Assessing IBM's POWER8, Part 1: A Low Level Look at Little Endian
by Johan De Gelas on July 21, 2016 8:45 AM ESTMemory Subsystem: Bandwidth
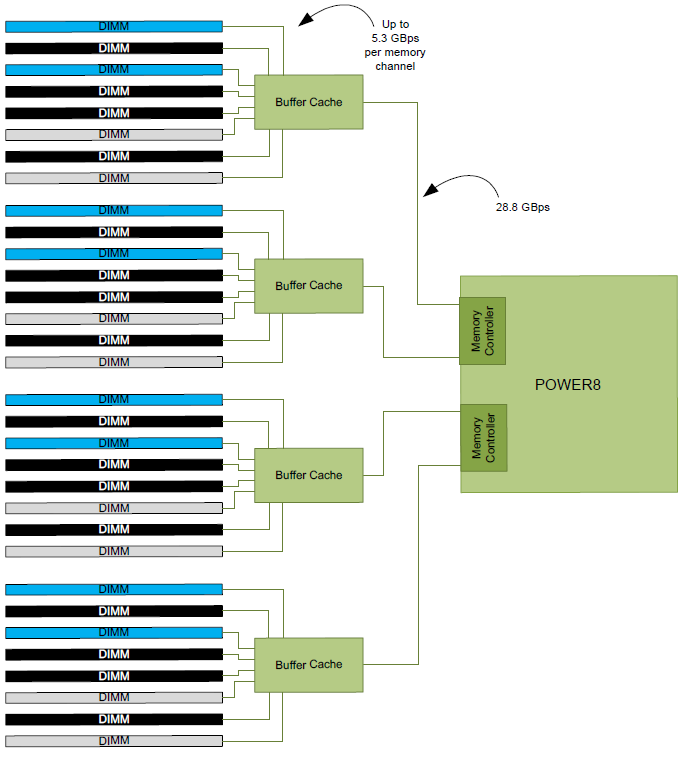
As we mentioned before, the IBM POWER8 has a memory subsystem which is more similar to the Xeon E7's than the E5's. The IBM POWER8 connects to 4 "Centaur" buffer cache chips, which have both a 19.2 GB/s read and 9.6 GB/s write link to the processor, or 28.8 GB/s in total. So the 105 GB/s aggregate bandwidth of the POWER8 is not comparable to Intel's peak bandwidth. Intel's peak bandwidth is the result of 4 channels of DDR4-2400 that can either write or read at 76.8 GB/s (2.4 GHz x 8 bytes per channel x 4 channels).
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2.1 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array sizes which are not cacheable by the Xeons' huge L3 caches.
It is important to note why we use the GCC compiler and not vendors' specialized compilers: the GCC compiler is not as good at vectorizing the code. Intel's ICC compiler does that very well, and as result shows the bandwidth available to highly optimized HPC code, which is great for that code in the real world, but it's not realistic for multi-threaded server applications.
With ICC, Intel can use the very wide 256-bit load units to their full potential and we measured up to 65 GB/s per socket. But you also have to consider that ICC is not free, and GCC is much easier to integrate and automate into the daily operations of any developer. No licensing headaches, no time consuming registrations.
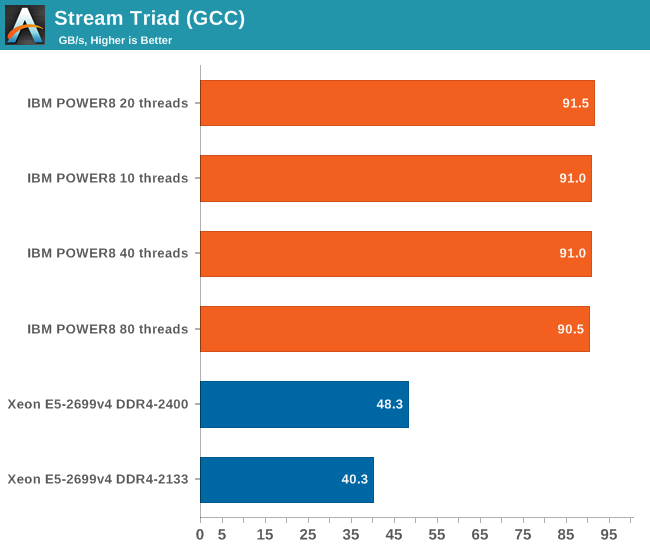
The combination of the powerful four load and two store subsystem of the POWER8 and the read/write interconnect between the CPU and the Centaur chips makes it much easier to offer more bandwidth. The IBM POWER8 delivers a solid 90 GB/s despite using old DDR3-1333 memory technology.
Intel claims higher bandwidth numbers, but those numbers can only be delivered in vectorized software.








124 Comments
View All Comments
DomOfSF - Thursday, July 21, 2016 - link
Johan de Gelas: blowing minds and educating "the rest of us" since...I dunno, a really long time ago (especially in internet years). Great job on the data, but the real good stuff is in your thoughts and analysis. Thank you!close - Saturday, July 23, 2016 - link
Over a decade...JohanAnandtech - Thursday, July 28, 2016 - link
13 years in the server business, 18 years now of reviewing hardware :-). Thx !!jamyryals - Thursday, July 21, 2016 - link
It seems to me, Intel's focus on bringing their CPU architecture design all the way down to 5W is the reason IBM is able to stand out against them. Intel is focused on creating a scalable architecture while IBM can throw the whole kitchen sink at the server market.Fascinating article, I really enjoyed it.
smilingcrow - Thursday, July 21, 2016 - link
Intel has plenty of unique features in their server platforms which aren't in the consumer platforms so I don't think that is the issue.jospoortvliet - Tuesday, July 26, 2016 - link
The basic design of the core still is the same so there is probably at least some truth in the statement of Jamy.Kevin G - Wednesday, July 27, 2016 - link
Up until this point. Consumer SkyLake and server SkyLake are going to be two different designs. They're certainly related but server SkyLake will have 512 KB of L2 cache per core and support AVX-512 instructions.Server SkyLake is also going to support 3D Xpoint DIMMs, though that difference is more with the platform/chipset than the actual CPU core.
floobit - Thursday, July 21, 2016 - link
Very interesting. It seems odd to me that they chose to configure it in a 2U - except for big data clusters, most of the market space I see this playing is dominated by FC to a SAN. Is this a play in the big data cluster space, or the more traditional AIX/DB2/big iron that IBM has owned for so long?Some questions I'd have:
what virtualization is possible with this architecture? presumably just the standard PowerVM? How well does that work?
What is the impact of IO latency? Could you throw a P3700 or two in here?
JohanAnandtech - Thursday, July 21, 2016 - link
2U: Besides big data storage needs, I suspect 2U is necessary for adequate cooling for the POWER8 chip.Virtualization: Linux KVM works well as far as I know.
We actually tried out a P3700 in there (see: http://www.anandtech.com/show/9567/the-power-8-rev... ) and it worked very well. I asked IBM what a customer should expect when using third party storage (probably no support, but how about waranty?) but no answer yet.
mystic-pokemon - Friday, July 22, 2016 - link
Hi Johan2U is not necessary for cooling a POWER 8 Chip. We do that better with our Barreleye (1.25 OU design). Even storage wise Barreleye has 15 Disk storage bay that can be seen in below links.
http://www.v3.co.uk/v3-uk/news/2453992/google-and-...
Let me know if you wanna ever benchmark a Barreleye. What specific POWER8 proc are you benchmarking with ? (Turismo?). I believe it does slightly better than S812LC on many benchmarks based on the variant of power8 proc S812LC runs.