The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTFetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
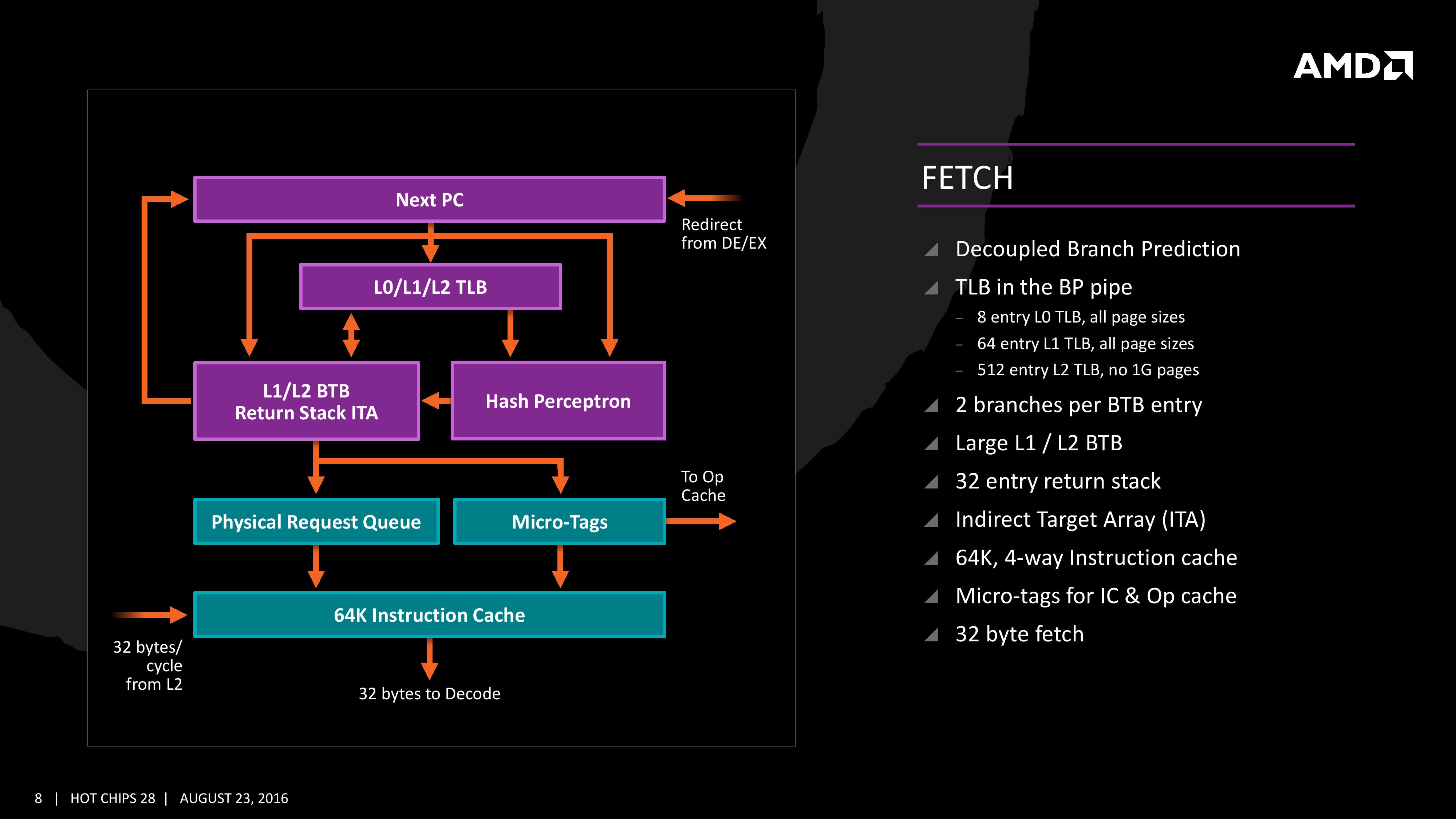
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
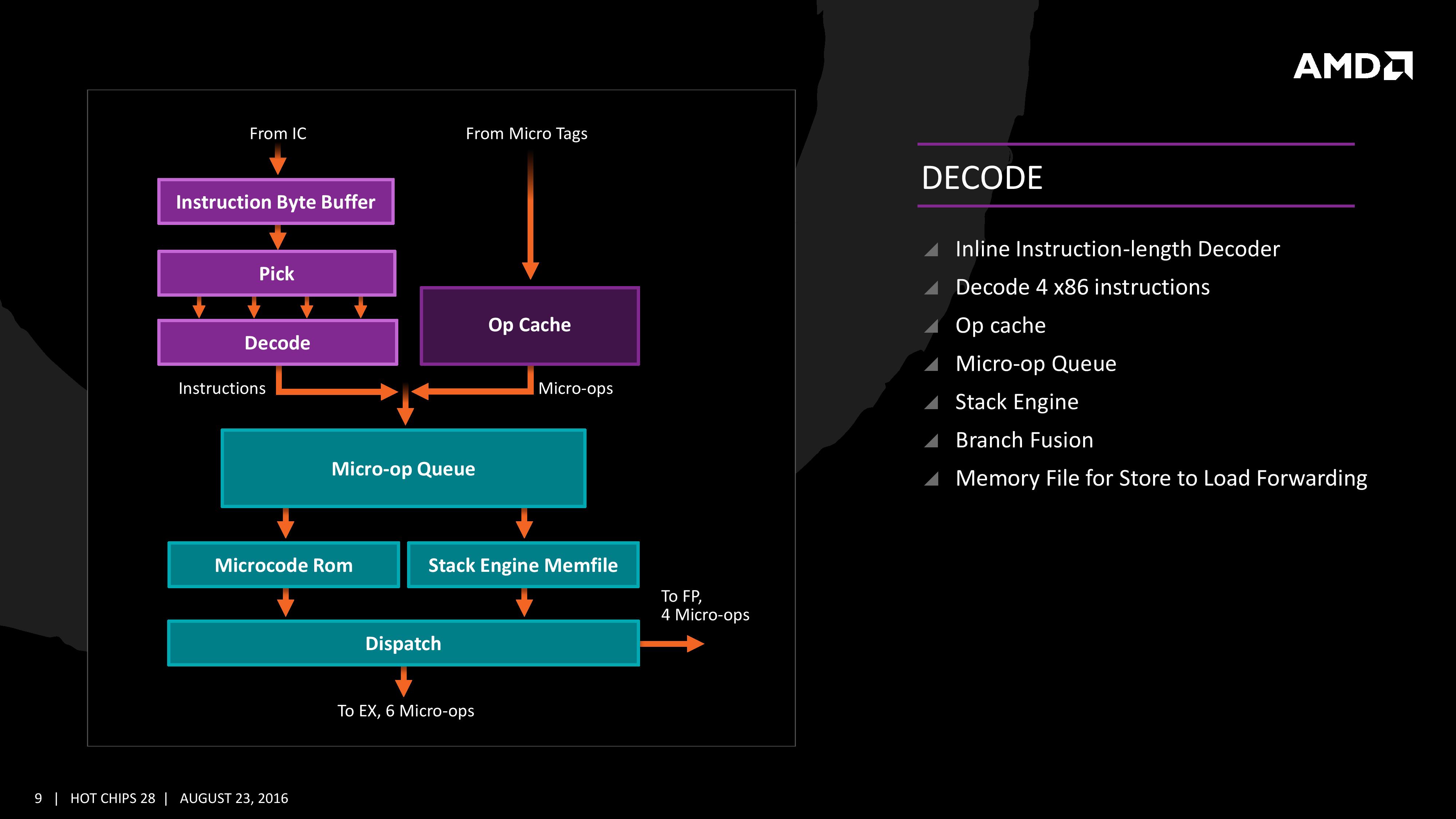
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








574 Comments
View All Comments
theuglyman0war - Saturday, March 4, 2017 - link
I'd like to see a lot more older i7 extreme editions covered all the way to westmere so I can sell clients on new builds with such a comparison.mapesdhs - Sunday, March 5, 2017 - link
Which older i7s interest you specifically?theuglyman0war - Saturday, March 4, 2017 - link
Checking what I paid last month for i7-7700k at Microcenter...Although I did get the motherboard combo price sale they "usually" offer...
The supposed $60 off for $319 is the cheapest price I found with a quick survey of new egg, amazon etc... And only $20 less then what I paid! Hardly A slashed priced answer shot across the bow by Intel! Not by a long shot!
I thought I was going to recommend the new cheap price to all my customer's new builds but I am pushing RYZEN and AM4 for a real combined price that makes a difference. ( the cheap price for enthusiast Am4 is enticing but the loss of PCI lanes is of concern for extreme cpu comparison anyway. Not so much compared to i7-7700k though which brings the comparison back to 16 lane parity! )
theuglyman0war - Saturday, March 4, 2017 - link
Could anyone actually point me to the amazing slashed deals that "BEAT" what I couldn't get last month by a long shot?( which was $349 BEFORE rebate. In other words it's not like there were not sales last month as well. And I see nothing now that really amounts to AMAZING compared to last month? )
Pretty dam insulting from somewhere in the pipe? Not sure if it's Intel. Or it's resellers clinging on to greedy margins not reflecting the savings to save their own ass's and bottom line due to stock considerations? Which iz no excuse considering the writing was on the wall. Someone needs to do a lot better. A heck of a lot better. Particularly considering I was thinking I could jes laff off AMD with an Intel savings and now have egg on my face! :)
rpns - Saturday, March 4, 2017 - link
The 'Test Bed Setup' section could do with some more details. E.g. what BIOS version? Windows 10 build version? Any notable driver versions?These details aren't useful just now, but also when looking back at the review a few months down the line.
jorkevyn - Saturday, March 4, 2017 - link
why they don't get 4 channel for DDR4 memory? I think, if you get that you will may be the real I7 6950K Killersedra - Saturday, March 4, 2017 - link
have a look at this:"Many software programmers consider Intel's compiler the best optimizing compiler on the market, and it is often the preferred compiler for the most critical applications. Likewise, Intel is supplying a lot of highly optimized function libraries for many different technical and scientific applications. In many cases, there are no good alternatives to Intel's function libraries.
Unfortunately, software compiled with the Intel compiler or the Intel function libraries has inferior performance on AMD and VIA processors. The reason is that the compiler or library can make multiple versions of a piece of code, each optimized for a certain processor and instruction set, for example SSE2, SSE3, etc. The system includes a function that detects which type of CPU it is running on and chooses the optimal code path for that CPU. This is called a CPU dispatcher. However, the Intel CPU dispatcher does not only check which instruction set is supported by the CPU, it also checks the vendor ID string. If the vendor string says "GenuineIntel" then it uses the optimal code path. If the CPU is not from Intel then, in most cases, it will run the slowest possible version of the code, even if the CPU is fully compatible with a better version."
http://www.agner.org/optimize/blog/read.php?i=49&a...
HomeworldFound - Saturday, March 4, 2017 - link
Everyone here already knew that ten years ago.Notmyusualid - Sunday, March 5, 2017 - link
Indeed it was.sedra - Sunday, March 5, 2017 - link
it is worth to bring it up now.