The Intel Kaby Lake-X i7 7740X and i5 7640X Review: The New Single-Threaded Champion, OC to 5GHz
by Ian Cutress on July 24, 2017 8:30 AM EST- Posted in
- CPUs
- Intel
- Kaby Lake
- X299
- Basin Falls
- Kaby Lake-X
- i7-7740X
- i5-7640X
Civilization 6
First up in our CPU gaming tests is Civilization 6. Originally penned by Sid Meier and his team, the Civ series of turn-based strategy games are a cult classic, and many an excuse for an all-nighter trying to get Gandhi to declare war on you due to an integer overflow. Truth be told I never actually played the first version, but every edition from the second to the sixth, including the fourth as voiced by the late Leonard Nimoy, it a game that is easy to pick up, but hard to master.

Benchmarking Civilization has always been somewhat of an oxymoron – for a turn based strategy game, the frame rate is not necessarily the important thing here and even in the right mood, something as low as 5 frames per second can be enough. With Civilization 6 however, Firaxis went hardcore on visual fidelity, trying to pull you into the game. As a result, Civilization can taxing on graphics and CPUs as we crank up the details, especially in DirectX 12.
Perhaps a more poignant benchmark would be during the late game, when in the older versions of Civilization it could take 20 minutes to cycle around the AI players before the human regained control. The new version of Civilization has an integrated ‘AI Benchmark’, although it is not currently part of our benchmark portfolio yet, due to technical reasons which we are trying to solve. Instead, we run the graphics test, which provides an example of a mid-game setup at our settings.

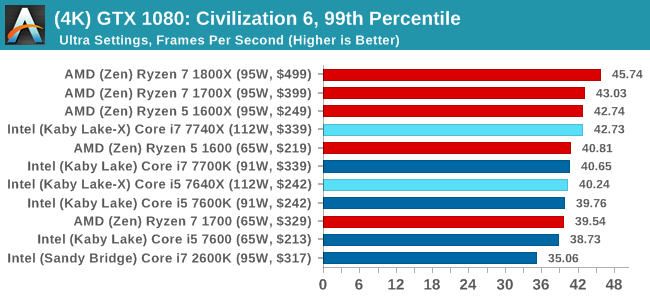
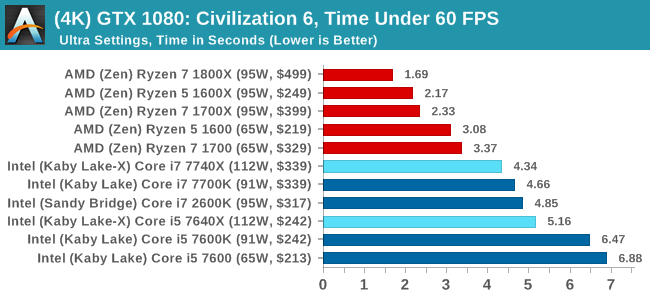
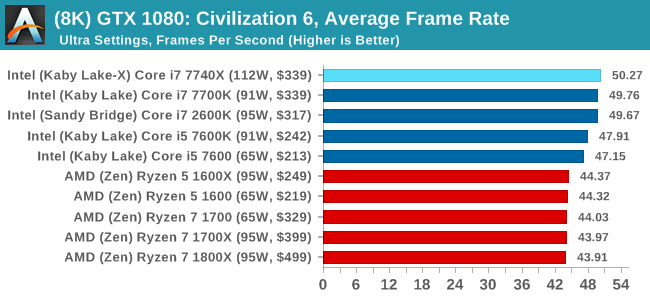
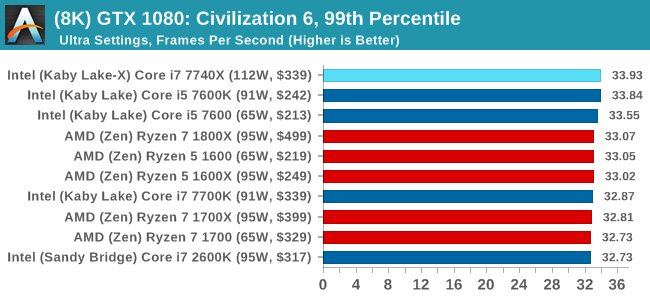
At both 1920x1080 and 4K resolutions, we run the same settings. Civilization 6 has sliders for MSAA, Performance Impact and Memory Impact. The latter two refer to detail and texture size respectively, and are rated between 0 (lowest) to 5 (extreme). We run our Civ6 benchmark in position four for performance (ultra) and 0 on memory, with MSAA set to 2x.
For reviews where we include 8K and 16K benchmarks (Civ6 allows us to benchmark extreme resolutions on any monitor) on our GTX 1080, we run the 8K tests similar to the 4K tests, but the 16K tests are set to the lowest option for Performance.
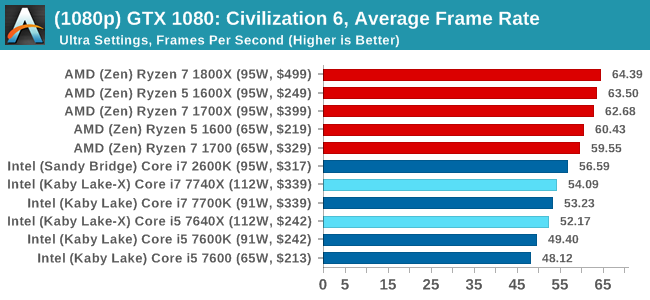
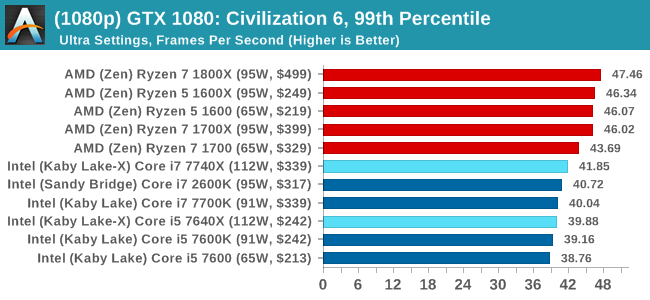
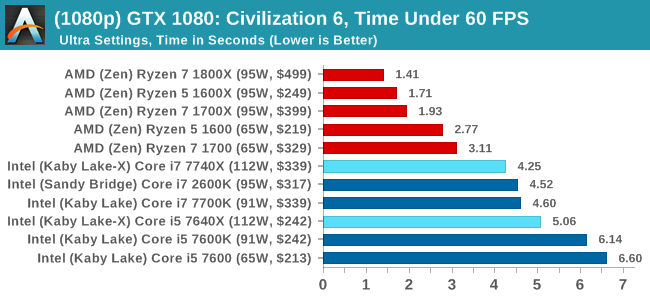
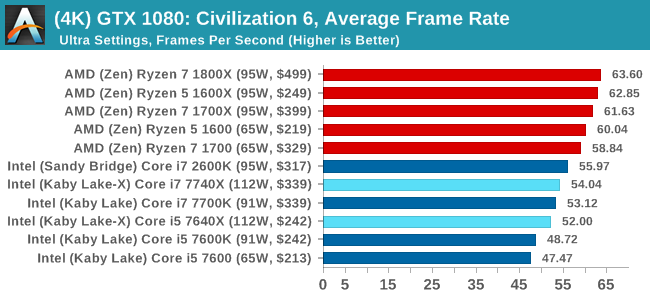
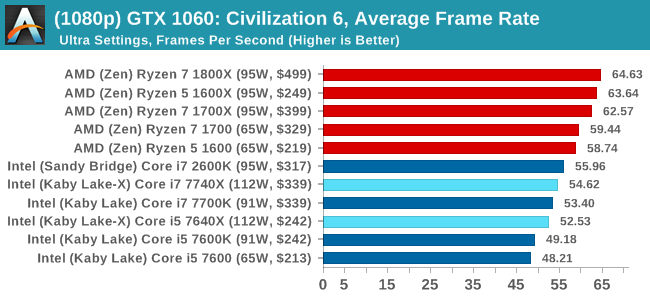
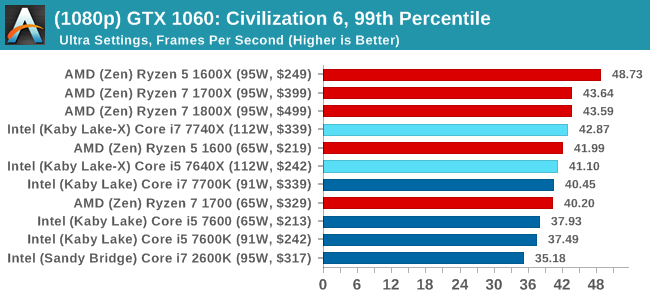
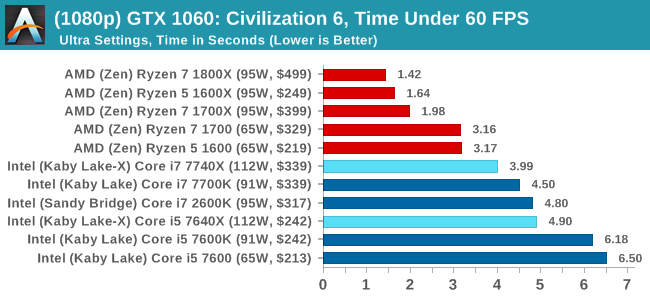
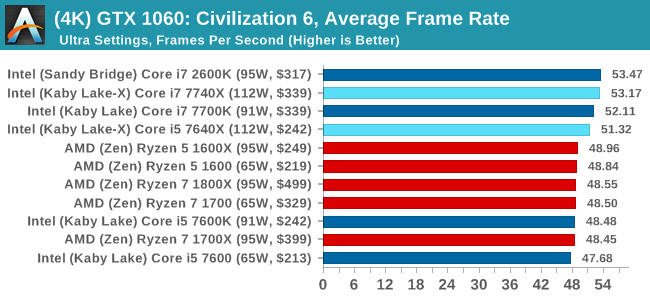
For all our results, we show the average frame rate at 1080p first. Mouse over the other graphs underneath to see 99th percentile frame rates and 'Time Under' graphs, as well as results for other resolutions. All of our benchmark results can also be found in our benchmark engine, Bench.
MSI GTX 1080 Gaming 8G Performance
1080p
4K
8K
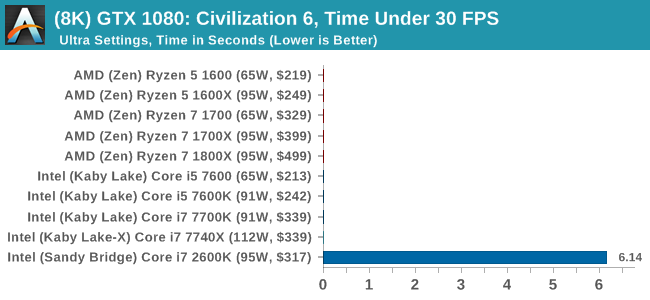
16K
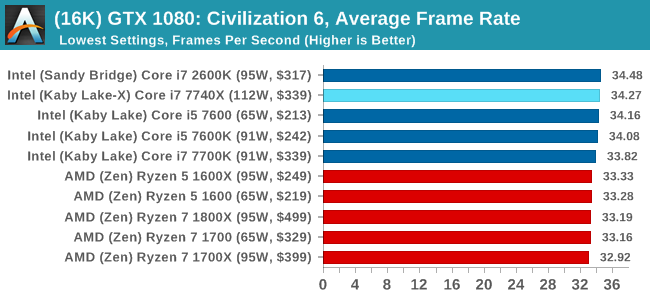
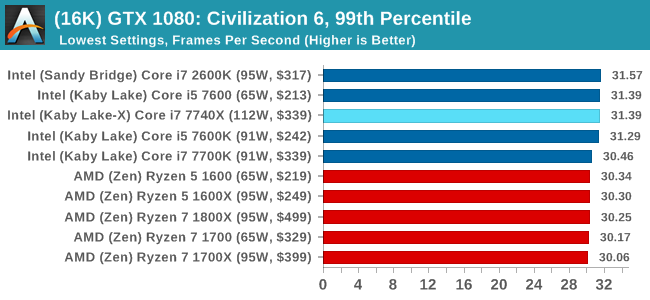
ASUS GTX 1060 Strix 6GB Performance
1080p
4K
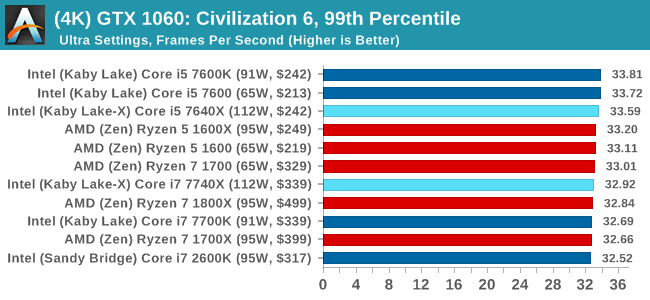
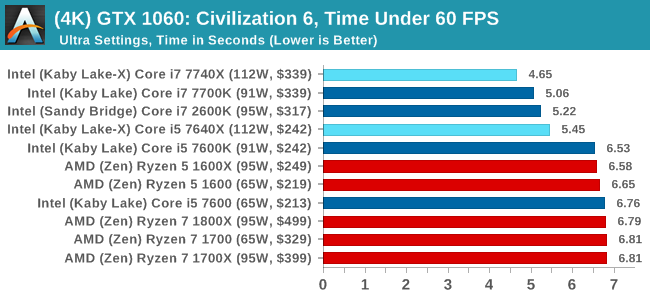
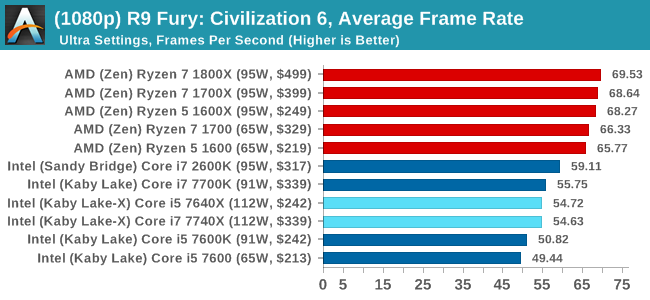
Sapphire R9 Fury 4GB Performance
1080p
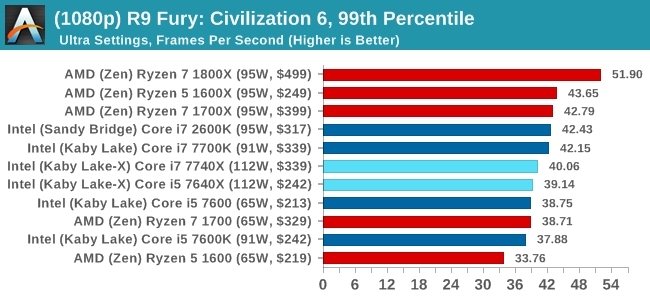
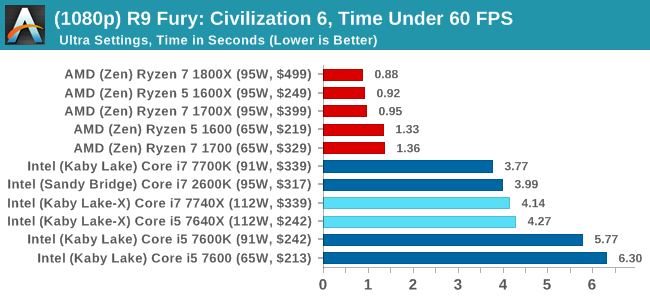
4K
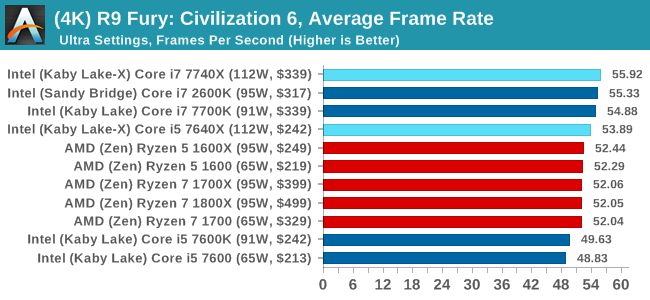
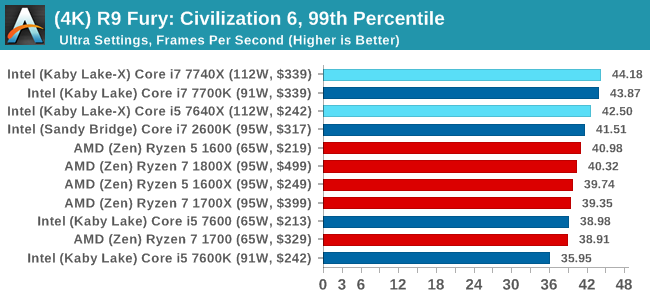
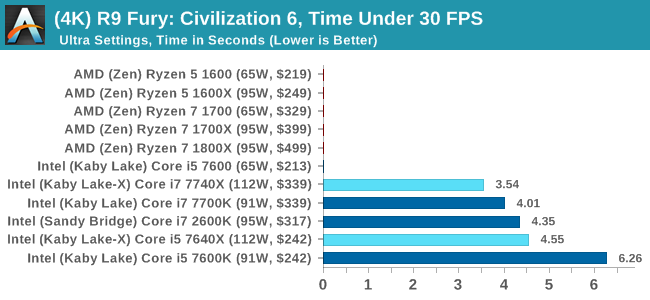
Sapphire RX 480 8GB Performance
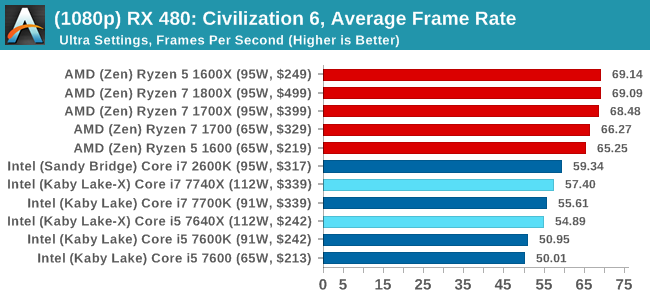
1080p
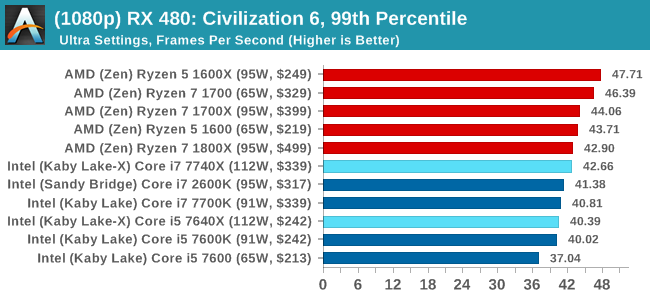
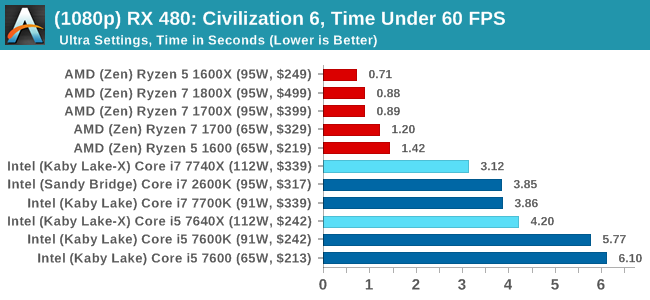
4K
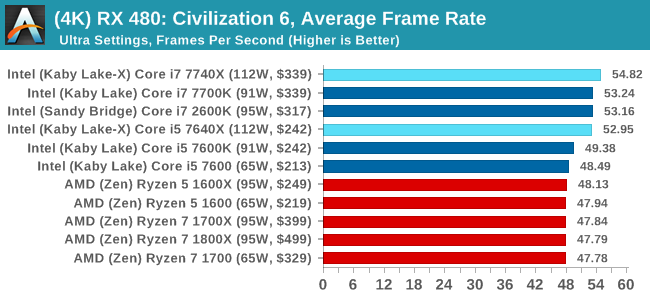
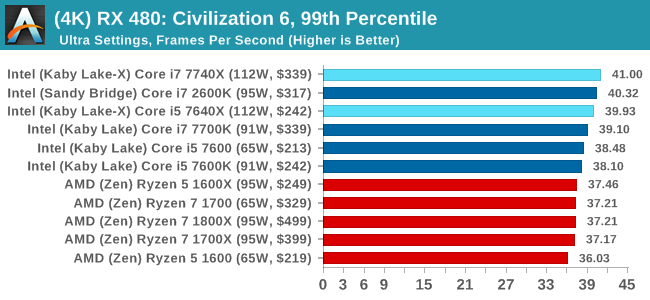

Civilization 6 Conclusion
In all our testing scenarios, AMD wins at 1080p with minor margins on the frame rates but considerable gains in the time under analysis. Intel pushes ahead in almost all of the 4K results, except with the time under analysis at 4K using an R9 Fury, perhaps indicating that AMD is offering a steadier range in its frame rate, despite the average being lower.








176 Comments
View All Comments
mapesdhs - Monday, July 24, 2017 - link
Ok, you get a billion points for knowing Commodore BASIC. 8)IanHagen - Monday, July 24, 2017 - link
Dr. Ian, I would like to apologize for my poor choice of words. Reading it again, it sounds like I accused you of something which is not the case.I'm merely puzzled by how Ryzen performs poorly using msvc compared to other compilers. To be honest, your finds are very relevant to anyone using Visual Studio. But again, I find Microsoft's VS compilar to be a bit of an oddball.
A few weeks ago I was running my own tests to determine wether my Core i5 4690K was up to my compiling tasks. Since most of my professional job sits on top of programming languages with either short compile times or no compilation needed at all, I never bothered much about it. But recently I've been using C++ more and more during my game development hobby and compile times started to bother me. What I found puzzling is that after running a few test I couldn't manage to get any gains through parallelism, even after verifying that msvc was indeed spanning all 4 threads to compile files. Than I tried disabling two cores and clocking the thing higher and... it was faster! Not by a lot, but faster still. How could it be faster with a 50% decrease in the number of active cores and consequently threads doing compile jobs? I'm fully aware that linking is single threaded, but at least a few seconds should be gained with two extra cores, at least in theory. Today I had the chance to compile the same project on a Core i7 7700HQ and it was substantially slower than my Core i5 4690K even with clocks capped to 3.2 GHz. In fact, it was 33% slower than my Core i5 at stock speeds.
Anyhow… Dr. Ian’s findings are a very good to point out to those compiling C++ using msvc that Skylake-X is probably worth it over Ryzen. For my particular case, it would appear that Kaby Lake-X with the Core i7 7740X could even be the best choice, since my project somehow only scales nicely with clocks.
I just would like to see the wording pointing out that Skylake-X isn’t a better compiling core. It’s a better compiling core using msvc at this particular workload. On the GCC side of things, Ryzen is very competitive to it and a much better value in my humble opinion.
As for the suggestion, I’d say that since Windows is a requirement trying to script something to benchmark compile times using GCC would be daunting and unrealistic. Not a lot of people are using GCC to work on the Windows side of things. If Linux could be thrown into the equation, I’d suggest a project based on CMake. That would make it somewhat easy to write a simple script to setup, create a makefile and compile the project. Unfortunately, I can not readily think of any big name projects such as Chromium that fulfill that requirement without having to meddle with eventual dependency problems as the time goes by.
Kevin G - Monday, July 24, 2017 - link
These chips edge out their LGA 1151 counter parts at stock with overclocking also carrying a slight razor edge over LGA 1151 overclocks. There are gains but ultimately these really don't seem worth it, especially in light of the fragmentation that this causes the X299 platform. Hard to place real figures on this but I'd wager that the platform confusion is going to cost Intel more than what they will gain with these chips. Intel should have kept these in the lab until they could offer something a bit more substantial.mapesdhs - Monday, July 24, 2017 - link
I wonder if it would have been at least a tad better received if they hadn't cripplied the on-die gfx, etc.DanNeely - Tuesday, July 25, 2017 - link
LGA2066 doesn't have video out pins because it was originally designed only for the bigger dies that don't include them; and even if Intel had some 'spare' pins it could use adding video out would only make already expensive mobos with a wide set of features that vary based on the CPU model even more expensive and more confusing. Unless they add a GPU to either future CPUs in the family (or IMO a bit more likely) a very basic one to a chipset variant (to remove the crappy one some server boards add for KVM support) keeping the IGP fully off in mainstream dies on the platform is the right call IMO.DrKlahn - Monday, July 24, 2017 - link
Great article, but the conclusion feels off:"The benefits in the benchmarks are clear against the nearest competition: these are the fastest CPUs to open a complex PDF, at the top for office work, and at the top for most web interactions by a noticeable amount."
In most cases you're talking about a second or less between the Intel and AMD systems. That will not be noticeable to the average office worker. You're much more likely to run into scenarios where the extra cores or threads will make an impact. I know in my own user base shaving a couple of seconds off opening a large PDF will pale in comparison to running complex reports with 2 (4 threads) extra cores for less money. I have nothing against Intel, but I struggle to see anything in here that makes their product worth the premium for an Office environment. The conclusion seems a stretch to me.
mapesdhs - Monday, July 24, 2017 - link
Indeed, and for those dealing with office work it makes more sense to emphasise investment where it makes the biggest difference to productivity, which for PCs is having an SSD (ie. don't buy a cheap grunge box for office work), but more generally dear god just make sure employees have a damn good chair to sit on and a decent IPS display that'll be kind to their eyes. Plus/minus 1s opening a PDF is a nothingburger compared to good ergonomics for office productivity.DrKlahn - Tuesday, July 25, 2017 - link
Yeah an SSD is by far the best bang for the buck. From a CPU standpoint there are more use cases for Ryzen 1600 than there is the i5/i7 options we have from HP/Dell. Even the Ryzen 1500 series would probably be sufficient and allow even more per unit savings to put into other areas that would benefit folks more.JimmiG - Monday, July 24, 2017 - link
The 7740X runs at a just over 2% higher clock speed than the 7700X. It can overclock maybe 4% higher than the 7700X. You'd really have to be a special kind of stupid to pay hundreds more for an X299 mobo just for those gains that are nearly within the margin of error.It doesn't make sense as a "stepping stone" onto HEDT either, because you're much better off simply buying a real HEDT right away. You'll pay a lot more in total if you first get the 7740X and then the 7820X for example.
mapesdhs - Monday, July 24, 2017 - link
Intel seems to think there's a market for people who buy a HEDT platform but can't afford a relevant CPU, but would upgrade later. Highly unlikely such a market exists. By the time such a theoretical user would be in a position to upgrade, more than likely they'd want a better platform anyway, given how fast the tech is changing.