Assessing IBM's POWER8, Part 2: Server Applications on OpenPOWER
by Johan De Gelas on September 15, 2016 8:01 AM ESTSpark Benchmarking
Spark is wonderful framework, but you need some decent input data and some good coding skills to really test it. Speeding up Big Data applications is the top priority project at the lab I work for (Sizing Servers Lab of the University College of West-Flanders), so I was able to turn to the coding skills of Wannes De Smet to produce a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
We tested with Apache Spark 1.5 in standalone mode (non-clustered) as it took us a long time to make sure that the results were repetitive. For now, we keep version 1.5 to be able to compare with earlier results.
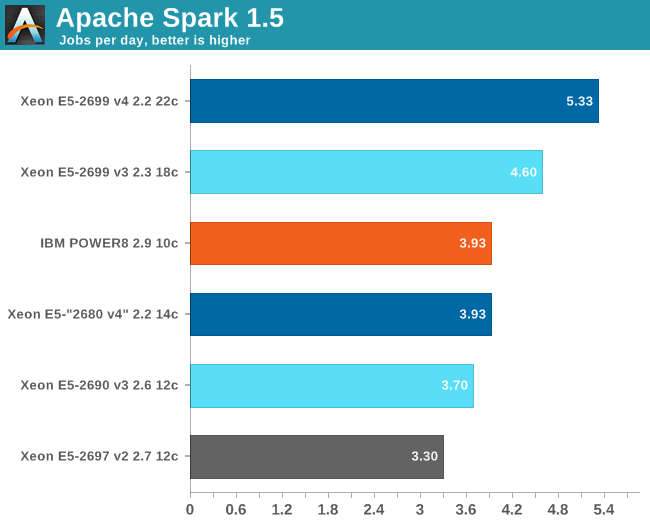
The POWER8 surprises here with excellent performance: it is able to keep with a 14 core Xeon E5 "Broadwell EP" and beats the midrange Xeon E5-2690 v3 by healthy margin. Remember, this is a midrange POWER8: there are SKUs that reach 3.4-3.8 GHz.








49 Comments
View All Comments
PowerOfFacts - Friday, September 16, 2016 - link
trollBOMBOVA - Friday, October 7, 2016 - link
Rich info , good scoutPowerOfFacts - Friday, September 16, 2016 - link
Sigh ....PowerOfFacts - Friday, September 16, 2016 - link
That's strange, this site says you can buy a POWER8 server for $4800. https://www.ibm.com/marketplace/cloud/big-data-inf...Screwed up Power (so many times)? Please explain? Compared to what....SPARC? Itanium? If you are talking about those platforms, POWER has 70% of that marketshare. Do you mean against "Good Enough" Intel? Absolutely Intel is the market leader but only in share as it isn't in innovation. Power still delivers enterprise features for AIX and IBM i customers with features Intel could only dream about. Where the future of the data center is going with Linux, well it did take IBM a while to figure out they couldn't do it their way. Now, they are committed 100% (from my perspective as a non-IBMer while also being committed to AIX & IBM i as their is a solid install base there) which we all see in the form of IBM & even non-IBM solutions built by OpenPOWER partners and ISV solutions using little endian Linux. Yes, there are some workloads that require extra work to optimize but for those already optimized or those which can be optimized, those customers can now buy a server for less money that has the potential to outperform Intel by up to 2X, in a system using innovative technology (CAPI & NVLink) that is more reliable. I don't know, IBM may be late and Power has some work to do but I really don't think you can back up your statement that "IBM has screwed up power so many times". Latest OpenPOWER Summit was a huge success. Here is a Google interview https://www.youtube.com/watch?v=f0qTLlvUB-s&fe...
Oh, but you were probably just trying to be clever and take a few competitive shots.
CajunArson - Saturday, September 17, 2016 - link
Yeah, that $4800 Power server wasn't nearly equivalent to what was benchmarked in this review with the "midrange" server that costs over $11K on the same web page you cited.I could build an 8 or 12 core Xeon that would put the hurt on that low-end Power box for less money and continue to save money during every minute of operation.
JohanAnandtech - Saturday, September 17, 2016 - link
" it will cost anywhere from 5-10X" . What do you base this on? Several SKUs of IBM are in the $1500 range. "Something like $10K for the processor". This seems to be about the high-end. The E7s are in the $4.6-7k range. Even if IBM would charge $10k for the high end CPUs, it is nowhere near being 5x more expensive. Unless I am missing something, you seem to have missed that IBM has a scale out range and is offering much more affordable OpenPOWER CPUs.jesperfrimann - Wednesday, September 21, 2016 - link
IMHO, the place where POWER servers make sense right now, is for use with IBM software. So if you are using something DB2 or WebSphere, where the real cost is the Software licenses.Then it's really a Nobrainer. Not that your local IBM sales Guy will like that you'll do a switch to a Linux@Power solution :)
// Jesper
YukaKun - Thursday, September 15, 2016 - link
For the Java tests, did you change the GC collector settings? Also, why only 24GB for the JVM? I run JBoss with 32GB across our servers. I'd use more, but they still have issues with going to higher levels.Cheers!
madwolfa - Thursday, September 15, 2016 - link
Unless working with huge datasets you want to keep your JVM heap size as reasonably low as possible... otherwise there would be a penalty on GC performance. Granted, with this sort of hardware it would be pretty minuscule, but the general rule of thumb still applies...JohanAnandtech - Thursday, September 15, 2016 - link
No changes to the GC Collector settings. 24 GB for VM = 4x 24 GB + 4x 3 GB for Transaction Injector and 2 GB for the controllor = +/- 110 GB memory. We wanted to run it inside 128 GB as most of our DIMMs are 16 GB at DDR4-2400/2133.