Ten Year Anniversary of Core 2 Duo and Conroe: Moore’s Law is Dead, Long Live Moore’s Law
by Ian Cutress on July 27, 2016 10:30 AM EST- Posted in
- CPUs
- Intel
- Core 2 Duo
- Conroe
- ITRS
- Nostalgia
- Time To Upgrade
Core: Decoding, and Two Goes Into One
The role of the decoder is to decipher the incoming instruction (opcode, addresses), and translate the 1-15 byte variable length instruction into a fixed-length RISC-like instruction that is easier to schedule and execute: a micro-op. The Core microarchitecture has four decoders – three simple and one complex. The simple decoder can translate instructions into single micro-ops, while the complex decoder can convert one instruction into four micro-ops (and long instructions are handled by a microcode sequencer). It’s worth noting that simple decoders are lower power and have a smaller die area to consider compared to complex decoders. This style of pre-fetch and decode occurs in all modern x86 designs, and by comparison AMD’s K8 design has three complex decoders.
The Core design came with two techniques to assist this part of the core. The first is macro-op fusion. When two common x86 instructions (or macro-ops) can be decoded together, they can be combined to increase throughput, and allows one micro-op to hold two instructions. The grand scheme of this is that four decoders can decode five instructions in one cycle.
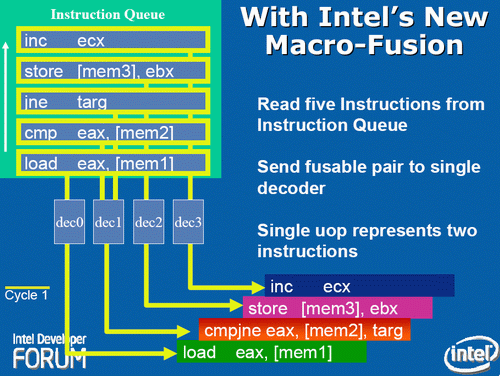
According to Intel at the time, for a typical x86 program, 20% of macro-ops can be fused in this way. Now that two instructions are held in one micro-op, further down the pipe this means there is more decode bandwidth for other instructions and less space taken in various buffers and the Out of Order (OoO) queue. Adjusting the pipeline such that 1-in-10 instructions are fused with another instruction should account for an 11% uptick in performance for Core. It’s worth noting that macro-op fusion (and macro-op caches) has become an integral part of Intel’s microarchitecture (and other x86 microarchitectures) as a result.
The second technique is a specific fusion of instructions related to memory addresses rather than registers. An instruction that requires an addition of a register to a memory address, according to RISC rules, would typically require three micro-ops:
| Pseudo-code | Instructions |
| read contents of memory to register2 | MOV EBX, [mem] |
| add register1 to register2 | ADD EBX, EAX |
| store result of register2 back to memory | MOV [mem], EBX |
However, since Banias (after Yonah) and subsequently in Core, the first two of these micro-ops can be fused. This is called micro-op fusion. The pre-decode stage recognizes that these macro-ops can be kept together by using smarter but larger circuitry without lowering the clock frequency. Again, op fusion helps in more ways than one – more throughput, less pressure on buffers, higher efficiency and better performance. Alongside this simple example of memory address addition, micro-op fusion can play heavily in SSE/SSE2 operations as well. This is primarily where Core had an advantage over AMD’s K8.
AMD’s definitions of macro-ops and micro-ops differ to that of Intel, which makes it a little confusing when comparing the two:
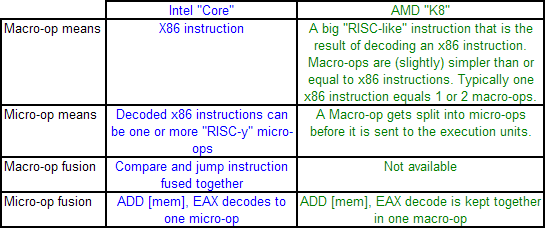
However, as mentioned above, AMD’s K8 has three complex decoders compared to Core’s 3 simple + 1 complex decoder arrangement. We also mentioned that simple decoders are smaller, use less power, and spit out one Intel micro-op per incoming variable length instruction. AMD K8 decoders on the other hand are dual purpose: it can implement Direct Path decoding, which is kind of like Intel’s simple decoder, or Vector decoding, which is kind of like Intel’s complex decoder. In almost all circumstances, the Direct Path is preferred as it produces fewer ops, and it turns out most instructions go down the Direct Path anyway, including floating point and SSE instructions in K8, resulting in fewer instructions over K7.
While extremely powerful in what they do, AMD’s limitation for K8, compared to Intel’s Core, is two-fold. AMD cannot perform Intel’s version of macro-op fusion, and so where Intel can pack one fused instruction to increase decode throughput such as the load and execute operations in SSE, AMD has to rely on two instructions. The next factor is that by virtue of having more decoders (4 vs 3), Intel can decode more per cycle, which expands with macro-op fusion – where Intel can decode five instructions per cycle, AMD is limited to just three.
As Johan pointed out in the original article, this makes it hard for AMD’s K8 to have had an advantage here. It would require three instructions to be fetched for the complex decoder on Intel, but not kick in the microcode sequencer. Since the most frequent x86 instructions map to one Intel micro-op, this situation is pretty unlikely.








158 Comments
View All Comments
pixelstuff - Wednesday, July 27, 2016 - link
I think Core2 essentially accelerated the market saturation we are seeing and causing the PC market to decline a bit. My Core2 E8400 still runs Window 10 relatively fine, although I have built two more since because I like being near the cutting edge. However I know quite a few people still using Core2 CPUs for their basic computing needs.There just haven't been any new apps that are more resource intensive than a word processor or web browser which the entire world needs. So the PC replacement market has stagnated a bit.
stardude82 - Wednesday, July 27, 2016 - link
Most Core processors are faster than the ho-hum Cherry Trail offerings you find low end PCs. So buying a new cute shiny black little box to replace your beige big box doesn't guarantee much.boeush - Wednesday, July 27, 2016 - link
It reads a little weird/myopic that only certain technologies are being considered while forecasting all the way out to 2030. For instance, lots of NAND/DRAM discussion but no mention of upcoming or already early-adoption tech like 3D XPoint or memristors, etc. No mention of optoelectronics (like photonic signalling on- and off-chip), no mention of III-V and other 'exotic' materials for chip manufacturing and improved frequency/power scaling (with focus instead devoted to feature sizes/stacking/platter size/defects.) And so on.I mean, if you're forecasting 5 years ahead, I'd understand. But talking about 15 years into the future but only extrapolating from what's on the market right now -- as opposed to what's in the labs and on drawing boards -- seems to be a little too pessimistic and/or myopic.
Ian Cutress - Wednesday, July 27, 2016 - link
The full report mentions III-V and SiGe in the remit of future technologies. Anton and I are starting to discuss what parts we can pull out for individual news stories, to stay tuned.Sam Snead - Wednesday, July 27, 2016 - link
Heck I still have my Nexgen P110 cpu computer set up and run it once in awhile. From 1996. Remember the VESA local bus video card? Nexgen was later bought by AMD.stardude82 - Wednesday, July 27, 2016 - link
Ah, I remember Socket 7...CoreLogicCom - Wednesday, July 27, 2016 - link
I've still got a Dell E1705 laptop that I bought in 2006 which came with a Core Duo, which I upgraded to Core 2 Duo about 4 years into it, and maxed the RAM to 4GB (from the 2GB max it came with). It was decent, but really came alive when I put an SSD into it. I still use this laptop for basic stuff, and even some gaming (WoW and SWToR) with the Geforce Go GPU. It's definitely long in the tooth now, now running Windows 7 (it came with WinXP, but 10 is unsupported on the GPU even though there's a work around). I'm thinking mobile Kaby Lake and mobile Pascal will be the next laptop I keep for another 10 years.Nacho - Wednesday, July 27, 2016 - link
Can you beat me?Last month I finally upgraded my primary rig from a C2D E4300 @2.7Ghz! Memory started failing last year & I couldn't find cheap DDR2, so I was down to 2GB.
Went for a i5 6500 and 16GB DDR4. The difference is incredible!
Filiprino - Wednesday, July 27, 2016 - link
So much time since reading Anand's article on Conroe.3ogdy - Wednesday, July 27, 2016 - link
Great article, Ian! I've found it a very good read and it's always nice to take a look back and analyze what we've been through so far.I also wanna point out just a few mini-errors I've found in the article:
The Core 2 processors all came from a 143mm2 die, compared TO the 162mm2 of Pentium D. /
by comparison to the large die sizes we see IN 2016 for things like the P100 /
whereas the popular Core 2 Duo E6400 at $224 WAS at the same price as the Core i5-6600.
As we NOW know, on-die IMCs are the big thing.
Geometrical Scaling when this could NO longer operate
By 2020-25 device features will be REDUCED (?)
On the later -> LATTER?
Keep up the amazing work!