Assessing IBM's POWER8, Part 2: Server Applications on OpenPOWER
by Johan De Gelas on September 15, 2016 8:01 AM ESTSpark Benchmarking
Spark is wonderful framework, but you need some decent input data and some good coding skills to really test it. Speeding up Big Data applications is the top priority project at the lab I work for (Sizing Servers Lab of the University College of West-Flanders), so I was able to turn to the coding skills of Wannes De Smet to produce a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
We tested with Apache Spark 1.5 in standalone mode (non-clustered) as it took us a long time to make sure that the results were repetitive. For now, we keep version 1.5 to be able to compare with earlier results.
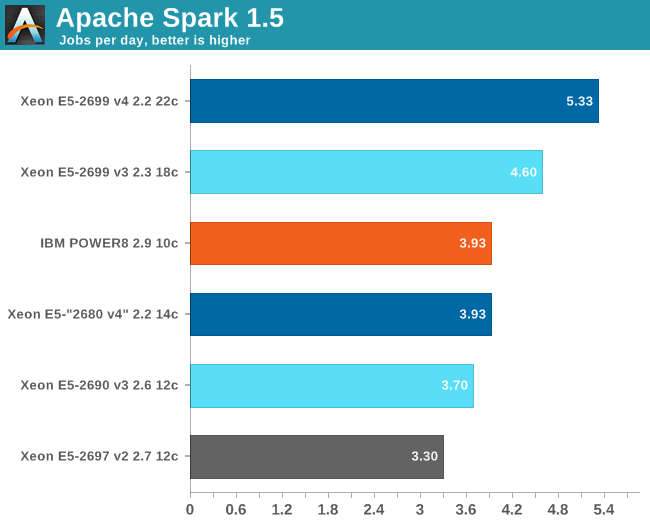
The POWER8 surprises here with excellent performance: it is able to keep with a 14 core Xeon E5 "Broadwell EP" and beats the midrange Xeon E5-2690 v3 by healthy margin. Remember, this is a midrange POWER8: there are SKUs that reach 3.4-3.8 GHz.








49 Comments
View All Comments
JohanAnandtech - Sunday, September 25, 2016 - link
Thanks Jesper. Looks like I will have to spend even more time on that system :-). And indeed, out of the box performance is important if IBM ever wants to get a piece of the x86 market.luminarian - Thursday, September 15, 2016 - link
It was my understanding that the SMT mode on the power8 could be changed. Depending on the type of work this would make a giant difference, especially with mysql/mariadb that are limited to 1 process/thread per connection.With databases the real winner would be with one that supports parallel queries, such as postgresql 9.6, db2, oracle, etc.
Also yer bench mark very easily could be limiting the power8 if its not opening enough connections to fill out the number of threads that thing can handle, remember mysql/mariaDB are 1 process/thread per connection. Alot of database bench marks default to a small number of connections, this thing has 160 threads with the dual 10 core. I would suggest trying to run that same benchmark again but do it at the same time from multiple client machines. See if the bench takes a larger dip when a second client machine runs the same bench or if the bench shows similar figures(granted this might hit hd io limit on the power8 server).
So yea, that and try SMT-2 and SMT-4 modes.
JohanAnandtech - Friday, September 16, 2016 - link
Hi, I tried SMT-4, throughput was about 25% worse: 11k instead 14k+. 95th perc response time was better: 3.7 ms.JohanAnandtech - Friday, September 16, 2016 - link
updated the MySQL graphs with SMT-4 data. Our Spark tests gets worse with SMT-4 and that is also true for SPECjbb.luminarian - Friday, September 16, 2016 - link
Awesome, Thanks for the response.Meteor2 - Friday, September 16, 2016 - link
The HPC potential is awesome. You can really see why Oak Ridge chose POWER9 and Volta.Communism - Sunday, September 18, 2016 - link
Pretty sure most of the reason for that is due to Intel blocking every attempt Nvidia makes at getting a high bandwidth interface bolted onto a Xeon.Given that one of the main reasons that Intel blocked Nvidia's chipset business way back in the day was to try to limit the ability of other companies bolting on high bandwidth accelerators onto Intel chips (Presumably to protect their own initiatives in that space).
Klimax - Saturday, September 17, 2016 - link
Not terribly impressive. You have to get SW to paly nice and spend time to fine tune it to outperform Intel and it will cost you in power and cooling. More like "yes, if you get quite bigger TDP you get bit more power". And it won't be terribly good in many cases. (Like public facing service where latency is critical)Maybe if you are in USA and can waste admins and devs time and waste a lot on cooling and electricity then maybe. Otherwise why bother...
SarahKerrigan - Sunday, September 18, 2016 - link
I don't see this as a bad result. This is a 22nm processor, over two years old, and it beats Haswell-EP (which is newer) on efficiency. Broadwell-EP is brand new, and P9 should come out well before the end of BDW-EP's lifecycle.Kevin G - Sunday, September 18, 2016 - link
Some of the POWER9 chips will be out next year though is suspect that the scale-up models maybe an early 2018 part. Considering that those chips go into IBM's big iron Unix servers, they tend to launch a bit later than the low end models so it isn't game changing.The real question is when SkyLake-EP/EX will launch and in comparison to the scale-out POWER9 chips. I was expecting a first half of 2017 for the Intel parts but I have no reference as to when to expect the POWER9 SO chips. Thus there is a chance Intel can come out first.
Intel also wants a quick transition to SkyLake-EP/EX as they unify those to lines to some extent and provide some major platform improvements. I'm thinking Broadwell-EP/EX will have a relatively short life span compared to Haswell-EP/EX. This mimics much of what happened on the desktop and the challenge to move to 14 nm.