Assessing IBM's POWER8, Part 1: A Low Level Look at Little Endian
by Johan De Gelas on July 21, 2016 8:45 AM ESTMemory Subsystem: Bandwidth
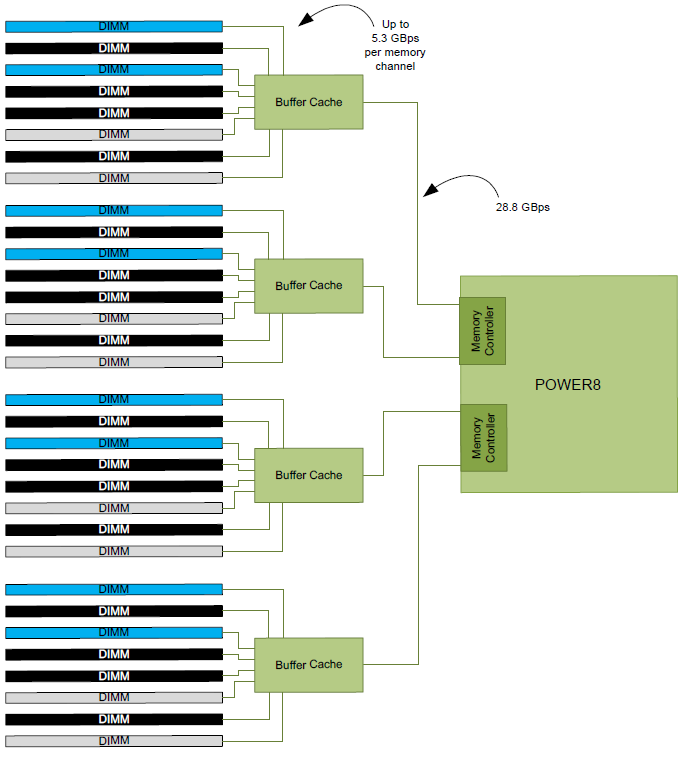
As we mentioned before, the IBM POWER8 has a memory subsystem which is more similar to the Xeon E7's than the E5's. The IBM POWER8 connects to 4 "Centaur" buffer cache chips, which have both a 19.2 GB/s read and 9.6 GB/s write link to the processor, or 28.8 GB/s in total. So the 105 GB/s aggregate bandwidth of the POWER8 is not comparable to Intel's peak bandwidth. Intel's peak bandwidth is the result of 4 channels of DDR4-2400 that can either write or read at 76.8 GB/s (2.4 GHz x 8 bytes per channel x 4 channels).
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2.1 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array sizes which are not cacheable by the Xeons' huge L3 caches.
It is important to note why we use the GCC compiler and not vendors' specialized compilers: the GCC compiler is not as good at vectorizing the code. Intel's ICC compiler does that very well, and as result shows the bandwidth available to highly optimized HPC code, which is great for that code in the real world, but it's not realistic for multi-threaded server applications.
With ICC, Intel can use the very wide 256-bit load units to their full potential and we measured up to 65 GB/s per socket. But you also have to consider that ICC is not free, and GCC is much easier to integrate and automate into the daily operations of any developer. No licensing headaches, no time consuming registrations.
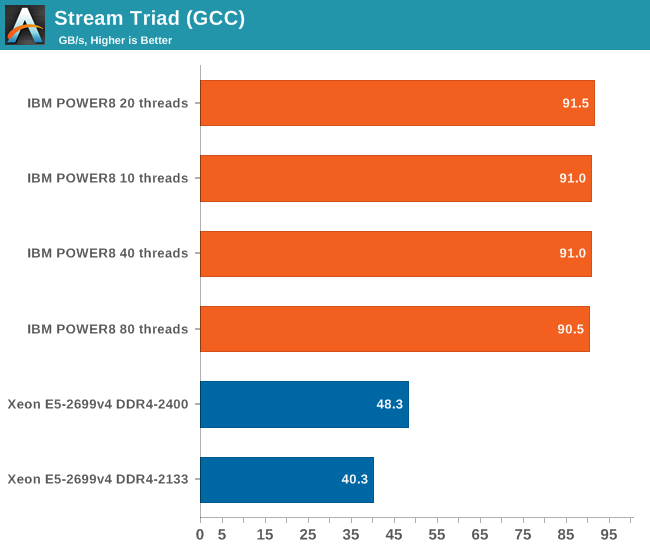
The combination of the powerful four load and two store subsystem of the POWER8 and the read/write interconnect between the CPU and the Centaur chips makes it much easier to offer more bandwidth. The IBM POWER8 delivers a solid 90 GB/s despite using old DDR3-1333 memory technology.
Intel claims higher bandwidth numbers, but those numbers can only be delivered in vectorized software.








124 Comments
View All Comments
abufrejoval - Thursday, August 4, 2016 - link
I believe "heavily threaded" is somewhat imprecise here: Knights Landing (KNL) is really more about vectorized workloads, or one very loopy and computationally expensive problem, which has been partitioned into lots of chunks, but has high locality. Same code, related data, far more computational throughput than data flowthrough.Power8 will do better on such workloads than perhaps Intel, but never as good as a GPU or KNL.
However it does evidently better per core on highly threaded workloads, where lots of execution threads share the same code but distinct or less related datasets, less scientific and more commercial workloads, more data flowing through.
Funnily KNL might even do well there, beating its Xeon-D sibling in every benchmark, even in terms of energy efficience.
But I'm afraid that's because most of the KNL surface area would remain dark on such workload while the invests would burn through any budget.
KNL is an odd beast designed for a rather specific job and only earn its money there, even if you can run Minecraft or Office on it.
Kevin G - Friday, July 22, 2016 - link
I do think comparison with Xeon Phi is fair since it can run/boot itself now with Knight's Landing. Software parity with the normal x86 ecosystem is now there so it can run off the shelf binaries.I am very curious how well such a dense number of cores perform for workloads that don't need high single threaded performance.
Another interest factor would be memory bandwidth performance as Xeon Phi has plenty. The HMC only further enhances that metric and worth exploring it as both a cache and main memory region for benchmarks.
Ratman6161 - Thursday, July 21, 2016 - link
Will you be addressing virtualization in a future article. I ask this because you are saying the lower cost Power8 systems are intended to compete with the Dell's, HP's, Lenovo etc x86 servers. But these days, a very high percentage of x86 work loads are virutalized either on VMWare or competing products. In 2009 Gartner had it at about 50% and by 2014 it was at 70%. I didn't find a number for '15 or '16 but I expect the percentage would have continued to rise. So if they want to take the place of x86 boxes, they have to be able to do the tasks those boxes do...which tends to largely be to run virtual machines that do the actual workloads.And, what about all the x86 boxes running Windows Server or more commonly Windows Server Virtual machines? Windows Server shops aren't likely to ditch windows in favor of Linux solely for the privilege of running on Power8?
One last thing to consider regarding price. These days we can buy quite robust Intel based server for around $10K. So, supposing I can buy a Power8 system for about the same price? Essentially the hardware has gotten so cheap compared to the licensing and support costs for the software we are running that its a drop in the bucket. If we needed 10 Intel servers or 6 Power 8's to do the same job (assuming the Power8's could run all our VM's), the Power8's could come out lower priced hardware wise, but the difference is, as I said, a drop in the bucket in the overall scheme of things. Performance wise, with the x86 boxes, you just throw more cores at it.
aryonoco - Friday, July 22, 2016 - link
KVM works well on POWER.No idea about proprietary things like VMWare. But that would be up to them to port.
Ratman6161 - Friday, July 22, 2016 - link
Near as I can tell, there is a PowerKVM that runs on Power 8 but that doesn't allow you to run Windows Server VM's - seems to support only Linux guests.Zetbo - Saturday, July 23, 2016 - link
Windows does not support POWER, so there is no point of using POWER if you need Windows!utroz - Thursday, July 21, 2016 - link
AMD should have used IBM's 22nm SOI to make cpu's so that they would not have been totally dead in the performance and server cpu market for years. GF now owns this process as they "bought" IBM's fabs and tech. I think that 22nm SOI might be better for high speed cpu's than the 14nm LPP FinFet that AMD is using for ZEN at the cost of die size.amagriva - Thursday, July 21, 2016 - link
How much you payed your cristal ball?spikebike - Thursday, July 21, 2016 - link
So a single socket Power8 is somewhat faster than the intel chip. But is being compared in a single socket configuration where the intel is designed for a two socket. Unless the power8 is cheaper than an intel dual socket seems most fare to compare both CPU as they are designed to be used.SarahKerrigan - Friday, July 22, 2016 - link
Power is designed for systems up to 16 sockets (IBM E880.) One socket is just the entry point.