Assessing IBM's POWER8, Part 1: A Low Level Look at Little Endian
by Johan De Gelas on July 21, 2016 8:45 AM ESTMemory Subsystem: Bandwidth
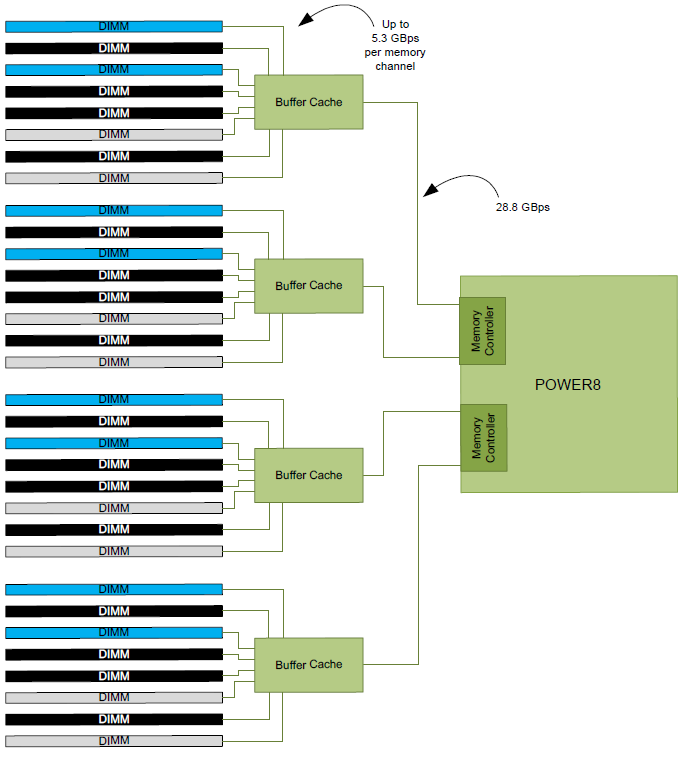
As we mentioned before, the IBM POWER8 has a memory subsystem which is more similar to the Xeon E7's than the E5's. The IBM POWER8 connects to 4 "Centaur" buffer cache chips, which have both a 19.2 GB/s read and 9.6 GB/s write link to the processor, or 28.8 GB/s in total. So the 105 GB/s aggregate bandwidth of the POWER8 is not comparable to Intel's peak bandwidth. Intel's peak bandwidth is the result of 4 channels of DDR4-2400 that can either write or read at 76.8 GB/s (2.4 GHz x 8 bytes per channel x 4 channels).
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2.1 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array sizes which are not cacheable by the Xeons' huge L3 caches.
It is important to note why we use the GCC compiler and not vendors' specialized compilers: the GCC compiler is not as good at vectorizing the code. Intel's ICC compiler does that very well, and as result shows the bandwidth available to highly optimized HPC code, which is great for that code in the real world, but it's not realistic for multi-threaded server applications.
With ICC, Intel can use the very wide 256-bit load units to their full potential and we measured up to 65 GB/s per socket. But you also have to consider that ICC is not free, and GCC is much easier to integrate and automate into the daily operations of any developer. No licensing headaches, no time consuming registrations.
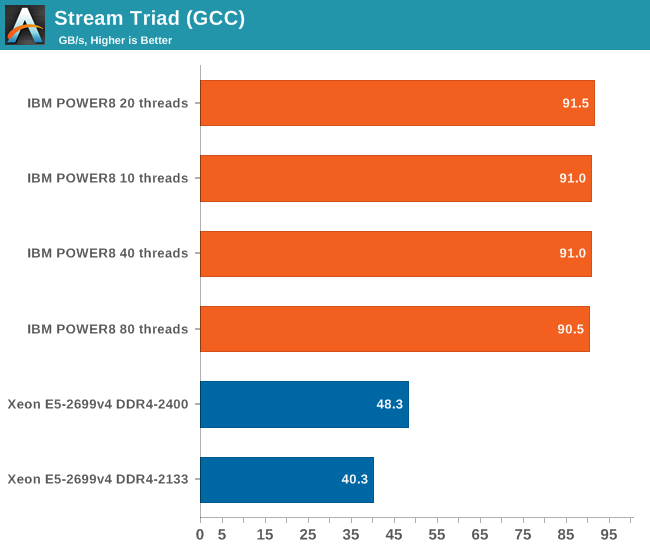
The combination of the powerful four load and two store subsystem of the POWER8 and the read/write interconnect between the CPU and the Centaur chips makes it much easier to offer more bandwidth. The IBM POWER8 delivers a solid 90 GB/s despite using old DDR3-1333 memory technology.
Intel claims higher bandwidth numbers, but those numbers can only be delivered in vectorized software.








124 Comments
View All Comments
JohanAnandtech - Thursday, July 28, 2016 - link
Send me a mail at johan@anandtech.comabufrejoval - Thursday, August 4, 2016 - link
Hmm, a bit fuzzy after the first paragraph or so and evidently because I dislike malwaretizement: Such links should be banned!mystic-pokemon - Friday, July 22, 2016 - link
Hi floobitFor virtualization: powerVM and out of the box KVM (tested on Fedora 23, Ubuntu 15.04 / 15.10 / 16.04) work quite well. Xen doesn't work well or hasn't been officially tested / released.
tipoo - Thursday, July 21, 2016 - link
Fun! I was always curious about this processor.tipoo - Thursday, July 21, 2016 - link
Interesting that the L3 eDRAM not only allows them to pack in much more L3 (what was it, 3 SRAM transistors per eDRAM or something?), but it's also low latency which was a cited concern with eDARM by some people. Appears to be an unfounded fear.And then on top of that they put another large L4 eDRAM cache on.
Maybe Intel needs to play with eDRAM more...
tipoo - Thursday, July 21, 2016 - link
Lol, eDRAM, not eDARMKevin G - Thursday, July 21, 2016 - link
There was a change in how the L4 cache works from Broadwell to SkyLake on the mobile parts. The implication is that Intel was exploring the idea of a large L4 eDRAM for SkyLake-EP/EX parts. We'll see how that turns out as Intel also has explored using HMC as a cache for high bandwidth applications in Knights Landing. So either way, Intel has thus idea on there radar and we'll see how it pans out next year.tsk2k - Thursday, July 21, 2016 - link
Is it possible to run Windows on one of these?ZeDestructor - Thursday, July 21, 2016 - link
At the moment, a very solid no.That said, if enough partners ask for it and/or if the numbers make sense for Azure, MS will at the very least have a damn good look at porting Windows over.
DanNeely - Thursday, July 21, 2016 - link
It's probably just a case of doing QA and releasing it. They've sold a PPC build in the past; and maintain internal builds for a number of other CPU architectures to avoid accidentally baking x86isms into the core code.