Intel Introduces "Ruler" Server SSD Form-Factor: SFF-TA-1002 Connector, PCIe Gen 5 Ready
by Billy Tallis on August 9, 2017 3:00 PM EST
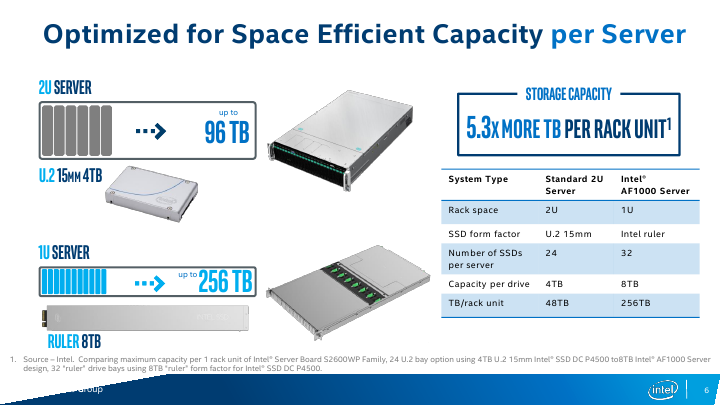
Intel on Tuesday introduced its new form-factor for server-class SSDs. The new "ruler" design is based on the in-development Enterprise & Datacenter Storage Form Factor (EDSFF), and is intended to enable server makers to install up to 1 PB of storage into 1U machines while supporting all enterprise-grade features. The first SSDs in the ruler form-factor will be available “in the near future” and the form-factor itself is here for a long run: it is expandable in terms of interface performance, power, density and even dimensions.

For many years SSDs relied on form-factors originally designed for HDDs to ensure compatibility between different types of storage devices in PCs and servers. Meanwhile, the 2.5” and the 3.5” form-factors are not always optimal for SSDs in terms of storage density, cooling, and other aspects. To better address client computers and some types of servers, Intel developed the M.2 form-factor for modular SSDs several years ago. While such drives have a lot of advantages when it comes to storage density, they were not designed to support such functionality as hot-plugging, whereas their cooling is a yet another concern. By contrast, the ruler form-factor was developed specifically for server drives and is tailored for requirements of datacenters. As Intel puts it, the ruler form-factor “delivers the most storage capacity for a server, with the lowest required cooling and power needs”.

From technical point of view, each ruler SSD is a long hot-swappable module that can accommodate tens of NAND flash or 3D XPoint chips, and thus offer capacities and performance levels that easily exceed those of M.2 modules.
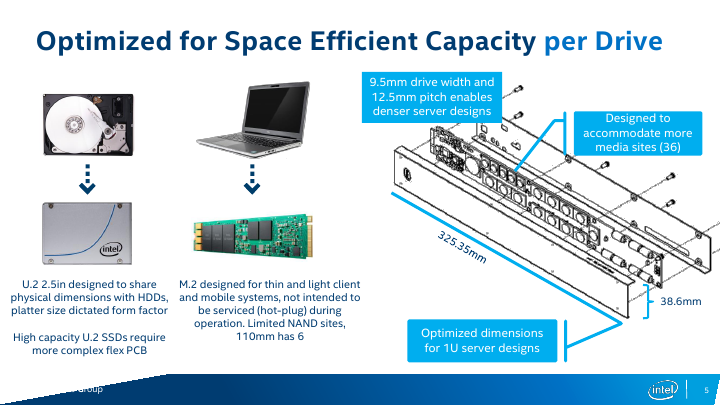
The initial ruler SSDs will use the SFF-TA-1002 "Gen-Z" connector, supporting PCIe 3.1 x4 and x8 interfaces with a maximum theoretical bandwidth of around 3.94 GB/s and 7.88 GB/s in both directions. Eventually, the modules could gain an x16 interface featuring 8 GT/s, 16 GT/s (PCIe Gen 4) or even 25 - 32 GT/s (PCIe Gen 5) data transfer rate (should the industry need SSDs with ~50 - 63 GB/s throughput). In fact, connectors are ready for PCIe Gen 5 speeds even now, but there are no hosts to support the interface.
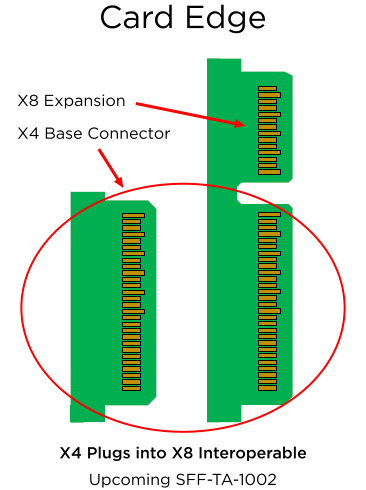
One of the key things about the ruler form-factor is that it was designed specifically for server-grade SSDs and therefore offers a lot more than standards for client systems. For example, when compared to the consumer-grade M.2, a PCIe 3.1 x4-based EDSFF ruler SSD has extra SMBus pins for NVMe management, additional pins to charge power loss protection capacitors separately from the drive itself (thus enabling passive backplanes and lowering their costs). The standard is set to use +12 V lane to power the ruler SSDs and Intel expects the most powerful drives to consume 50 W or more.

Servers and backplanes compatible with the rulers will be incompatible with DFF SSDs and HDDs, as well as with other proprietary form-factors (so, think of flash-only machines). EDSFF itself has yet to be formalized as a standard, however the working group for the standard already counts Dell, Lenovo, HPE, and Samsung as among its promotors, and Western Digital as one of several contributors.
It is also noteworthy that Intel has been shipping ruler SSDs based on planar MLC NAND to select partners (think of the usual suspects - large makers of servers as well as owners of huge datacenters) for about eight months now. While the drives did not really use all the advantages of the proposed standard – and I'd be surprised if they were even compliant with the final standard – they helped the EDSFF working group members prepare for the future. Moreover, some of Intel's partners have even added their features to the upcoming EDSFF standard, and still other partners are looking at using the form factor for GPU and FPGA accelerator devices. So it's clear that there's already a lot of industry interest and now growing support for the ruler/EDSFF concept.

Finally, one of the first drives to be offered in the ruler form-factor will be Intel’s DC P4500-series SSDs, which feature Intel’s enterprise-grade 3D NAND memory and a proprietary controller. Intel does not disclose maximum capacities offered by the DC P4500 rulers, but expect them to be significant. Over time Intel also plans to introduce 3D XPoint-based Optane SSDs in the ruler form-factor.






Related Reading:
Source: Intel








50 Comments
View All Comments
cdillon - Wednesday, August 9, 2017 - link
It is fair if you consider online serviceability and not just density. Stacking drives in the Z-dimension (depth-wise) in a high-density storage server leads to lower serviceability since you need to -- at the very least -- pull the entire server or a multi-drive sled forward out of the rack to access the drives that are sitting behind the front row.If you chose not to install rear cable management on the server that allows you to pull the server forward while it is live to perform this potentially delicate internal operation, you would need to shut the server down and disconnect it first before pulling it out to replace a drive.
This ruler format will make it easier to put all of these high-capacity drives at the front of the server where they can be easily accessed and hot-plugged.
ddriver - Wednesday, August 9, 2017 - link
Not necessarily an entire server, you can have multiple drawers per server. So you pull it out, remove the failed SSD, insert another, then put it back in. In and out in 30 seconds. Only 1/4 of the storage array is inaccessible for a very short duration. Depending on the config, it is actually possible to avoid any offline time altogether.Intel assumes that 1D stacking is the only possible solution, but you can easily do 2D stacking, and cram that chassis full of SSDs over its entire depth, easily beating the "ruler" capacity even via modest size 4 TB SSDs. That ruler is pretty big, and if capacity for that size is only 8TB then the actual storage density isn't all that great.
What cable management, SSDs have been plugin-slot compatible since day 1.
The ruler format makes it easier for intel to rake in more profits.
Adesu - Wednesday, August 9, 2017 - link
The article says the capacity will be up to 32TB "soon", 1PB (32TB x 32 Rulers) in a 1U server? That's pretty impressiveDeicidium369 - Tuesday, June 23, 2020 - link
32TB Rulers have been available for a while now - Intel has the DC series at 32TB. They are special order, but are available. The 16TB are more common...CheerfulMike - Wednesday, August 9, 2017 - link
He's talking about cable management in the back of a racked server on rails. One of my biggest pet peeves used to be when well-meaning datacenter guys rack a server and then Velcro the cables together all nice and neat but close to taut which makes it impossible to slide the server forward on its rails without disconnecting everything. This introduces the possibility of an error when reconnecting things and increases service time. Most servers have a kit available that encases the cables in a folding arm that guides them when the server is moved forward and back on rails. Unfortunately, they also can block airflow, so they're not terribly popular.Samus - Wednesday, August 9, 2017 - link
Totally, that's just a big no no. The ideal situation is to have a rack serviceable without removal. Other than motherboards, most are. Back-plane failures are incredibly rare. But motherboards do fail, often a network controller. Proliants not have a door on the center of the chassis to allow only partially removing the rack to upgrade the memory. PSU's and drives are all serviced from the rear and front. High end units have hot swapable memory as well.I think the immediate takeaway here is finally official hot swap support for SSD's without needing SAS. The density and performance benefits will be more important in the future.
petteyg359 - Wednesday, August 16, 2017 - link
2.5" SSDs have "official hot swap support" already. I do it all the time in my Corsair 900D with an ASRock "gaming" motherboard. If you think servers can't do it better, you've been sleeping under a rock for a few decades.petteyg359 - Wednesday, August 16, 2017 - link
2.5" plain-old SATA*Deicidium369 - Tuesday, June 23, 2020 - link
Watched a couple cabling vids - and they did that - apparently the cable god didn't know about servicingSamus - Wednesday, August 9, 2017 - link
Have you ever been in a data center? If they had to pull a rack out, or outfit them with a drawer, every time they had to service a failed drive, maintenance costs would go through the roof. I toured an AWS facility in Chicago and they mentioned they replace around 90 drives A DAY while performing non-stop ongoing expansion. Basically people are always walking the isles, which are narrow, and if you had to remove a rack onto a cart or drawer to perform this operation it would turn a 30 second procedure into a 30 minute procedure.This is a desperately needed form factor, especially with the utter lack of SAS SSD's as virtually no SATA drives officially support hot swapping.