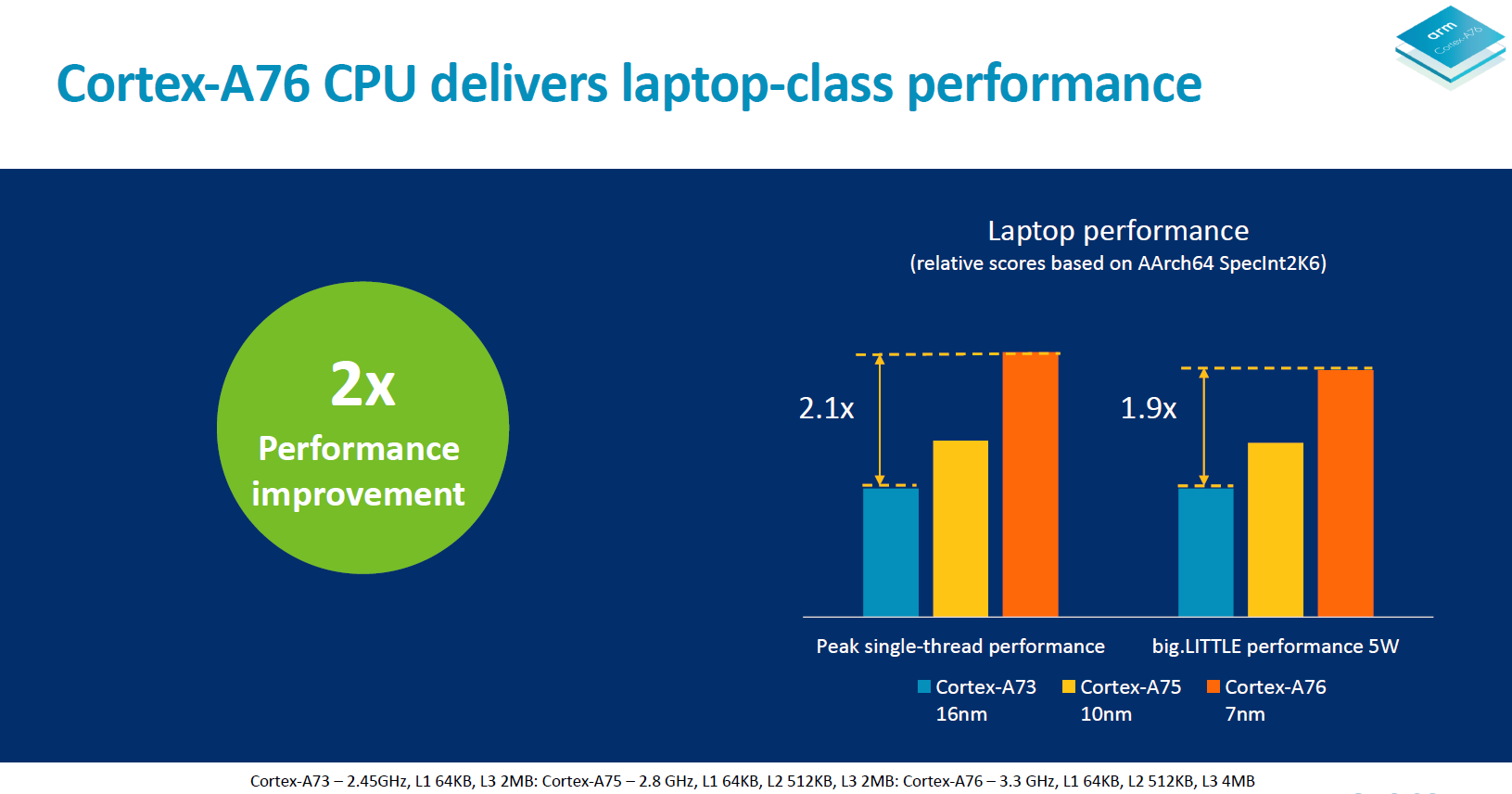
Arm also had a slide demonstrating absolute peak performance at frequencies of 3.3GHz. The important thing to note here was that this scenario exceeded 5W and the performance would be reduced to get under that TDP target. It wasn’t clear if this was SoC power or solely CPU power – I’ll follow up with a clarification after I reach out to Arm.

Obviously the most important metric here alongside the performance improvements is the power and efficiency targets. In target products comparing Cortex A75 on a 10nm process versus a Cortex A76 on a 7nm process under the same 750mW/core power budget, the Cortex A76 delivers 40% more performance.
In terms of energy efficiency, a 7nm A76 at a performance target of 20 SPECint2006 of an A75 on 10nm (meaning maximum performance at 2.8GHz) is said to use half the amount of energy.
What is important in all these metrics again is that we weren’t presented an ISO-process comparison or a comparison at maximum performance of the A76 at 3GHz, so we’re left with quite a bit of guesswork in terms of projecting the end energy efficiency difference in products. TSMC promises a 40% drop in power versus 10FF. We haven’t seen an A75 implemented on a TSMC process to date so the best baseline we have is Qualcomm’s Snapdragon 845 on Samsung 10LPP which should slightly outperform 10FF.
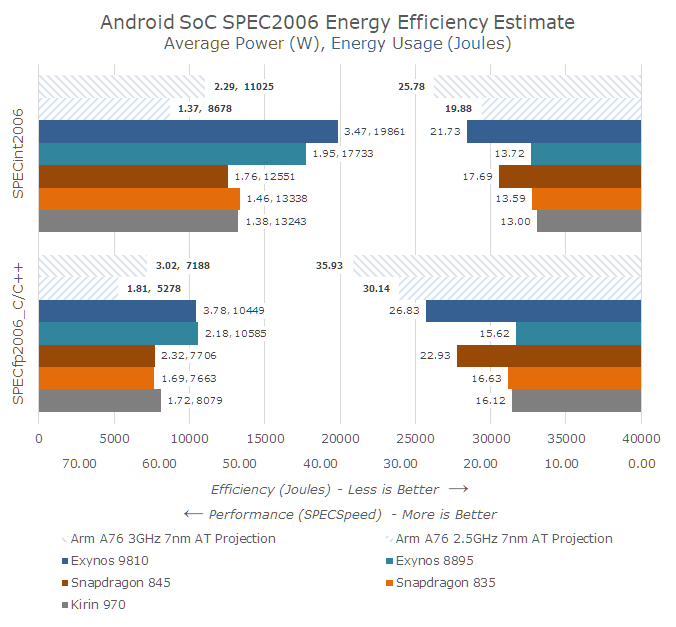
Going through my projected data on one side we have performance on the right side: I baselined the SPECspeed scores on the average of the Snapdragon 835 and Kirin 970 measured results and applied Arm’s projected IPC claims and scaled the scores for frequency. For the 3GHz A76 projection this gets us the near 2x performance improvements in SPECint2006 vs the A73 generation of cores.
In terms of power efficiency, there’s more guesswork as the only real figure we have is as earlier stated the process scaled efficiency figures. Arm quoted a performance target of 20 SPECint2006 which I suspect is a 2.8GHz A75 run with GCC compiled benchmark binaries which have an advantage over my LLVM figures. If Arm wanted to compare against the Snapdragon 845 this matches roughly a 2.4GHz A76. Accounting for the process power improvement this roughly leaves a ~15% microarchitectural advantage for the A76. However as the A76 is targeted to perform 35% higher, and as we’ve seen in the past performance increases through clock don’t scale linearly with power, the power and efficiency advantages would very quickly degrade at peak performance.
Taking all factor into account as best as I could, we should be seeing 7nm A76 based SoCs beat slightly beat the energy efficiency of current Arm SoCs in terms of absolute energy usage at peak performance, a metric which is important as it is directly proportional to a device’s battery life. At a more conservative 2.5GHz clock this energy efficiency advantage would be greater and around 30% less energy than current generation A73 and A75 SoCs.
So on one hand the A76 would be extremely energy efficient, but also it could very well be a thermally constrained design as its peak performance we’d be seeing quite higher TDP figures. Arm states that the A76 is meant to run at full frequency in quad-core mode, however that claim is limited to larger form-factors, as for mobile devices, based on what I’m hearing vendors, will need to tone it down to lower clocks in order to fit smartphone designs.
Again the projection here contain a lot of variables and I’m erring towards the more conservative side in terms of performance and efficiency- however it’s clear that the jump will be significant in whichever way vendors will decide to push the A76 in (Performance or efficiency).














123 Comments
View All Comments
name99 - Friday, June 1, 2018 - link
FFS. the issue is NOT "Older batteries might not be able to supply enough power for a big core", it is that the battery cannot supply enough CURRENT.If you can't be bothered to understand the underlying engineering issue and why the difference between current and power matters, then your opinions on this issue are worthless.
serendip - Friday, June 1, 2018 - link
Whoa, chill there buddy, I'm not an electrical engineer.name99 - Friday, June 1, 2018 - link
"Does anyone actually use the full performance of the A11 or A12 in daily tasks? "Absolutely. I've updated iPhones every two years, and every update brings a substantial boost in "fluidity" and just general not having to wait. I can definitely feel the difference between my iPhone 7 and my friend's iPhone X; and I expect I will likewise feel the difference when I get my iPhone 2018 edition (whatever they are naming them this year...)
Now if you want to be a tool, you can argue "that's because Apple's software sux. Bloat, useless animations, last good version of iOS was version 4, blah blah". Whatever.
MOST people find more functionality distributed throughout the dozens of little changes of each new version of the OS, and MOST people find the "texture" of the OS (colors, animations, etc) more pleasant than having some sort of text only Apple II UI, though doubtless that could run at a 10,000 fps.
So point is, yeah, you DO notice the difference on phones. Likewise on iPads. I use my iPad to read technical PDFs, and again, each two year update provides a REALLY obvious jump in how quickly complicated PDF pages render. With my very first iPad 1 there was a noticeable wait almost every page (only hidden, usually, because of page caching). By the A10X iPad Pro it's rare to encounter a PDF page that ever makes you wait, cached or not.
I've also talked about in the past about Wolfram Player, a subset of Mathematica for iPad. This allows you to interact with Mathematica "animations" (actually they're 3D interactive objects you construct that change what is displayed depending on how you move sliders or otherwise tweak parameters). These are calculating what's to be displayed (which might be something like numerically solving a partial differential equation, then displaying the result as a 3D object) in realtime as you move a slider.
Now this is (for now) pretty specialized stuff. But Wolfram's goal, as they fix the various bugs in the app and implement the bits of Mathematica that don't yet work well (or at all), is for these things to be the equivalent of video today. We used to put up with explanations (in books, or newspapers) that were just words. Then we got BW diagrams. Then we got color diagrams. Then we got video. Now we have web sites like NYT and Vox putting up dynamic explainers where you can move sliders --- BUT they are limited to the (slow) performance of browsers, and are a pain to construct (both the UI, and the underlying mathematical simulation). Something like Mathematica's animations are vastly more powerful, and vastly easier to create. One day these will be as ubiquitous as video is today, just one more datatype that gets passed around. But for them to work well requires a CPU that can numerically solve PDEs in real time on your mobile device...
techconc - Tuesday, June 5, 2018 - link
The benefits of having a fast single core are seen on most common operations, including UI and scrolling, etc. Moreover, Apple has demonstrated that a powerful core can in fact be more efficient in race to sleep conditions whereby it completes the work more quickly then sleeps. The overall effect is a more responsive system that is just as efficient overall.tipoo - Tuesday, September 4, 2018 - link
Sure, every time I render a webpage.ZolaIII - Friday, June 1, 2018 - link
Well let's put it this way the A73 which is two instructions wide had a no problems on 14 nm FinFET, A76 is 4 instruction wide & for a sakes of argument let's say 2x the size. So switching from 14 nm to 7nm (60% reduction on power) cower it, A76 is approximately 65% faster than A73 MHz per MHz so its able to deliver approximately the 1.8x performance per same DTP. Second part is a manufacturing process in comparison to the core size. The FinFET structure transistors leak as hell when the 2.1~2.2 GHz limit is reached disregarding of OEM, vendor/foundry. So if you employ 50% wider core's (6 instructions wide) that won't cross the 2.1~2.2 GHz limit it's not the same as if you push the limit of the 4 instructions wide one to 3GHz as the power consumption will be doubled compared to the same one operating on 2.1~2.2 GHz & in the end you lose both on theoretical true output (performance) and power consumption metric but it still costs you 33% less. In reality it's much harder to feed optimally the wider core (especially on something which is mobile OS). ARM (cowboy camp) did a great work optimising instruction latency and cache latency/true output which will both increase real instruction output per clock & help predictor without significant increase in needed resources (cost - size) & A76 is a first of it's kind (CPU ever) regarding implanted solution for this. However thing that ARM didn't deliver is a better primary work horse which could make a difference in base user experience. A55 aren't exactly the power haus regarding performance & now their is more headroom regarding power when scaled down to the 7 nm, enough for let's say A73 on slightly lower clocks to replace the A55 (A73 is 1.6x integer performance of A55 MHz/MHz so A73 @ 1.7GHz = A55 @ 2.7 GHz while switching from 14 to 7nm would make DTP of A55 to A73 the same). But A73 doesn't work on DinamIQ cluster. So there is a need for the new two instructions wide OoO core with merged architectural advancements (front end, predictor, cache, ASIMD...) as in order ones did hit the brick wall long time ago.vladx - Friday, June 1, 2018 - link
> So switching from 14 nm to 7nm (60% reduction on power)That might've been true if both 14nm and 7nm fab processes were actually the real deal. But alas, they are not.
ZolaIII - Saturday, June 2, 2018 - link
Based on the TSMC projections 60% power reduction.beginner99 - Monday, June 4, 2018 - link
The things is that CPU power use might already be a small part of phone power use. The display usually being the main consumer and when the display isn't running, most likely the big core will also not be running. Saving 40% power sounds great on paper. But in real designs it will already be smaller and the total impact on phone battery life will be much, much smaller. Single-digit percentage probably depending on how much you use. The more it is idle, the less the big core efficiency matters.Dazedconfused - Thursday, May 31, 2018 - link
I get this, but when comparing an iPhone x and say an Android flagship next to each other in pretty much every day to day task, they appear evenly matched. There are some good comparisons on YouTube. There are definitely strengths to each platform, but it's not clear cut at all