NVIDIA Announces Tesla P40 & Tesla P4 - Neural Network Inference, Big & Small
by Ryan Smith on September 13, 2016 1:45 AM EST- Posted in
- GPUs
- Tesla
- NVIDIA
- Pascal
- Machine Learning

Over the last few months we have seen NVIDIA’s Pascal GPUs roll out among their consumer cards, and now the time has come for the Tesla line to get its own Pascal update. To that end, at today’s GTC Beijing 2016 keynote, NVIDIA CEO Jen-Hsun Huang has announced the next generation of NVIDIA’s neural network inferencing cards, the Tesla P40 and Tesla P4. These cards are the direct successor to the current Tesla M40 and M4 products, and with the addition of the Pascal architecture, NVIDIA is promising a major leap in inferencing performance.
We’ve covered NVIDIA’s presence in and plans for the deep learning market for some time now. Overall the deep learning market is a rapidly growing market, and one that has proven very successful for NVIDIA as the underlying neural networks map well to their GPU architectures. As a result, one of the focuses of the Pascal has been to further improve on neural network performance, primarily by improving the performance of lower precision operations. The company already saw strong sales in this market on the last-generation Maxwell architecture, and with Pascal they’re aiming to push things to a whole new level.
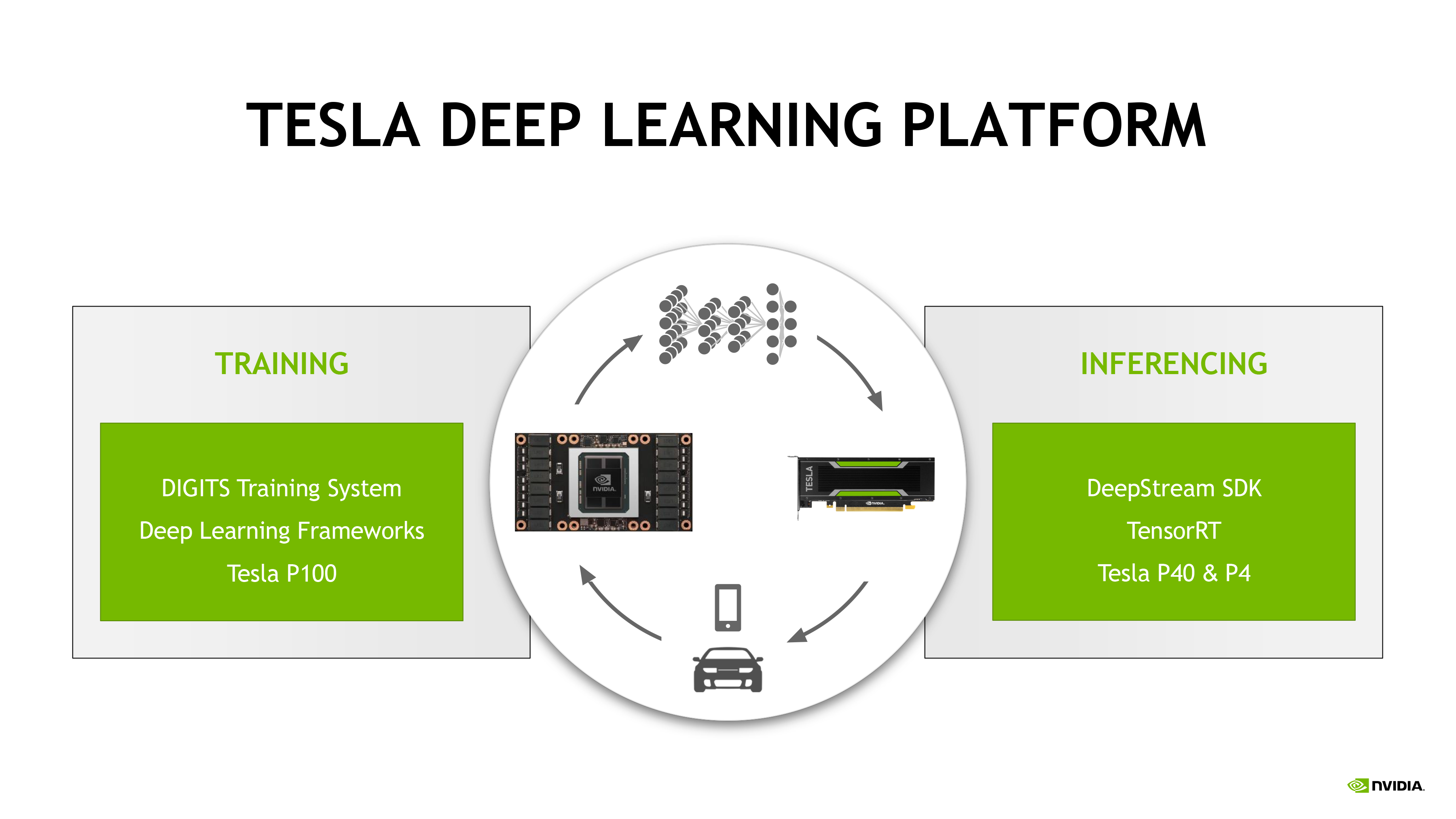
Within NVIDIA’s product stack for deep learning, they have opted to divide it into two categories of products: training cards and inferencing cards. Neural network training, which typically requires FP16 performance and a whole lot of horsepower, is handled by the likes of the Tesla P100 series, the only cards in NVIDIA’s lineup with a high performance FP16 mode. Meanwhile, because inferencing can be done with less precision on a smaller scale, NVIDIA has offered the M40/M4 cards, and now the P40/P4 cards for this task. With the training side having received its Pascal update earlier this year with the launch of the P100, NVIDIA is now catching up the inference side with today’s announcement of the Tesla P40 and P4.
| NVIDIA Tesla Inferencing Cards | ||||||
| Tesla P40 | Tesla P4 | Tesla M40 | Tesla M4 | |||
| CUDA Cores | 3840 | 2560 | 3072 | 1024 | ||
| Base Clock | 1303MHz | 810MHz | 948MHz | 872MHz | ||
| Boost Clock | 1531MHz | 1063MHz | 1114MHz | 1072MHz | ||
| Memory Clock | 7.2Gbps GDDR5 | 6Gbps GDDR5 | 6Gbps GDDR5 | 5.5Gbps GDDR5 | ||
| Memory Bus Width | 384-bit | 256-bit | 384-bit | 128-bit | ||
| VRAM | 24GB | 8GB | 12GB/24GB | 4GB | ||
| Single Precision (FP32) | 12 TFLOPS | 5.5 TFLOPS | 7 TFLOPS | 2.2 TFLOPS | ||
| INT8 | 47 TOPS | 22 TOPS | N/A | N/A | ||
| Transistor Count | 12B | 7.2B | 8B | 2.94B | ||
| TDP | 250W | 50W-75W | 250W | 50W-75W | ||
| Cooling | Passive | Passive (Low Profile) |
Passive | Passive (Low Profile) |
||
| Manufacturing Process | TSMC 16nm | TSMC 16nm | TSMC 28nm | TSMC 28nm | ||
| GPU | GP102 | GP104 | GM200 | GM206 | ||
By and large, the P40 and P4 are direct successors to their Maxwell counterparts. NVIDIA has retained the same form factor, the same power ratings, and of course the same target market. What’s new is the Pascal architecture, the underlying GPUs, and what they can do for inferencing performance.
Inferencing itself is not a high precision operation. While the last-generation Tesla M-series cards operated at FP32 precision out of necessity – it’s what the hardware could support – the operations themselves can be done on much less. NVIDIA believes FP16 is sufficient for training, and meanwhile inferencing can go even lower, to 8-bit Integers (INT8). To that end, the Pascal GPUs being used in these products, GP102 and GP104, include additional support for high-speed INT8 operations, offering an 8-bit vector dot product with 32-bit accumulate. Put another way, in the place of a single FP32 FMA, a Pascal CUDA Core can perform 4 INT8 operations.
Combined with the overall improvements in GPU width and frequency on the Pascal architecture, and NVIDIA is touting the Tesla P40 & P4 to offer a major boost in inferencing performance, the kind of performance boost in a single generation that we rarely see in the first place, and likely won’t see again. On paper, on the best case scenario, the newer Tesla cards can offer upwards of several times the performance, with NVIDIA specifically promoting real-world performance gains of 4x in large GPU clusters.
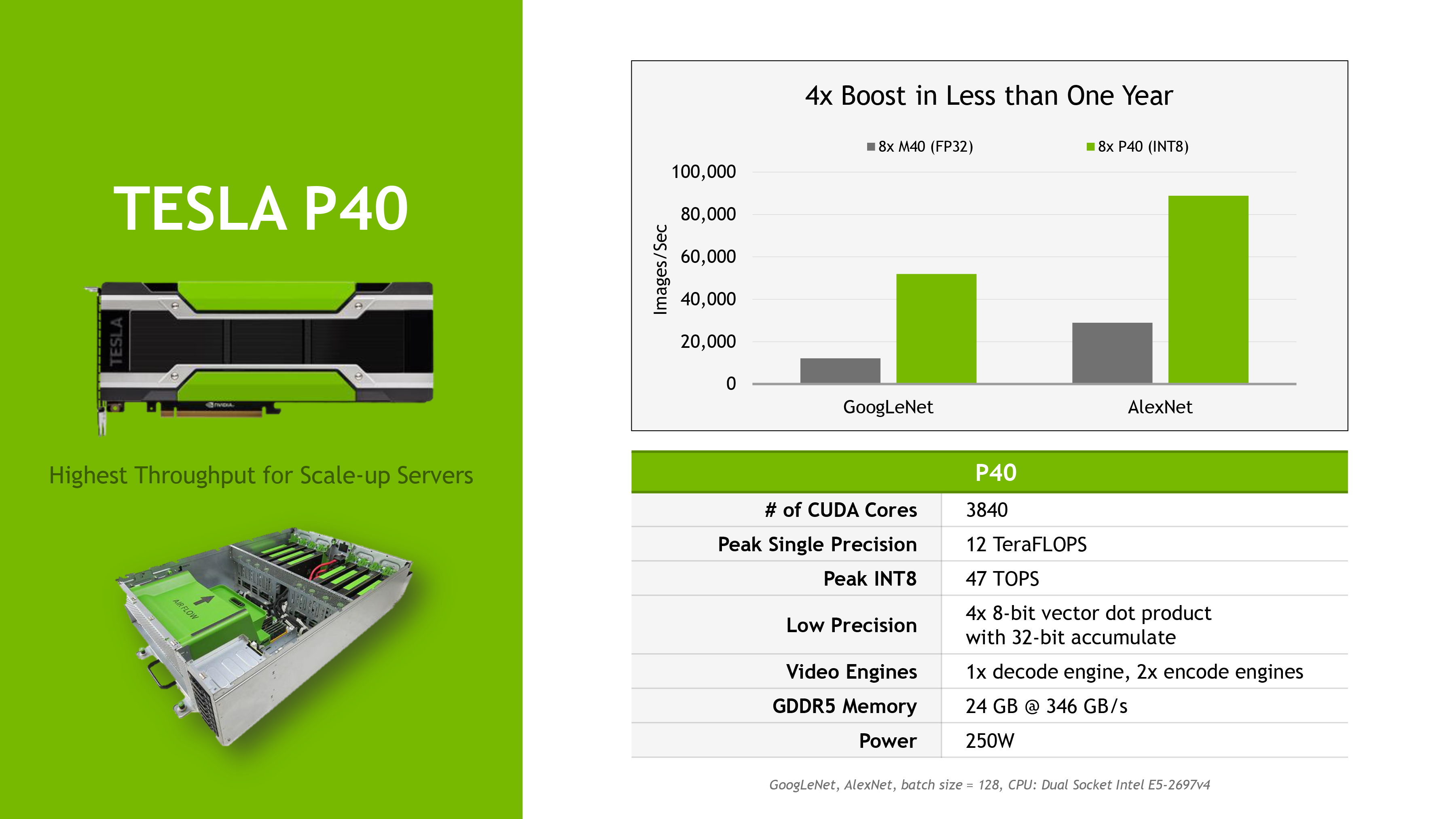
Breaking things down by the cards themselves, we’ll start with the P40. The successor to last year’s M40, this card is a full performance 250W card designed for high performance servers holding one or more full-profile cards. The card is based on a fully enabled GP102 GPU, meaning all 3840 CUDA cores are active, and can boost up to 1.53GHz. Peak FP32 performance is 12 TFLOPs, while peak INT8 performance is 47 TOPS. This compares very favorably to the M40, which could offer 7 TFLOPS FP32, and lacked INT8 support entirely. The Pascal architecture alone offers a significant performance boost thanks to the wider GPU and higher clocks, but for customers that can make use of the INT8 functionality, the potential performance gains are immense.
Feeding the P40 is 24GB of GDDR5 clocked at 7.2Gbps. This is on a 384-bit memory bus, so we’re looking at a total memory bandwidth of 346GB/sec. Curiously, NVIDIA has opted not to use faster GDDR5X memory here despite the higher margins of the Tesla products, and this may have something to do with the tradeoffs the GDDR5X standard makes for its higher performance. Otherwise the card retains its predecessor’s 250W TDP, and a passive, full length/full height card design.

Meanwhile at the smaller end of the spectrum is the Tesla P4. Like the M4 before it, this card is designed for blade servers. As a result the card is both physically smaller and lower power in order to fit into those servers, utilizing a low-profile design and a TDP of either 50W or 75W depending on the configuration.
Under the hood, the P4 is based on the GP104 GPU. This GPU is fully enabled – so we’re looking at 2560 CUDA cores – however for power reasons the clockspeed is kept relatively low, boosting to just 1.06GHz. The memory clock is similarly reduced over full power GP104 products, with the 8GB of GDDR5 running at 6Gbps. Overall performance is rated at 5.5 TFLOPS for FP32, and 22 TOPS for INT8. Like the P40, the P4 stands to be significantly faster than its predecessor if developers can put the INT8 functionality to good use, as the M4 topped out at 2.2 TFLOPS FP32.

Within NVIDIA’s lineup, the reason for having two cards – besides the obvious factor of size – is scale, both in terms of physical configuration and in terms of performance scaling. Tesla P40 is being pitched as the highest performance available in a single card, while Tesla P4 offers better density. The difference on paper in terms of energy efficiency is pretty substantial; Tesla P40 requires about 50% more power per FLOP on paper. So installations that can scale massively across multiple GPUs are considered the prime market for the P4, while the P40 is aimed at applications that scale out to a handful of GPUs, and as a result need the most powerful GPUs available.
Moving on, along with the hardware announcement NVIDIA is also releasing a pair of new software products to go with the Tesla cards. These are the TensorRT library and the DeepStream SDK.
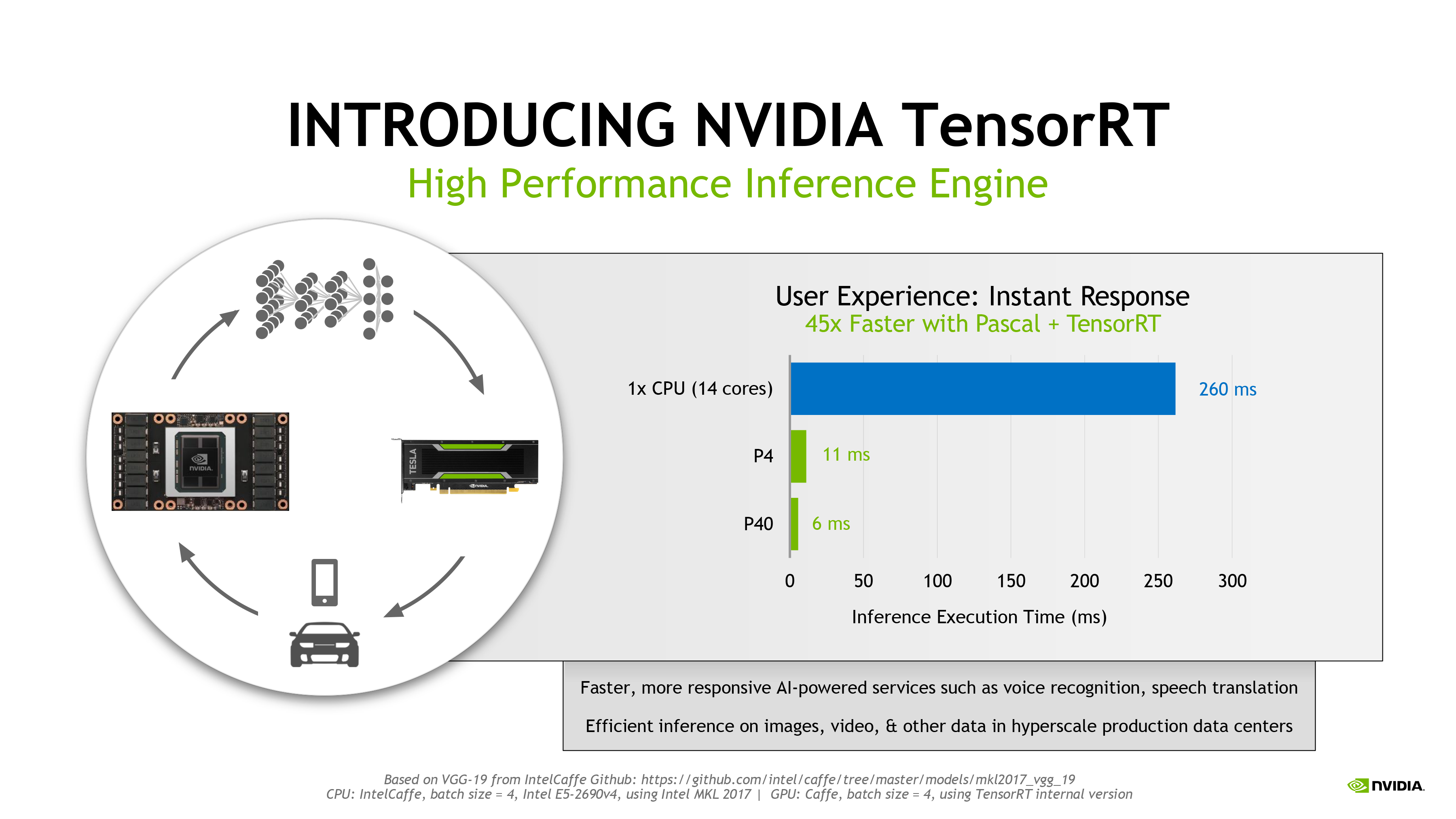
TensorRT, previously known as the GPU Inference Engine, is an inference engine library NVIDIA has developed, in large part, to help developers take advantage of the capabilities of Pascal. Its key feature here is that it’s designed to help developers move their already trained FP16/FP32 neural nets over to the INT8 capabilities of Pascal. Given that INT8 can quadruple the performance of inference on an NVIDIA GPU, and you can see why NVIDIA is eager to provide developers with tools to help them utilize lower precision operations.
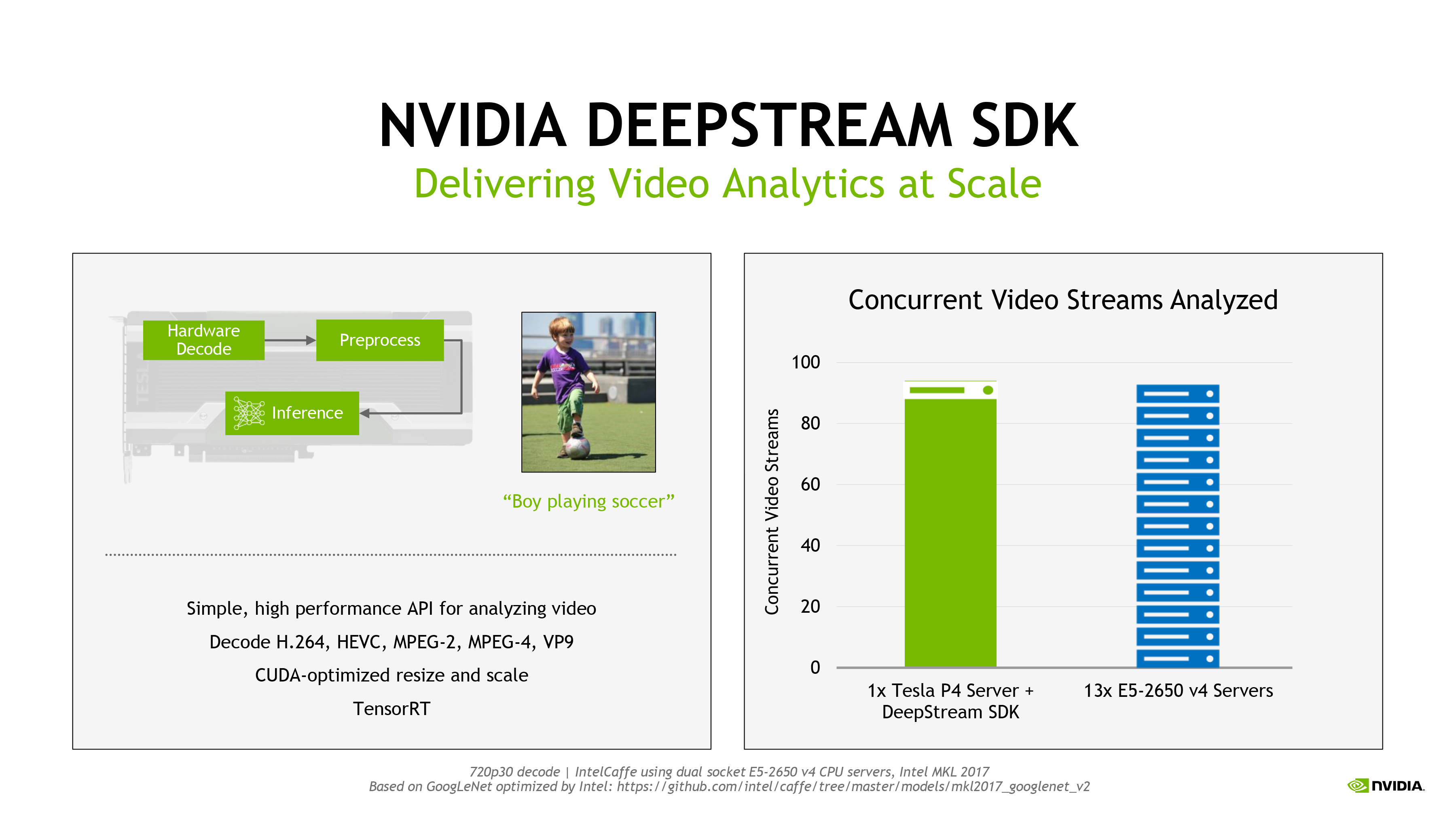
Meanwhile the DeepStream SDK is a video processing library that delivers on some of NVIDIA’s goals for video processing made at GTC 2016 earlier this year. A counterpart of sorts to TensorRT, it’s a high performance video analysis SDK that links Pascal’s video decode blocks with the TensorRT inference engine to allow full video decode and analysis to take place on a Tesla card. NVIDIA sees video analysis as being one of the big use cases for large scale farms of trained neural networks, so this is another case of them providing a software package to help kickstart that market.
Wrapping things up, as is common with Tesla product releases, today’s announcements will predate the hardware itself by a bit. NVIDIA tells us that the Tesla P40 will be available in October through the usual OEMs and channel partners. Meanwhile the Tesla P4 will be released a month later, in November. NVIDIA has not announced card pricing at this time.






Source: NVIDIA








36 Comments
View All Comments
Yojimbo - Tuesday, September 13, 2016 - link
INT8 is just an 8 bit integer calculation. The ability was there. It's like saying there was no true FP16 capability in hardware until Pascal (or the Tegra X1). That's not accurate. It just wasn't accelerated with special instructions. For instance, one could say that Maxwell had INT8 TOPS at 1/2 FP32 FLOPS.As far as the software, it's the key component. It's not just "adding software to help..." It's the reason AMD is not really a competitor in this space even though their hardware is fully capable. The software (CUDA, cuDNN, TensorRT, etc) is more important that the IDP4A instruction.
As far as specialization, NVIDIA's strategy is not one of specialization. Adding instructions to accelerate certain key components isn't really specialization, it's just catering a general purpose processor to a popular use case. Other companies are going the specialization route, however. Google with their TPU, Nervana with the Nervana Engine, Intel with Knights Mill, and perhaps with FPGAs (and Nervana Engine now that they have bought Nervana). Which is the preferable strategy will shake out over the next few years I guess. As for Volta, my guess is that it will focus mostly on architectural efficiency of the SMs, something which Pascal forwent in favor of adding features such as mixed precision, INT 8, NVLink, and finer-grained pre-emption, as well as pipeline optimizations allowing for higher clock speeds. NVIDIA promises an improved NVLink and a significant improvement in performance per Watt without a die shrink for Volta. That could already be a lot on the plate for what appears to be a short turnaround from Pascal to Volta, judging by the Summit supercomputer schedule. Perhaps they will add some more capabilities targeted at deep learning but Volta will remain a general purpose processor. NVIDIA have stated to their investors and to those in the industry they are trying to get to buy their products that building general purpose processors is their strategy.
"I checked and this seems to be the case. A source of info was http://www.anandtech.com/show/10510/nvidia-announc...
The article says: "With the exception of INT8 support, this is a bigger GP104 throughout." But the P4 is based on the GP104 and has the faster INT8 throughput. I'd like to find confirmation that either the IPD4A instruction cannot be run on the 1080 or that it runs at a reduced rate.
ajp_anton - Tuesday, September 13, 2016 - link
"this may have something to do with the tradeoffs the GDDR5X standard makes for its higher performance"What are these tradeoffs?
MrSpadge - Tuesday, September 13, 2016 - link
The prime candidate is power efficiency. However, GDDR5X is said to be more efficient at the same transfer speed. Maybe this doesn't apply at those relatively low GDDR5 clocks?Ryan Smith - Tuesday, September 13, 2016 - link
One of the changes to GDDR5X was how error correction works. I'm not 100% sure whether GDDR5X can support Soft ECC like GDDR5 can.Eric Klien - Wednesday, September 14, 2016 - link
GDDR5 can support soft-ECC. See http://www.anandtech.com/show/10516/nvidia-announc...Eric Klien - Wednesday, September 14, 2016 - link
I meant GDDR5X can support soft-ECC. See http://www.anandtech.com/show/10516/nvidia-announc...TheinsanegamerN - Tuesday, September 13, 2016 - link
So nvidia can stick a GPU that big onto a low profile GPU, but refuses to give us a decent 750ti replacement. That's rather annoying. I want a GPU that powerful in my tiny HTPC box!(and yes I know they get away with it based on how servers cool their GPUs. Still annoying that we cant even get a 1060 low profile or near a 50 watt TDP, yet this 2560 core part has a 50-75 watt TDP.)
MrSpadge - Tuesday, September 13, 2016 - link
GTX 1060 can do it. In regular compute workloads mine uses ~95 W running at 2.0 GHz. I can lower its power target to 70 W and it still runs at ~1.8 GHz. At games you might see 1.5 - 1.7 GHz at 70 W, which is easy to cool unless your case is extremely contrained.Michael Bay - Tuesday, September 13, 2016 - link
You see, 750ti was a htpc king. 1060 can`t be that, since it want sexternal power.Yojimbo - Tuesday, September 13, 2016 - link
Well the 1050 should be coming out soon. It's rated at 75W TDP.But two things. Firstly, the P4 is probably going to sell for a lot more than you'd be willing to pay for an HTPC GPU. Secondly, the amount of revenue they think they could get from such an HTPC GPU probably isn't very much, whereas the P4 is a key product in their strategy to capture the burgeoning machine learning market. It costs resources to design, market, and sell a product.