AMD Zen Microarchitecture: Dual Schedulers, Micro-Op Cache and Memory Hierarchy Revealed
by Ian Cutress on August 18, 2016 9:00 AM EST
In their own side event this week, AMD invited select members of the press and analysts to come and discuss the next layer of Zen details. In this piece, we’re discussing the microarchitecture announcements that were made, as well as a look to see how this compares to previous generations of AMD core designs.
AMD Zen
Prediction, Decode, Queues and Execution
First up, let’s dive right into the block diagram as shown:
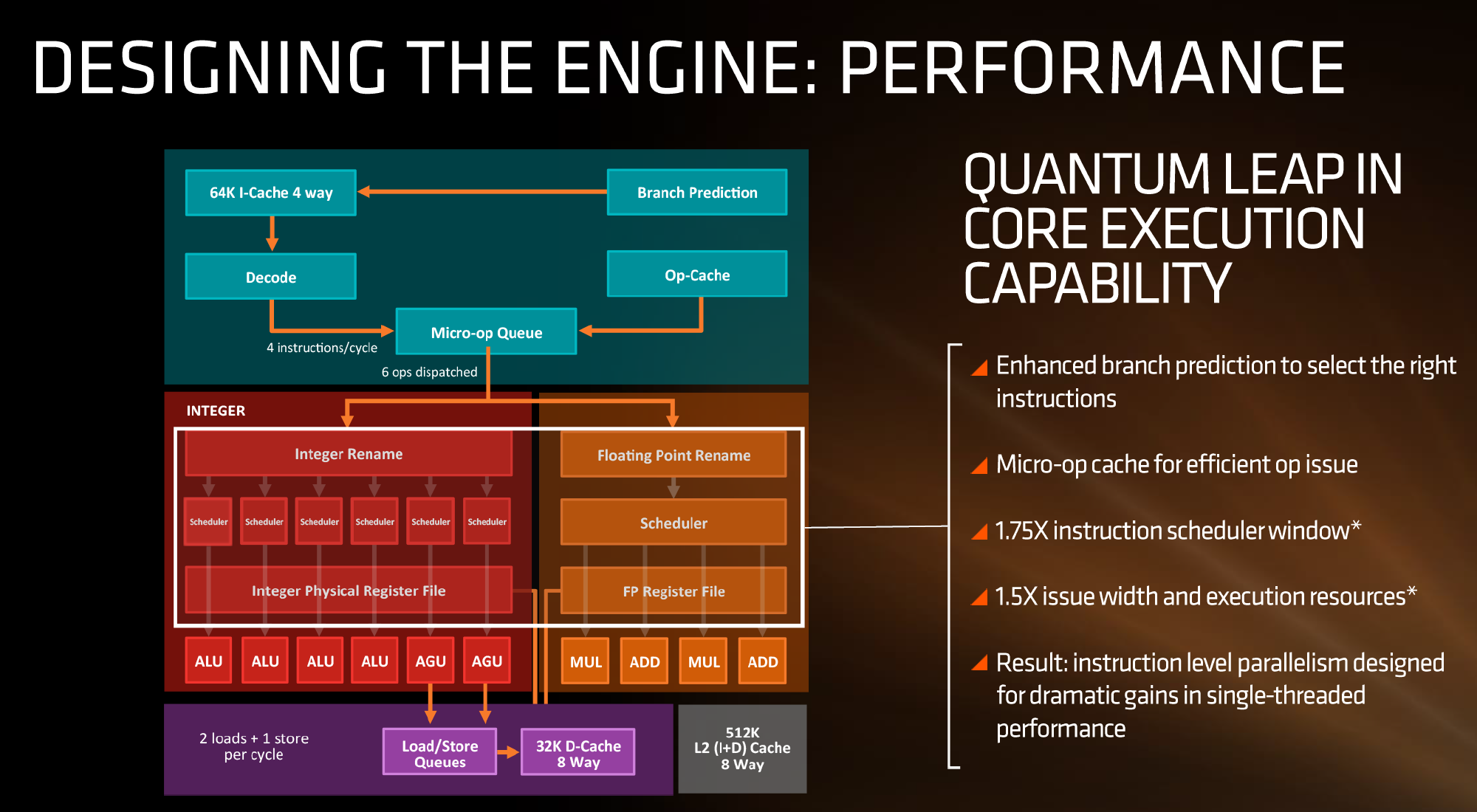
If we focus purely on the left to start, we can see most of the high-level microarchitecture details including basic caches, the new inclusion of an op-cache, some details about decoders and dispatch, scheduler arrangements, execution ports and load/store arrangements. A number of slides later in the presentation talk about cache bandwidth.
Firstly, one of the bigger deviations from previous AMD microarchitecture designs is the presence of a micro-op cache (it might be worth noting that these slides sometimes say op when it means micro-op, creating a little confusion). AMD’s Bulldozer design did not have an operation cache, requiring it to fetch details from other caches to implement frequently used micro-ops. Intel has been implementing a similar arrangement for several generations to great effect (some put it as a major stepping stone for Conroe), so to see one here is quite promising for AMD. We weren’t told the scale or extent of this buffer, and AMD will perhaps give that information in due course.
Aside from the as-expected ‘branch predictor enhancements’, which are as vague as they sound, AMD has not disclosed the decoder arrangements in Zen at this time, but has listed that they can decode four instructions per cycle to feed into the operations queue. This queue, with the help of the op-cache, can deliver 6 ops/cycle to the schedulers. The reasons behind the queue being able to dispatch more per cycle is if the decoder can supply an instruction which then falls into two micro-ops (which makes the instruction vs micro-op definitions even muddier). Nevertheless, this micro-op queue helps feed the separate integer and floating point segments of the CPU. Unlike Intel who uses a combined scheduler for INT/FP, AMD’s diagram suggests that they will remain separate with their own schedulers at this time.
The INT side of the core will funnel the ALU operations as well as the AGU/load and store ops. The load/store units can perform 2 16-Byte loads and one 16-Byte store per cycle, making use of the 32 KB 8-way set associative write-back L1 Data cache. AMD has explicitly made this a write back cache rather than the write through cache we saw in Bulldozer that was a source of a lot of idle time in particular code paths. AMD is also stating that the load/stores will have lower latency within the caches, but has not explained to what extent they have improved.
The FP side of the core will afford two multiply ports and two ADD ports, which should allow for two joined FMAC operations or one 256-bit AVX per cycle. The combination of the INT and FP segments means that AMD is going for a wide core and looking to exploit a significant amount of instruction level parallelism. How much it will be able to depends on the caches and the reorder buffers – no real data on the buffers has been given at this time, except that the cores will have a +75% bigger instruction scheduler window for ordering operations and a +50% wider issue width for potential throughput. The wider cores, all other things being sufficient, will also allow AMD’s implementation of simultaneous multithreading to potentially take advantage of multiple threads with a linear and naturally low IPC.








216 Comments
View All Comments
willis936 - Thursday, August 18, 2016 - link
I thought the zen hype was all noise but if they're actually doing what they're claiming they may make up a lot of ground here.BrokenCrayons - Thursday, August 18, 2016 - link
I'd be cautious about that. If AMD was expecting to be extremely competitive, I think the company would be keeping a closer hold on architectural details so as to catch Intel more by surprise. Instead, they're leaning more toward full disclosure which means they're looking to build hype with consumers. One could read into that openness as a harbinger of a mediocre product launch for which Intel might already be well-prepared to meet.And if that's true, I'd be disappointed. We need a more competitive market to kick things along a little even if it won't last for very long thanks to the ever-increasing difficulty in developing smaller transistors.
nandnandnand - Thursday, August 18, 2016 - link
Zen is getting a one time massive boost in IPC due to correcting the failed architecture.The scientists and engineers working at AMD aren't high school dropouts. It's not crazy to think that they can put out something 75-90% as good as Intel, and undercut them on price. Namely because Moore's law is almost dead and Intel has stalled out, delaying 10nm by a year. Let's see 14nm vs. 14nm. The ever-increasing difficulty in developing smaller transistors works to AMD's benefit.
wumpus - Thursday, August 18, 2016 - link
One thing to remember is that GoFlo can't supply more than 10% of the marketshare. Even during AMD's glory days when Intel was floundering with Pentium4 and the Itanic disaster, there simply was no way to take over the market due to the simply inability to supply enough chips (which Intel was able to exploit with exclusive deals to the likes of Dell).Now with no chance of meeting, let alone exceeding the power of Intel (who has vastly more smart guys who have been literally refining this overall architecture for more than 10 years (the current uarch might not be the same as core2, but it is vastly more similar than Zen is to Bulldozer). AMD's only real chance is to find some niche they can beat Intel at, and convince the customers that want it to buy AMD (and yes, the latter is often harder than the former).
Obviously, it looks like AMD is going for the full-thread power. The catch is that *everybody* looks at full-thread power (IBM Power and any competition popping up from the ARM world), so Intel has probably spent more R&D researching how to combat that than AMD spent making the Zen. Intel already wastes enough transistors in the more expensive chips on built-in graphics (chips that will *never* use it considering the relative cost of a GPU to the CPU itself), so they can easily add more cores (which will improve benchmarks and presumably decrease AMD sales, even if they do almost nothing else in the real world than those unused graphics).
Of course, Intel seems to have hit a 10 year plateau (possibly through AMD's, IBM's and ARM's complete inability to compete*). They should certainly not be as surprised by any Intel counters as they may have been with the 1060.
* It must be said that Intel finally admitted that while ARM can't eat Intel's lunch, they can't eat ARM's lunch either. If only this was true for AMD.
mdriftmeyer - Thursday, August 18, 2016 - link
Samsung and GloFo share the same 14nm process, so yes they can provide > 10% of the market.Nagorak - Thursday, August 18, 2016 - link
There are diminishing returns on everything. Having ten times as many "smart people" maybe gives you a 10-20% advantage. AMD can see what worked for Intel and basically reverse engineer it too. The process disadvantage has been pretty much narrowed. It would not surprise me if Zen was competitive with Intel at this point.I'm not sure that I agree with Intel's decision to give up on mobile. Sure they haven't made much headway, but it made sense they were going after it, and I don't think just throwing in the towel was necessarily the right thing to do.
BrokenCrayons - Friday, August 19, 2016 - link
Reverse engineering Intel products and then incorporating those technologies into new AMD products would cause AMD to ALWAYS remain behind Intel because of the latency between reverse engineering and production. To get into that sort of a situation means AMD would never achieve a technological parity or be in a position to rise above the competition. In a competitive market, that's a path to bankruptcy and nothing else. In order to survive, AMD must be innovative, nimble, and aggressive.Kevin G - Saturday, August 20, 2016 - link
If AMD becomes popular again, they can port the design to TSMC for additional volume. They do have a minimum order agreement with GloFo but it isn't truly exclusive.FMinus - Thursday, August 18, 2016 - link
When we get to now the details of an architecture, the competition already knows about it two years ago. There's no point being quiet.jardows2 - Friday, August 19, 2016 - link
I'm not so sure about that. It's not like the GPU market where there is lots of fluidity in the technology. Intel is pretty much locked in for features/improvements for the next few years. A few details about their competitor, coming this close to release, isn't going to change anything Intel does. It's not like Intel is in the position to radically redesign Kaby Lake or Cannon Lake, and after that is so far out that it is irrelevant to Zen's launch.I think AMD is doing a smart move by releasing more details. Perhaps they feel the sting of hyping up Bulldozer so much, but releasing few details, and getting trashed in real-world performance. For Zen, release more details so the hype doesn't dwarf the reality, and give people the desire to purchase the product.