Ten Year Anniversary of Core 2 Duo and Conroe: Moore’s Law is Dead, Long Live Moore’s Law
by Ian Cutress on July 27, 2016 10:30 AM EST- Posted in
- CPUs
- Intel
- Core 2 Duo
- Conroe
- ITRS
- Nostalgia
- Time To Upgrade
Core: Decoding, and Two Goes Into One
The role of the decoder is to decipher the incoming instruction (opcode, addresses), and translate the 1-15 byte variable length instruction into a fixed-length RISC-like instruction that is easier to schedule and execute: a micro-op. The Core microarchitecture has four decoders – three simple and one complex. The simple decoder can translate instructions into single micro-ops, while the complex decoder can convert one instruction into four micro-ops (and long instructions are handled by a microcode sequencer). It’s worth noting that simple decoders are lower power and have a smaller die area to consider compared to complex decoders. This style of pre-fetch and decode occurs in all modern x86 designs, and by comparison AMD’s K8 design has three complex decoders.
The Core design came with two techniques to assist this part of the core. The first is macro-op fusion. When two common x86 instructions (or macro-ops) can be decoded together, they can be combined to increase throughput, and allows one micro-op to hold two instructions. The grand scheme of this is that four decoders can decode five instructions in one cycle.
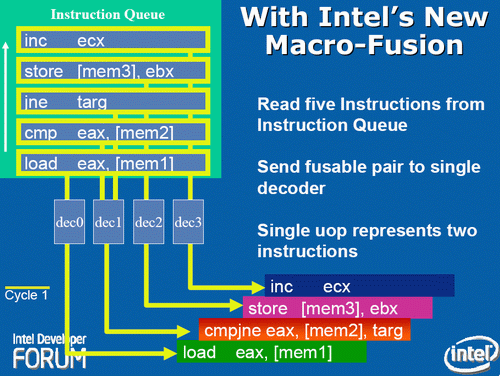
According to Intel at the time, for a typical x86 program, 20% of macro-ops can be fused in this way. Now that two instructions are held in one micro-op, further down the pipe this means there is more decode bandwidth for other instructions and less space taken in various buffers and the Out of Order (OoO) queue. Adjusting the pipeline such that 1-in-10 instructions are fused with another instruction should account for an 11% uptick in performance for Core. It’s worth noting that macro-op fusion (and macro-op caches) has become an integral part of Intel’s microarchitecture (and other x86 microarchitectures) as a result.
The second technique is a specific fusion of instructions related to memory addresses rather than registers. An instruction that requires an addition of a register to a memory address, according to RISC rules, would typically require three micro-ops:
| Pseudo-code | Instructions |
| read contents of memory to register2 | MOV EBX, [mem] |
| add register1 to register2 | ADD EBX, EAX |
| store result of register2 back to memory | MOV [mem], EBX |
However, since Banias (after Yonah) and subsequently in Core, the first two of these micro-ops can be fused. This is called micro-op fusion. The pre-decode stage recognizes that these macro-ops can be kept together by using smarter but larger circuitry without lowering the clock frequency. Again, op fusion helps in more ways than one – more throughput, less pressure on buffers, higher efficiency and better performance. Alongside this simple example of memory address addition, micro-op fusion can play heavily in SSE/SSE2 operations as well. This is primarily where Core had an advantage over AMD’s K8.
AMD’s definitions of macro-ops and micro-ops differ to that of Intel, which makes it a little confusing when comparing the two:
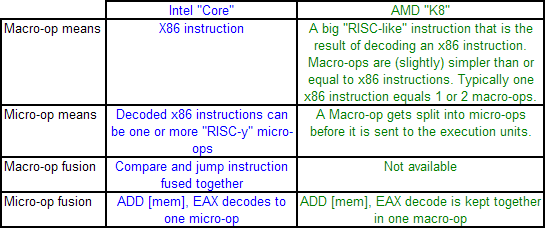
However, as mentioned above, AMD’s K8 has three complex decoders compared to Core’s 3 simple + 1 complex decoder arrangement. We also mentioned that simple decoders are smaller, use less power, and spit out one Intel micro-op per incoming variable length instruction. AMD K8 decoders on the other hand are dual purpose: it can implement Direct Path decoding, which is kind of like Intel’s simple decoder, or Vector decoding, which is kind of like Intel’s complex decoder. In almost all circumstances, the Direct Path is preferred as it produces fewer ops, and it turns out most instructions go down the Direct Path anyway, including floating point and SSE instructions in K8, resulting in fewer instructions over K7.
While extremely powerful in what they do, AMD’s limitation for K8, compared to Intel’s Core, is two-fold. AMD cannot perform Intel’s version of macro-op fusion, and so where Intel can pack one fused instruction to increase decode throughput such as the load and execute operations in SSE, AMD has to rely on two instructions. The next factor is that by virtue of having more decoders (4 vs 3), Intel can decode more per cycle, which expands with macro-op fusion – where Intel can decode five instructions per cycle, AMD is limited to just three.
As Johan pointed out in the original article, this makes it hard for AMD’s K8 to have had an advantage here. It would require three instructions to be fetched for the complex decoder on Intel, but not kick in the microcode sequencer. Since the most frequent x86 instructions map to one Intel micro-op, this situation is pretty unlikely.








158 Comments
View All Comments
patel21 - Thursday, July 28, 2016 - link
Me Q6600 ;-)nathanddrews - Thursday, July 28, 2016 - link
Me too! Great chip!Notmyusualid - Thursday, July 28, 2016 - link
Had my G0 stepping just as soon as it dropped.Coming from a high freq Netburst, I was thrown back, by the difference.
Since then I've bought Xtreme version processors... Until now, its been money well spent.
KLC - Thursday, July 28, 2016 - link
Me too.rarson - Thursday, August 4, 2016 - link
I built my current PC back in 2007 using a Pentium Dual Core E2160 (the $65 bang for the buck king), which easily overclocked to 3 GHz, in an Abit IP35 Pro. Several years ago I replaced the Pentium with a C2D E8600. I'm still using it today. (I had the Q9550 in there for a while, but the Abit board was extremely finnicky with it and I found that the E8600 was a much better overclocker.)paffinity - Wednesday, July 27, 2016 - link
Merom architecture was good architecture.CajunArson - Wednesday, July 27, 2016 - link
To quote Gross Pointe Blank: Ten years man!! TEN YEARS!guidryp - Wednesday, July 27, 2016 - link
Too bad you didn't test something with a bit more clock speed.So you have ~2GHz vs ~4GHz and it's half as fast on single threaded...
Ranger1065 - Wednesday, July 27, 2016 - link
I owned the E6600 and my Q6600 system from around 2008 is still running. Thanks for an interesting and nostalgic read :)Beany2013 - Wednesday, July 27, 2016 - link
Built a Q6600 rig for a mate just as they were going EOL and were getting cheap. It's still trucking, although I suspect the memory bus is getting flaky. Time for a rebuild, methinks.And a monster NAS to store the likely hundreds of thousands of photos she's processed on it and which are stuck around on multiple USB HDDs in her basement.
It's not just CPUs that have moved on - who'd have thought ten years ago that a *good* four bay NAS that can do virtualisation would be a thing you could get for under £350/$500 (QNAP TS451) without disks? Hell, you could barely build even a budget desktop machine (just the tower, no monitor etc) for that back then.
God I feel old.