The Intel Kaby Lake-X i7 7740X and i5 7640X Review: The New Single-Threaded Champion, OC to 5GHz
by Ian Cutress on July 24, 2017 8:30 AM EST- Posted in
- CPUs
- Intel
- Kaby Lake
- X299
- Basin Falls
- Kaby Lake-X
- i7-7740X
- i5-7640X
Benchmarking Performance: CPU Rendering Tests
Rendering tests are a long-time favorite of reviewers and benchmarkers, as the code used by rendering packages is usually highly optimized to squeeze every little bit of performance out. Sometimes rendering programs end up being heavily memory dependent as well - when you have that many threads flying about with a ton of data, having low latency memory can be key to everything. Here we take a few of the usual rendering packages under Windows 10, as well as a few new interesting benchmarks.
All of our benchmark results can also be found in our benchmark engine, Bench.
Corona 1.3: link
Corona is a standalone package designed to assist software like 3ds Max and Maya with photorealism via ray tracing. It's simple - shoot rays, get pixels. OK, it's more complicated than that, but the benchmark renders a fixed scene six times and offers results in terms of time and rays per second. The official benchmark tables list user submitted results in terms of time, however I feel rays per second is a better metric (in general, scores where higher is better seem to be easier to explain anyway). Corona likes to pile on the threads, so the results end up being very staggered based on thread count.
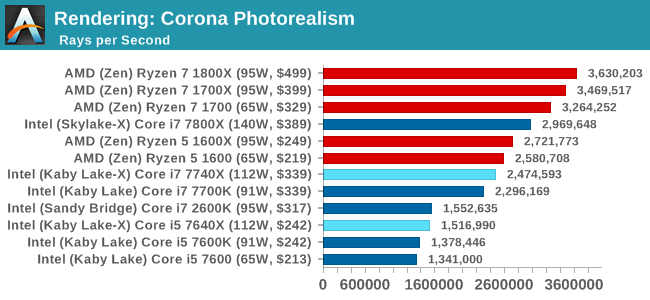
More threads win the day, although the Core i7 does knock at the door of the Ryzen 5 (presumably with $110 in hand as well). It is worth noting that the Core i5-7640X and the older Core i7-2600K are on equal terms.
Blender 2.78: link
For a render that has been around for what seems like ages, Blender is still a highly popular tool. We managed to wrap up a standard workload into the February 5 nightly build of Blender and measure the time it takes to render the first frame of the scene. Being one of the bigger open source tools out there, it means both AMD and Intel work actively to help improve the codebase, for better or for worse on their own/each other's microarchitecture.
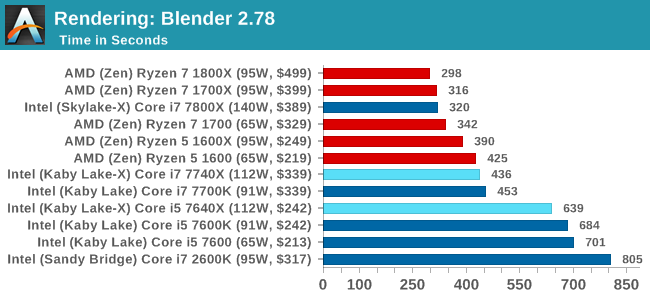
Similar to Corona, more threads means a faster time.
LuxMark v3.1: Link
As a synthetic, LuxMark might come across as somewhat arbitrary as a renderer, given that it's mainly used to test GPUs, but it does offer both an OpenCL and a standard C++ mode. In this instance, aside from seeing the comparison in each coding mode for cores and IPC, we also get to see the difference in performance moving from a C++ based code-stack to an OpenCL one with a CPU as the main host.
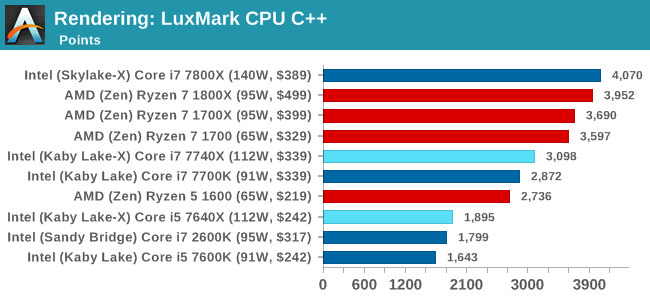
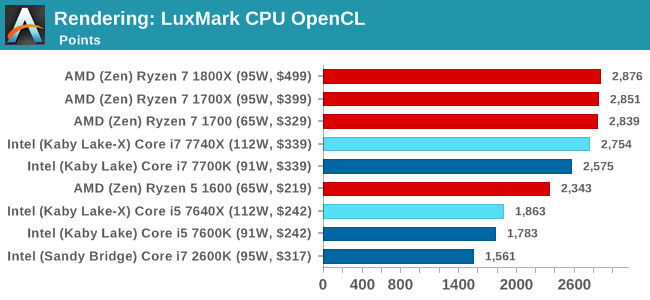
Luxmark is more thread and cache dependent, and so the Core i7 nips at the heels of the AMD parts with double the threads. The Core i5 sits behind the the Ryzen 5 parts though, due to the 1:3 thread difference.
POV-Ray 3.7.1b4: link
Another regular benchmark in most suites, POV-Ray is another ray-tracer but has been around for many years. It just so happens that during the run up to AMD's Ryzen launch, the code base started to get active again with developers making changes to the code and pushing out updates. Our version and benchmarking started just before that was happening, but given time we will see where the POV-Ray code ends up and adjust in due course.
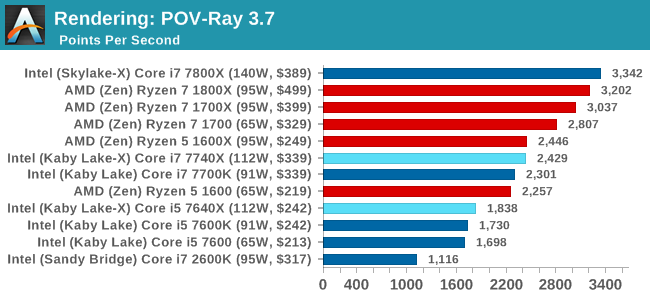
Mirror Mirror on the wall...
Cinebench R15: link
The latest version of CineBench has also become one of those 'used everywhere' benchmarks, particularly as an indicator of single thread performance. High IPC and high frequency gives performance in ST, whereas having good scaling and many cores is where the MT test wins out.
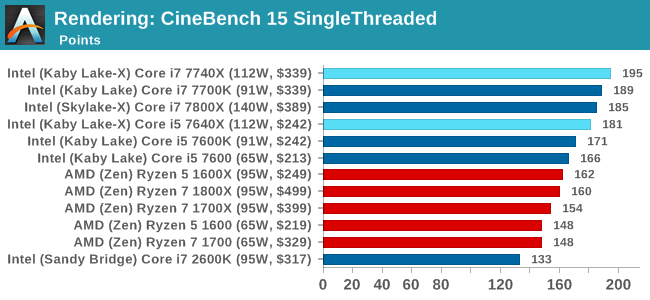
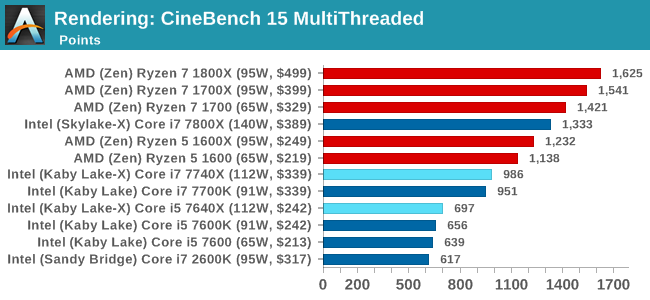
CineBench gives us singlethreaded numbers, and it is clear who rules the roost, almost scoring 200. The Core i7-2600K, due to its lack of instruction support, sits in the corner.








176 Comments
View All Comments
iwod - Monday, July 24, 2017 - link
Intel has 10nm and 7nm by 2020 / 2021. Core Count is basically a solved problem, limited only by price.What we need is a substantial breakthrough in single thread performance. May be there are new material that could bring us 10+Ghz. But those aren't even on the 5 years roadmap.
mapesdhs - Monday, July 24, 2017 - link
That's more down to better sw tech, which alas lags way behind. It needs skills that are largely not taught in current educational establishments.wolfemane - Monday, July 24, 2017 - link
Under Handbrake testing, just above the first graph you state:"Low Quality/Resolution H264: He we transcode a 640x266 H264 rip of a 2 hour film, and change the encoding from Main profile to High profile, using the very-fast preset."
I think you mean to say "HERE we transcode..."
Great article overall. Thank you!
Ian Cutress - Monday, July 24, 2017 - link
Thanks, corrected :)wolfemane - Monday, July 24, 2017 - link
I wish your team would finally add in an edit button to comments! :)On the last graph ENCODING: Handbrake HEVC (4k) you don't list the 1800x, but it is present in the previous two graphs @ LQ and HQ. Was there an issue with the 1800x preventing 4k testing? Quite interested in it's results if you have them.
Ian Cutress - Monday, July 24, 2017 - link
When I first did the HEVC testing for the Ryzen 7 review, there was a slight issue in it running and halfway through I had to change the script because the automation sometimes dropped a result (like the 1800X which I didn't notice until I was 2-3 CPUs down the line). I need to put the 1800X back on anyway for AGESA 1006, which will be in an upcoming article.IanHagen - Monday, July 24, 2017 - link
One thing that caught my eye for a while is how compile tests using GCC or clang show much better results on Ryzen compared to using Microsoft's VS compiler. Phoronix tests clearly shows that. Thus, I cannot really believe yet on Ian's recurring explanation of Ryzen suffering from its victim L3 cache. After all, the 1800X beats the 7700K by a sizable margin when compiling the Linux kernel.Isn't Ryzen relatively poor performance compiling Chromium due to idiosyncrasies of the VS compiler?
Ian Cutress - Monday, July 24, 2017 - link
The VS compiler seems to love L3 cache, then. The 1800X does have 2x threads and 2x cores over the 7700K, accounting for the difference. We saw a -17% drop going from SKL-S with its fully inclusive L3 to SKL-SP with a victim L3, clock for clock.Chromium was the best candidate for a scripted, consistent compile workflow I could roll into our new suite (and runs on Windows). Always open for suggestions that come with an ELI5.
ddriver - Monday, July 24, 2017 - link
So we are married to chromium, because it only compiles with msvc on windows?Or maybe because it is a shitty implementation that for some reason stacks well with intel's offerings?
Pardon my ignorance, I've only been a multi-platform software developer for 8 years, but people who compile stuff a lot usually don't compile chromium all day.
I'd say go GCC or Clang, because those are quality community drive open source compilers that target a variety of platforms, unlike msvc. I mean if you really want to illustrate the usefulness of CPUs for software developers, which at this point is rather doubtful...
Ian Cutress - Monday, July 24, 2017 - link
Again, find me something I can rope into my benchmark suite with an ELI5 guide and I try and find time to look into it. The Chromium test took the best part of 2-3 days to get in a position where it was scripted and repeatable and fit with our workflow - any other options I examined weren't even close. I'm not a computer programmer by day either, hence the ELI5 - just years old knowledge of using Commodore BASIC, batch files, and some C/C++/CUDA in VS.