The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTFetch
For Zen, AMD has implemented a decoupled branch predictor. This allows support to speculate on incoming instruction pointers to fill a queue, as well as look for direct and indirect targets. The branch target buffer (BTB) for Zen is described as ‘large’ but with no numbers as of yet, however there is an L1/L2 hierarchical arrangement for the BTB. For comparison, Bulldozer afforded a 512-entry, 4-way L1 BTB with a single cycle latency, and a 5120 entry, 5-way L2 BTB with additional latency; AMD doesn’t state that Zen is larger, just that it is large and supports dual branches. The 32 entry return stack for indirect targets is also devoid of entry numbers at this point as well.
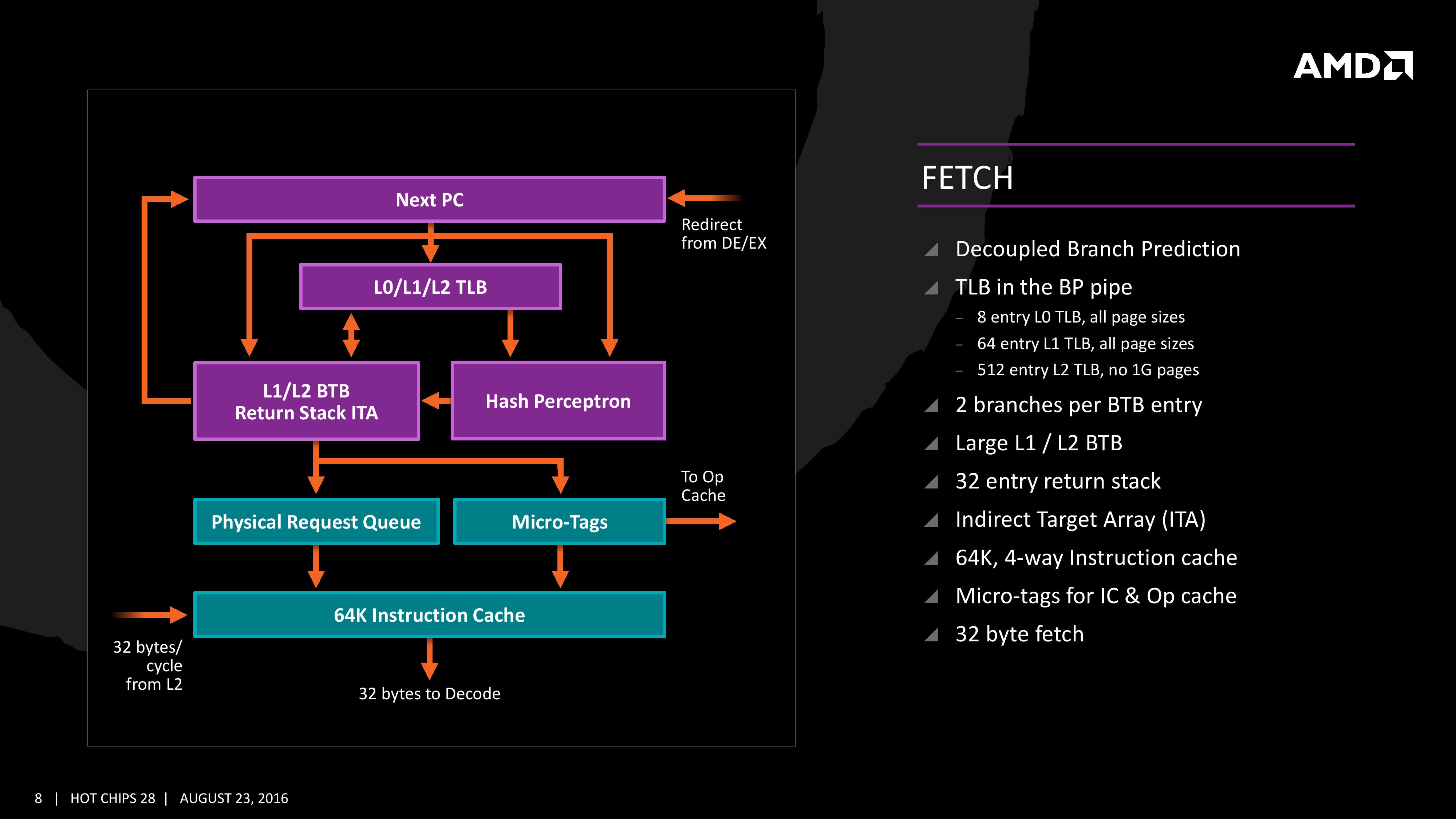
The decoupled branch predictor also allows it to run ahead of instruction fetches and fill the queues based on the internal algorithms. Going too far into a specific branch that fails will obviously incur a power penalty, but successes will help with latency and memory parallelism.
The Translation Lookaside Buffer (TLB) in the branch prediction looks for recent virtual memory translations of physical addresses to reduce load latency, and operates in three levels: L0 with 8 entries of any page size, L1 with 64 entries of any page size, and L2 with 512 entries and support for 4K and 256K pages only. The L2 won’t support 1G pages as the L1 can already support 64 of them, and implementing 1G support at the L2 level is a more complex addition (there may also be power/die area benefits).
When the instruction comes through as a recently used one, it acquires a micro-tag and is set via the op-cache, otherwise it is placed into the instruction cache for decode. The L1-Instruction Cache can also accept 32 Bytes/cycle from the L2 cache as other instructions are placed through the load/store unit for another cycle around for execution.
Decode
The instruction cache will then send the data through the decoder, which can decode four instructions per cycle. As mentioned previously, the decoder can fuse operations together in a fast-path, such that a single micro-op will go through to the micro-op queue but still represent two instructions, but these will be split when hitting the schedulers. The purpose of this allows the system to fit more into the micro-op queue and afford a higher throughput when possible.
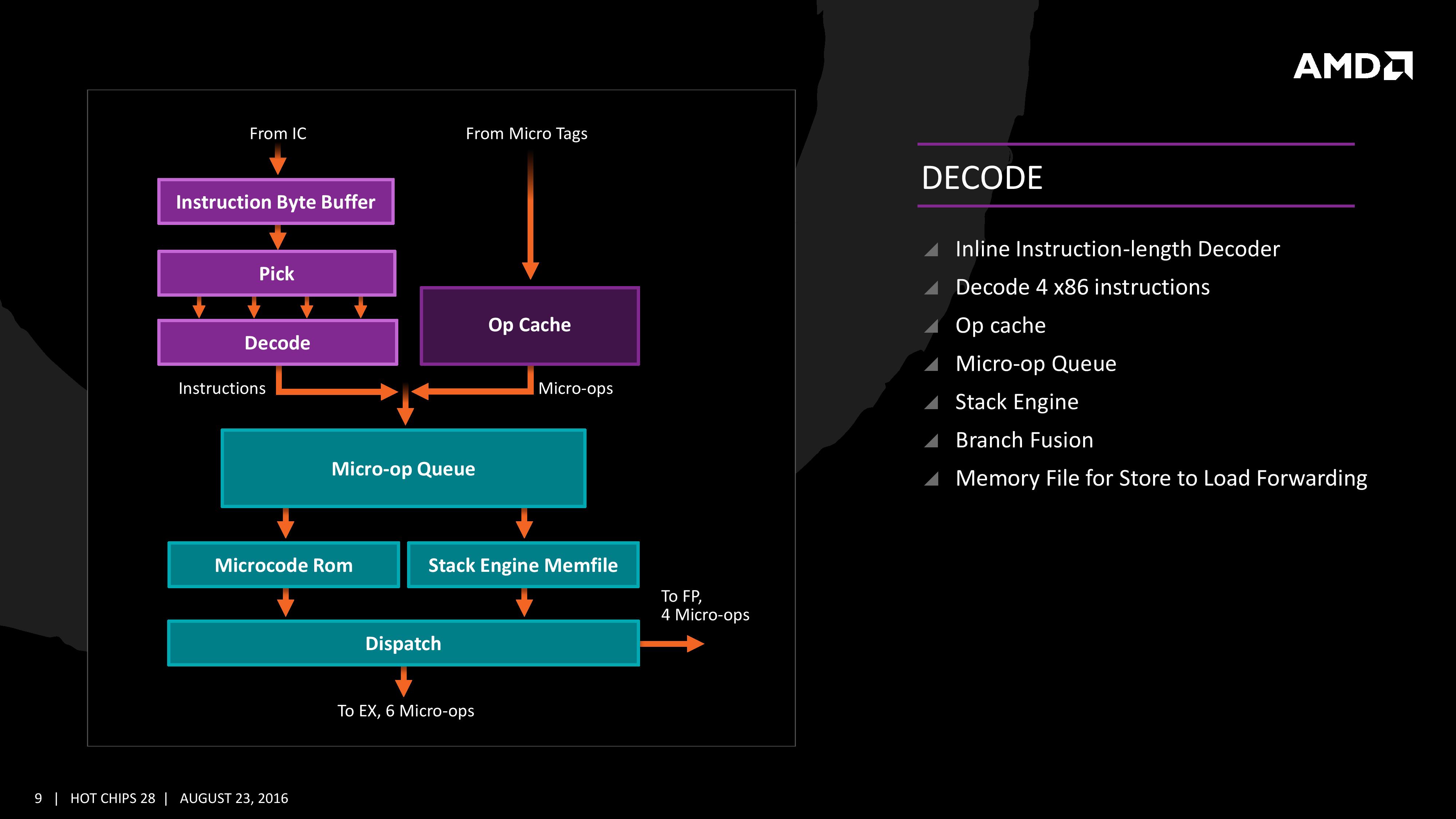
The new Stack Engine comes into play between the queue and the dispatch, allowing for a low-power address generation when it is already known from previous cycles. This allows the system to save power from going through the AGU and cycling back around to the caches.
Finally, the dispatch can apply six instructions per cycle, at a maximum rate of 6/cycle to the INT scheduler or 4/cycle to the FP scheduler. We confirmed with AMD that the dispatch unit can simultaneously dispatch to both INT and FP inside the same cycle, which can maximize throughput (the alternative would be to alternate each cycle, which reduces efficiency). We are told that the operations used in Zen for the uOp cache are ‘pretty dense’, and equivalent to x86 operations in most cases.








574 Comments
View All Comments
deltaFx2 - Wednesday, March 8, 2017 - link
@Meteor2: No. Consumer GPUs have poor throughput for Double precision FP. So you can't push those to the GPU (unless you own those super-expensive Nvidia compute cards). Apparently, many rendering/video editing programs use GPUs for preview but do the final rendering on CPU. Quality, apparently, and might be related to DP FP. I'm not the expert, so if you know otherwise, I'd be happy to be corrected and educated. Also, you could make the same argument about AVX-256.The quoted paragraph is probably the only balanced statement in that entire review. Compare the tone of that review with AT review above.
On an unrelated note, there's the larger question of running games at low res on top-end gpus and comparing frame-rates that far exceed human perception. I know, they have to do something, so why not just do this. The rationale is: " In future a faster GPU in future will create a bottleneck ". If this is true, it should be easy to demonstrate, right? Just dig through a history of Intel desktop CPUs paired with increasingly powerful GPUs and see how it trends. There's not one reviewer that has proven that this is true. It's being taken as gospel. OTOH, plenty of folks seem happy with their Sandy Bridge + Nvidia 1080, so clearly the bottleneck isn't here 5 years after SB. Maybe, just maybe, it's because the differences are imperceptible?
Ryzen clearly has some bottlenecks but the whole gaming thing is a tempest in a tea-cup.
theuglyman0war - Thursday, March 9, 2017 - link
ZBRUSHprobably 90% of all 3d assets that are created from concept ( NOT SCANNED )
Went through Zbrush at some point.
Which means no GPU acceleration at all.
Renderman
Maxwell
Vray
Arnold
still all use CPU rendering As do a mountain of other renderers.
Arnold will be getting an option
But the two popular GPU renderers are Otoy Octane and Redshift...
The have their excellent expensive place. But the majority of rendering out there is still suffered through software rendering. And will always be a valid concern as long as they come FREE built into major DCC applications.
theuglyman0war - Thursday, March 9, 2017 - link
Saw that same GPU trumps CPU render validity concerns...Comment and had a good laugh.
I'll remember to spread that around every time I see Renderman Vray Arnold Maxwell sans GPU rendering going on.
Or the next time a Mercury engine update negates all non Quadro GPU acceleration.
To be fair a lot of creative pros and tech artists seem to disagree with me but...
The only time between pulling vrts in Maya and brushing a surface in Zbrush that I really feel that I am suffering buckets of tears and desire a new CPU ( still on i7-980x ) is when I am cussing out a progress bar that is teasing me with it's slow progress. And that means CORES! encoding... un compressing... Rendering! Otherwise I could probably not notice day to day on a ten year old CPU. ( excluding CPU bound gaming of course... talking bout day to day vrt pulling )
I was just as productive in 2007 as I am today.
MaidoMaido - Saturday, March 4, 2017 - link
Been trying to find a review including practical benchmarks for common video editing / motion graphics applications like After Effects, Resolve, Fusion, Premiere, Element 3D.In a lot of these tasks, the multithreading is not always the best, as a result quad core 6700K often outperforms the more expensive Xeon and 5960X etc
deltaFx2 - Saturday, March 4, 2017 - link
I would recommend this response to the GamersNexus hit piece: https://www.reddit.com/r/Amd/comments/5xgonu/analy...The i5 level performance is a lie.
Notmyusualid - Saturday, March 4, 2017 - link
@ deltaFx2Sorry, not reading a 4k worded response. I'll wait for Anand to finish its Ryzen reviews before I draw any final conclusions.
Meteor2 - Tuesday, March 7, 2017 - link
@deltaFX2 RE: in the 4k word Reddit 'rebuttal', what that person seems to be saying, is that once you've converted your $500 Ryzen 1800X into a 8C/8T chip, _then_ it beats a $240 i5, while still falling short of the $330 i7. Out-of-the-box, it has worse gaming performance than either Intel chip.That's not exactly a ringing endorsement.
The analysis in the Anandtech forums, which concludes that in a certain narrow and low power band a heavily down-clocked 1800X happens to get excellent performance/W, isn't exactly thrilling either.
deltaFx2 - Wednesday, March 8, 2017 - link
@ Meteor2: The anandtech forum thing: Perf/watt matters for servers and laptop. Take a look at the IPC numbers too. His average is that Zen == Broadwell IPC, and ~10% behind Sky/Kaby lake (except for AVX256 workloads). That's not too shabby at all for a $300 part.You completely missed the point of the reddit rebuttal. The GN reviewer drops i5s from plenty of tests citing "methodological reasons", but then says R7==i5 in gaming. The argument is that plenty of games use >4 threads and that puts i5 at a disadvantage.
tankNZ - Sunday, March 5, 2017 - link
yes I agree, it's even better than okay for gaming[img]http://smsh.me/li3a.png[/img]deltaFx2 - Monday, March 6, 2017 - link
You may wish to see this though: https://forums.anandtech.com/threads/ryzen-strictl... Way, way, more detailed than any tech media review site can hope to get. No, it's got nothing to do with gaming. Gaming isn't the story here. AMD's current situation in x86 market share had little to do with gaming efficiency, but perf/watt.I'll quote the author: "850 points in Cinebench 15 at 30W is quite telling. Or not telling, but absolutely massive. Zeppelin can reach absolutely monstrous and unseen levels of efficiency, as long as it operates within its ideal frequency range."