The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTFetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
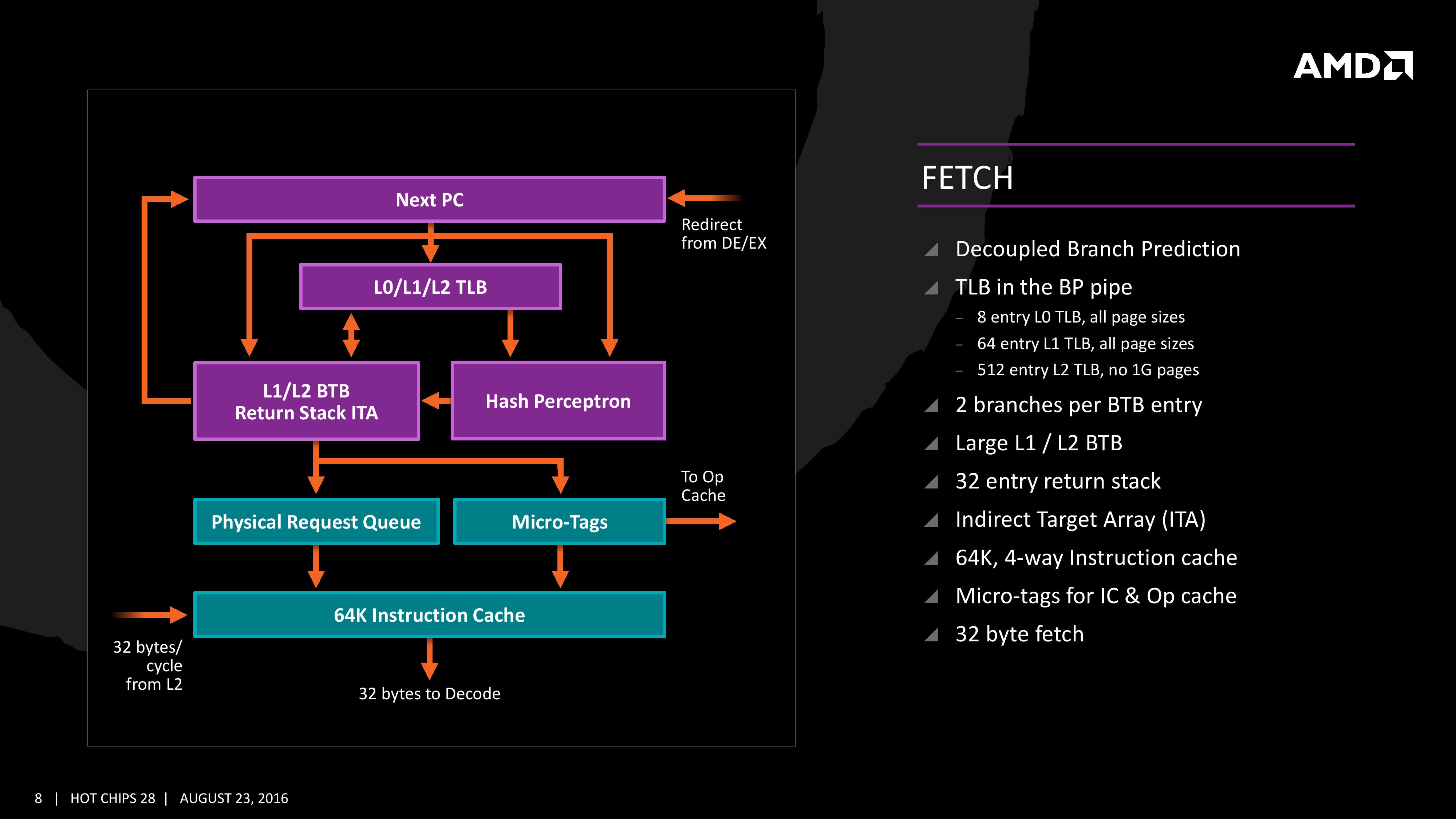
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
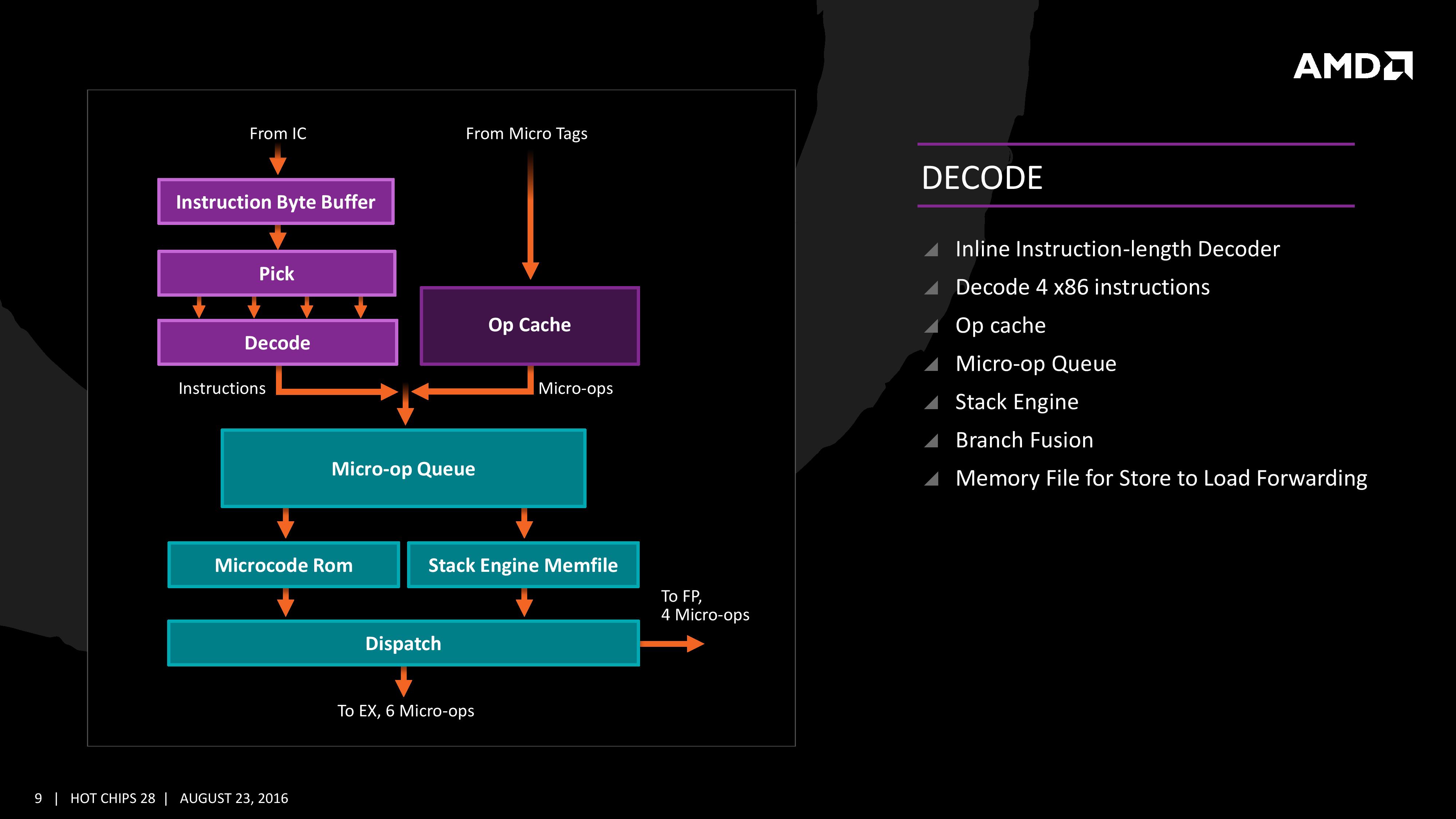
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








574 Comments
View All Comments
FriendlyUser - Thursday, March 2, 2017 - link
True. The 1600X will be competitive with the i5 at gaming and probably much faster in anything multithreaded. The crucial point is the price... $200 would be great.MrSpadge - Thursday, March 2, 2017 - link
"Ryzen will need to drop in price. $500 1800x is still too expensive. According to this even a 7700k @ $300 -$350 is still a good choice for gamers."That's what the 1700X is for.
lilmoe - Thursday, March 2, 2017 - link
+1And for that, I'd say the 1700 (non-x) is the best consumer CPU available ATM. BUT, if someone just wants to game, I'd say get the Core i5... For me though, screw Intel. Never going them again.
fanofanand - Thursday, March 2, 2017 - link
The 1700 is the sweet spot for anyone not trying to eek out a few more fps or drop their encode/decode times by a couple of seconds. To save $170 and lose a couple hundred mhz, I know which chip seems like the best all-around for price/performance and that's the 1700.lilmoe - Thursday, March 2, 2017 - link
Yep. You get both efficiency and performance when needed. This should allow for super quiet and very performant builds. Just take a look at the idle system power draw of these chips. Super nice.Everything is going either multi-threaded or GPU accelerated, even compiling code. What I'm really waiting for is Raven Ridge. I've got lots of stock $$ and high hopes for a low power 4-6 core Zen APU, with HBM and some bonus blocks for video encode (akin to Quicksync). I have a feeling they'll be much better for idling power and have better support for Microsoft's connected standby.
khanikun - Friday, March 3, 2017 - link
i5 is a good gamer and all around cpu for majority of users. If all you plan to do is game and a tight budget, the i3 7350k is a great cpu for just that. Once the workload goes a bit more multithreaded, that's where you'll want to move to an i5.Valis - Friday, March 3, 2017 - link
I game now and then, but I do a lot of other things too. Video rendering, Crypto coins, Folding @ home, VM, etc. So any Zen, perhaps even 4 Core later thins year with a good GPU will suit me fine. :)nos024 - Thursday, March 2, 2017 - link
So the 1800x is pointless?lilmoe - Thursday, March 2, 2017 - link
I don't think pointless is the right word. I'd say it's the worse value for dollar of the three.tacitust - Thursday, March 2, 2017 - link
Not at all pointless if you do a lot of video transcoding or other CPU intensive tasks well suited to multiple cores. The price premium is still for the 1800x is way lower than the price premium for the Intel processors.