The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTFetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
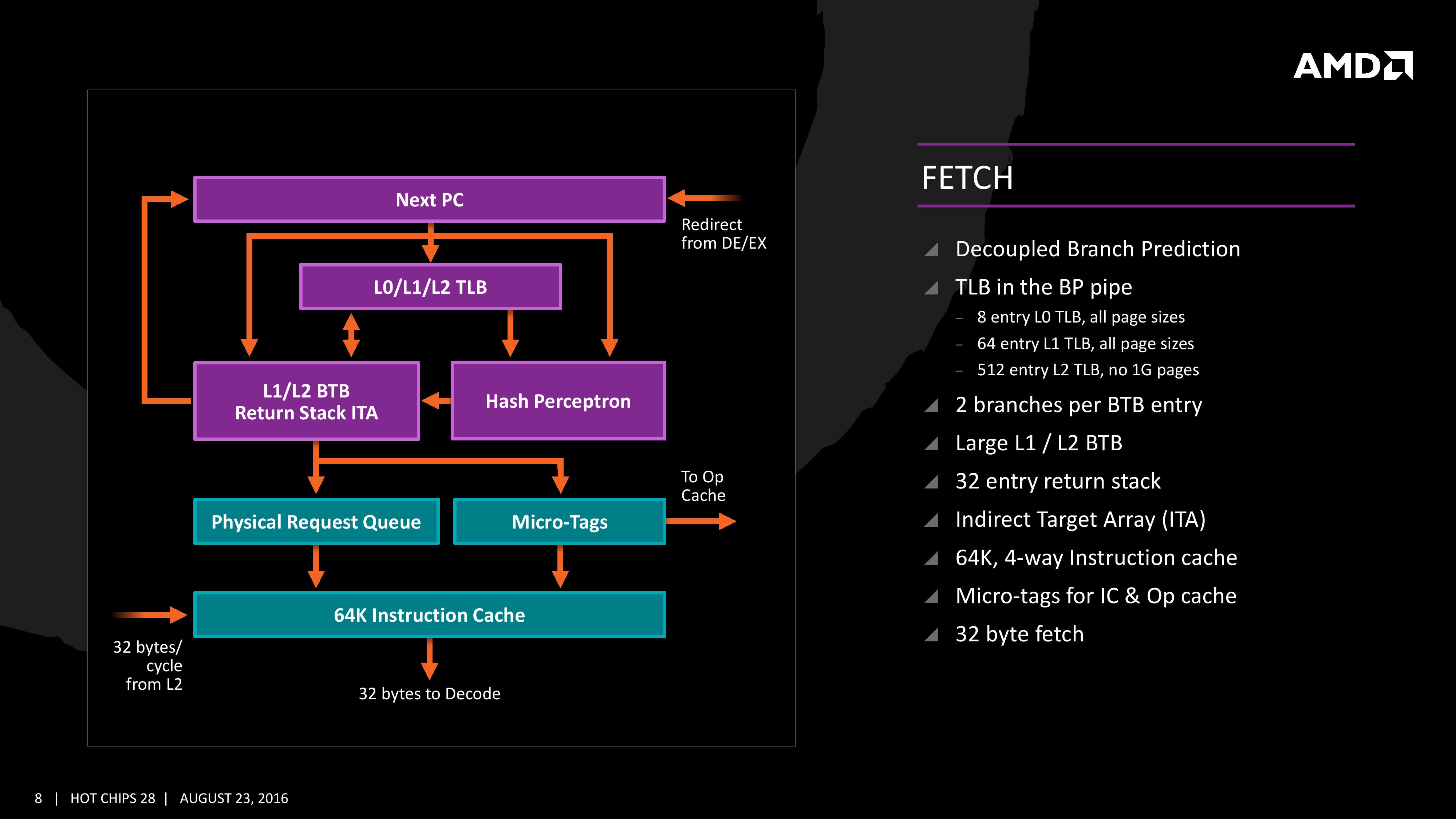
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
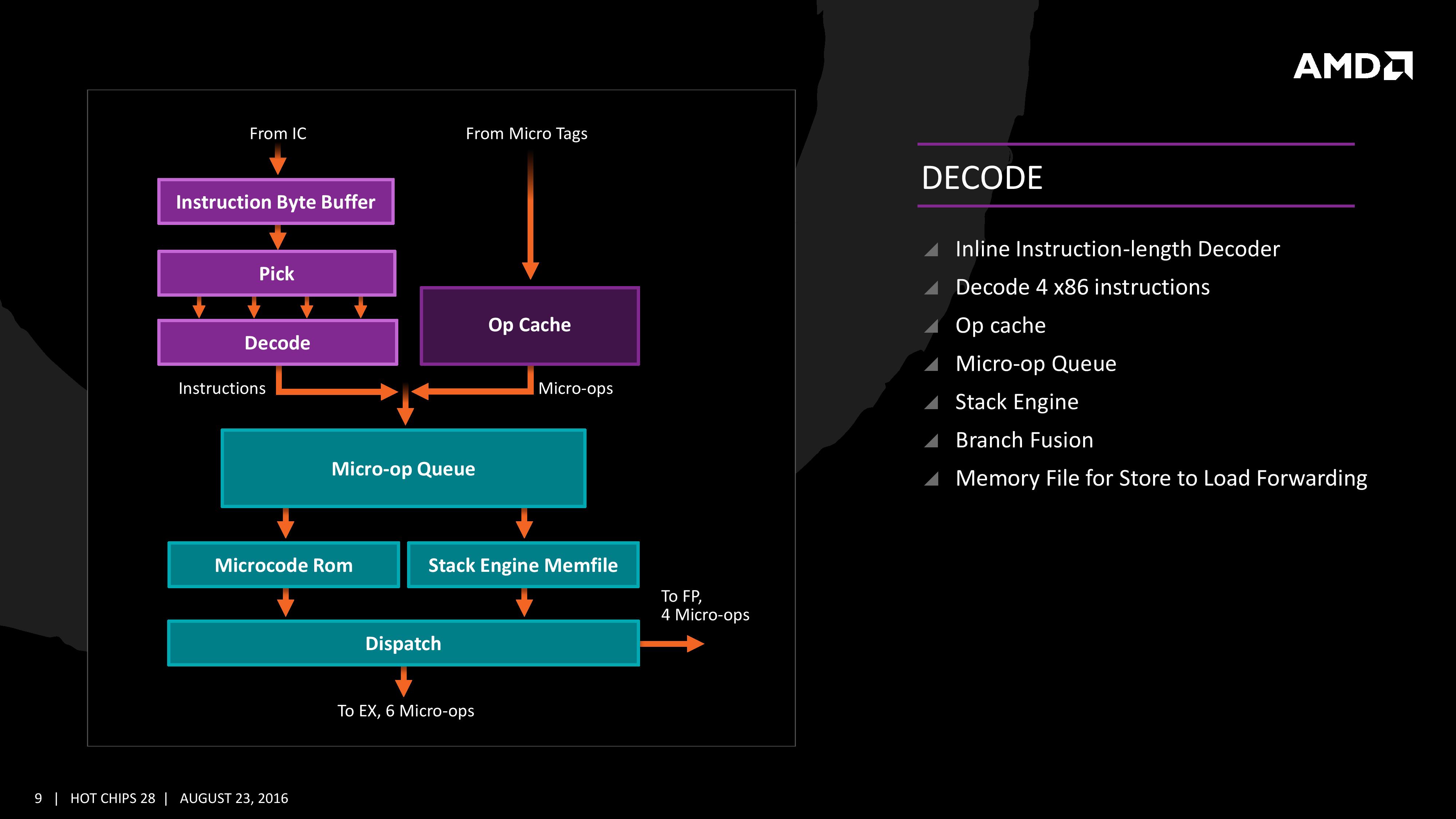
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








574 Comments
View All Comments
nt300 - Saturday, March 11, 2017 - link
The Ryzen 7 1700 is definitely the gaming choice IMO. The CPU that does well in gaming and amazing at everything else. Windows 10 hasn't been properly optimized for ZEN, so any Benchmarks and Gaming Benchmarks are not set in stone.A2Ple98 - Monday, May 22, 2017 - link
Actually Ryzen isn't for only gamers, is mostly for streamers and professionals. The cores that aren't used for gaming, they are used to encode the video you are stream. As for pro people, they get almost a i7-6900K for half the price.Sweeprshill - Thursday, March 2, 2017 - link
Does not seem to be proper English here ?Sweeprshill - Thursday, March 2, 2017 - link
n/m can't edit comments I supposent300 - Saturday, March 11, 2017 - link
Wrong, ZEN is a new design and quite innovative. Just like the past, AMD has let this industry for many years. More so when they launched the Athlon 64 with the IMC which Intel claimed was useless and a waste of die space. That Athlon 64 at 1000 MHz less clock speed smoked any Intel chip you put it against.My point, ZEN is new, and both ZEN and Intel chips are unique in there own way, might share some similarities, but nevertheless they are different.
nos024 - Thursday, March 2, 2017 - link
Nope. Ryzen will need to drop in price. $500 1800x is still too expensive. According to this even a 7700k @ $300 -$350 is still a good choice for gamers.2011-v3 still offers a platform with more PCIe3 lanes and quad memory channel. I thought about an 1800x and 370 mobo combo, but that costs similar to a 6850k with x99.
Sorry, ill stick to intel this time around. Good that ryzen caused a ripple in price war though.
Gothmoth - Thursday, March 2, 2017 - link
gamer... as if the world is only full with idiotic people who waste their lives playing shooter or RPG´s.nos024 - Thursday, March 2, 2017 - link
Ikr? Whatever makes your world go round man.brushrop03 - Thursday, March 2, 2017 - link
Well playedAndrewJacksonZA - Thursday, March 2, 2017 - link
lol