Assessing IBM's POWER8, Part 1: A Low Level Look at Little Endian
by Johan De Gelas on July 21, 2016 8:45 AM ESTMemory Subsystem: Bandwidth
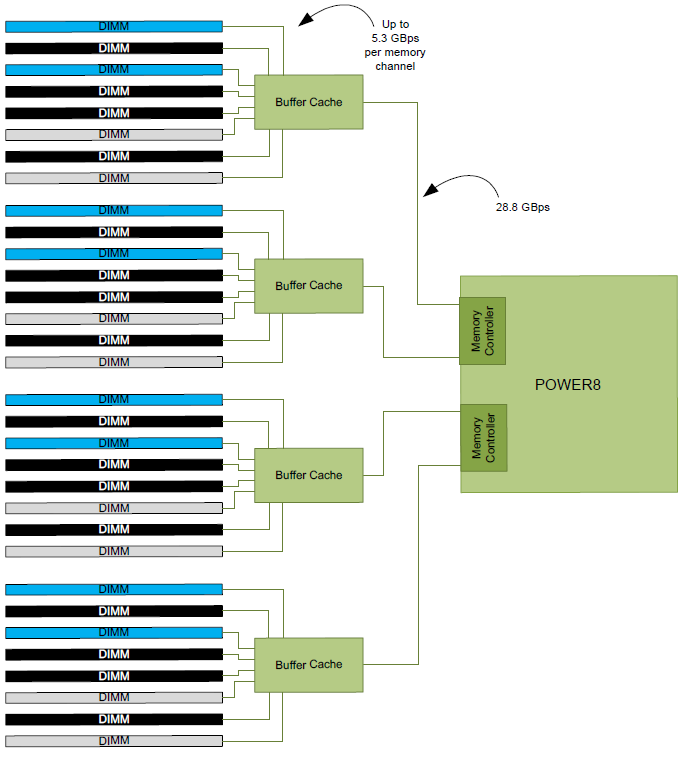
As we mentioned before, the IBM POWER8 has a memory subsystem which is more similar to the Xeon E7's than the E5's. The IBM POWER8 connects to 4 "Centaur" buffer cache chips, which have both a 19.2 GB/s read and 9.6 GB/s write link to the processor, or 28.8 GB/s in total. So the 105 GB/s aggregate bandwidth of the POWER8 is not comparable to Intel's peak bandwidth. Intel's peak bandwidth is the result of 4 channels of DDR4-2400 that can either write or read at 76.8 GB/s (2.4 GHz x 8 bytes per channel x 4 channels).
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2.1 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array sizes which are not cacheable by the Xeons' huge L3 caches.
It is important to note why we use the GCC compiler and not vendors' specialized compilers: the GCC compiler is not as good at vectorizing the code. Intel's ICC compiler does that very well, and as result shows the bandwidth available to highly optimized HPC code, which is great for that code in the real world, but it's not realistic for multi-threaded server applications.
With ICC, Intel can use the very wide 256-bit load units to their full potential and we measured up to 65 GB/s per socket. But you also have to consider that ICC is not free, and GCC is much easier to integrate and automate into the daily operations of any developer. No licensing headaches, no time consuming registrations.
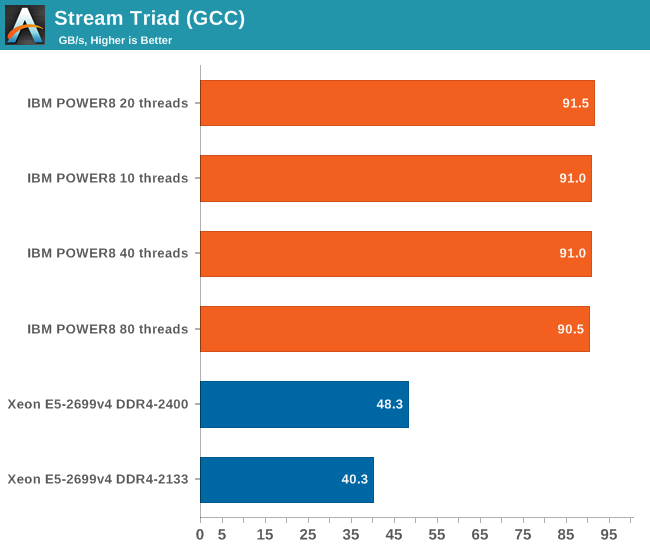
The combination of the powerful four load and two store subsystem of the POWER8 and the read/write interconnect between the CPU and the Centaur chips makes it much easier to offer more bandwidth. The IBM POWER8 delivers a solid 90 GB/s despite using old DDR3-1333 memory technology.
Intel claims higher bandwidth numbers, but those numbers can only be delivered in vectorized software.








124 Comments
View All Comments
JohanAnandtech - Thursday, July 21, 2016 - link
I don't think so, we just expressed it in ns so you can compare with IBM's numbers more easily. Can you elaborate why you think they are wrong?Taracta - Thursday, July 21, 2016 - link
Sorry, mixed up cycles with ns especially after reading the part about transition for the Intel from L3 to MEM.Sahrin - Thursday, July 21, 2016 - link
Yikes. Pictures without captions. Anandtech is terrible about this. ALWAYS caption your pictures, guys.djayjp - Thursday, July 21, 2016 - link
Are bar graphs not a thing anymore...?Drumsticks - Thursday, July 21, 2016 - link
Afaik, Anandtech has always used the chart when presenting things like SPEC. I'd guess it'd be for clutter reasons, but the exact reason is up to the editors to mention.JohanAnandtech - Thursday, July 21, 2016 - link
The reason for me is simply to give you the exact numbers and allow people to do their own comparisons.Drumsticks - Thursday, July 21, 2016 - link
Just to be clear, the Xeon CPU used today is 3 times more expensive than the Power8 CPU benchmarked? That's really impressive, isn't it? The Power8 has a pretty significant power increase, but if it's 43% faster, that cuts into the perf/w gap.I know we've only looked at SPEC so far in round 2, but this looks like a good showing for IBM. How big is the efficiency gap between 22nm SOI and 14nm FinFet? Any estimates?
Michael Bay - Thursday, July 21, 2016 - link
Selling at a loss is hardly impressive, especially in IBM`s case. This thing is literally their last chance.tipoo - Friday, July 22, 2016 - link
Is it at a loss, or is it just not at crazy Intel margins?Michael Bay - Saturday, July 23, 2016 - link
They`d have to have a healthy margin to offset all the R&D, plus IBM as a whole is not in a good financial position. Consider they sold their fab capability not so long ago.