The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTFetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
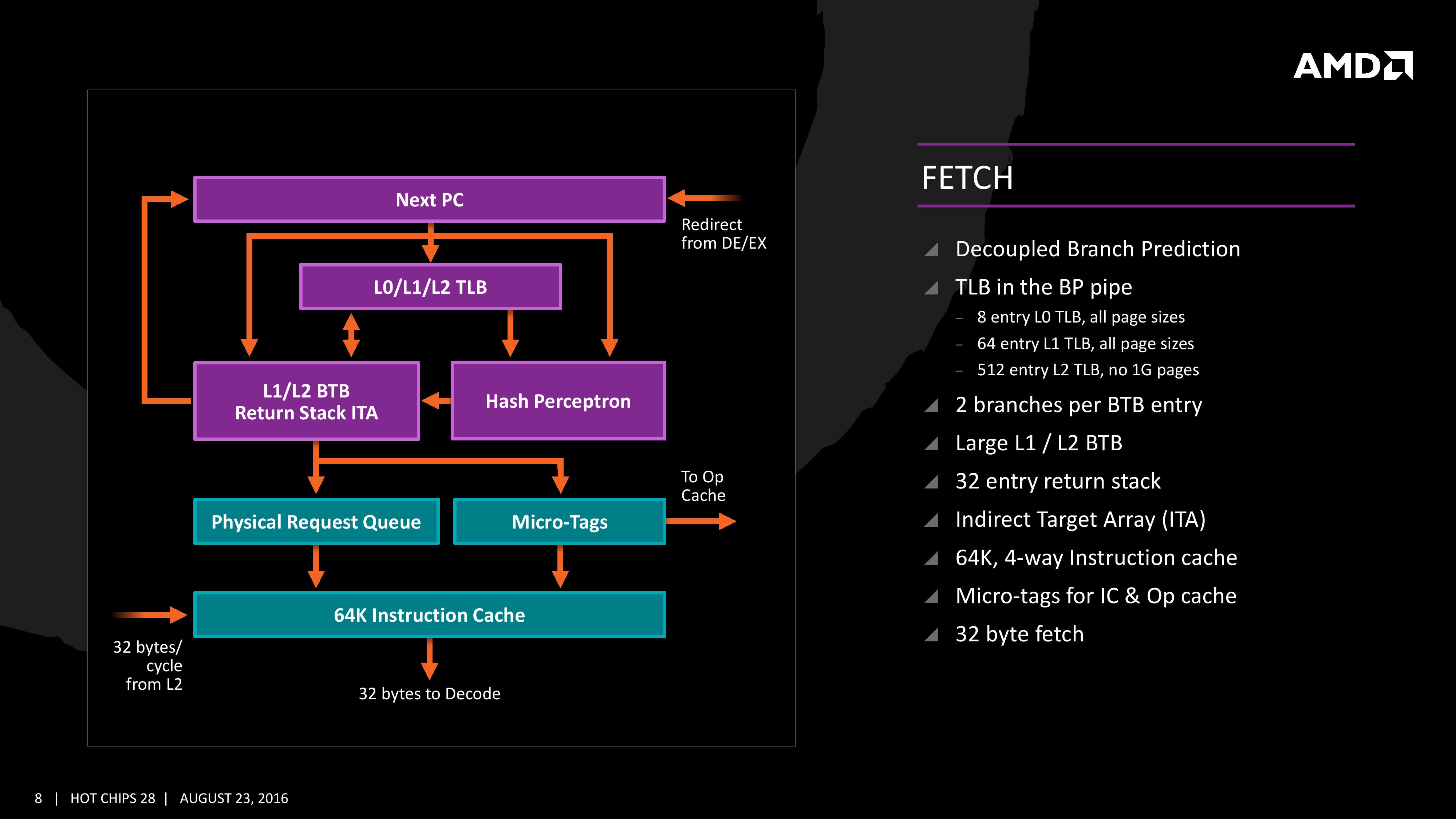
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
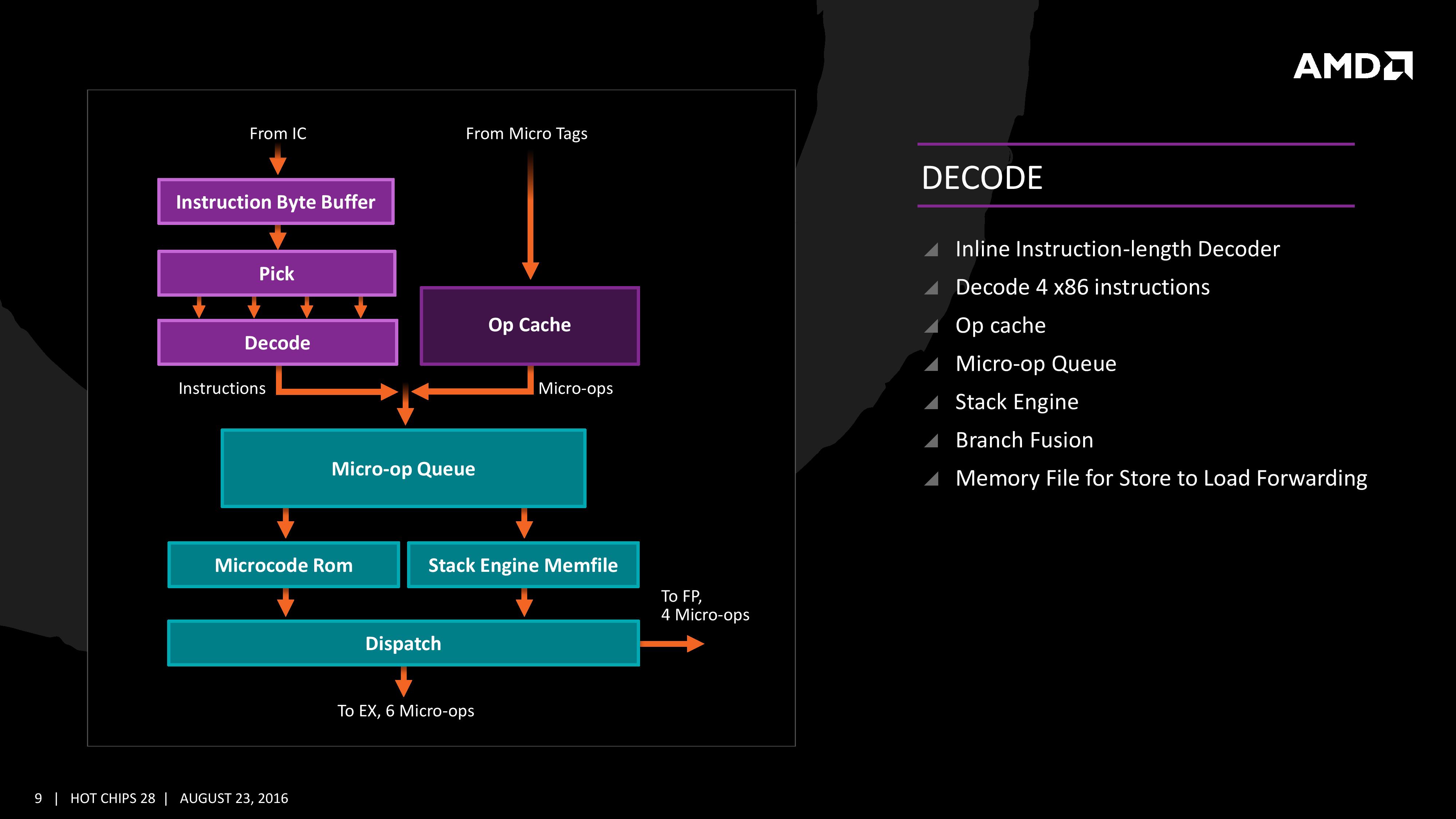
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








574 Comments
View All Comments
EchoWars - Thursday, March 2, 2017 - link
No, apparently the failure was in your education, since it's obvious you did not read the article.Notmyusualid - Friday, March 3, 2017 - link
Ha...sharath.naik - Thursday, March 2, 2017 - link
I think you missed the biggest news in this information dump. The TDP is the biggest advantage amd has. Which means that for 150watt server cpu. they should be able to cram a lot more cores than intel will be able to.Meteor2 - Friday, March 3, 2017 - link
^^^This. I think AMD's strength with Zen is going to be in servers.Sttm - Friday, March 3, 2017 - link
Yeah I can see that.UpSpin - Thursday, March 2, 2017 - link
According to a german site, in games, Ryzen is equal (sometimes higher, sometimes lower) to the Intel i7-6900K in high resolution games (WQHD). Once the resolution is set very low (720p) the Ryzen gets beaten by the Intel processor, but honestly, who cares about low resolution? For games, the probably best bet would be the i7-7700K, mainly because of the higher clock rate, for now. Once the games get better optimized for 8 cores, the 4-core i7-7700K will be beaten for sure, because in multi-threaded applications Ryzen is on par with the twice expensive Intel processor.I doubt it makes sense to buy the Core i7-6850K, it has the same low turbo boost frequency the 6900K has, thus low single threaded performance, but at only 6 cores. So I expect that it's the worst from both worlds. Poor multi-threaded performance compared to Ryzen, poor single threaded performance compared to i7-7700K.
We also have to see how well Ryzen can get overclocked, thus improving single core performance.
fanofanand - Thursday, March 2, 2017 - link
That is a well reasoned comment. Kudos!ShieTar - Thursday, March 2, 2017 - link
Well, the point of low-resolution testing is, that at normal resolutions you will always be GPU-restricted. So not only Ryzen and the i7-6900K are equal in this test, but so are all other modern and half-modern CPUs including any old FX-8...The most interesting question will be how Ryzen performs on those few modern games which manage to be CPU-restricted even in relevant resolutions, e.g. Battlefield 1 Multiplayer. But I think it will be a few more days, if not weeks, until we get that kind of in-depth review.
FriendlyUser - Thursday, March 2, 2017 - link
This is true, but at the same time this artificially magnifies the differences one is going to notice in a real-world scenario. I saw reviews with a Titan X at 1080p, while many will be playing 1440p with a 1060 or RX480.The test case must also approximate real life.
khanikun - Friday, March 3, 2017 - link
They aren't testing to show what it's like in real life though. The point of testing is to show the difference between the CPUs. Hence why they are gearing their benchmarking to stress the CPU, not other portions of the system.