Assessing IBM's POWER8, Part 1: A Low Level Look at Little Endian
by Johan De Gelas on July 21, 2016 8:45 AM ESTMemory Subsystem: Bandwidth
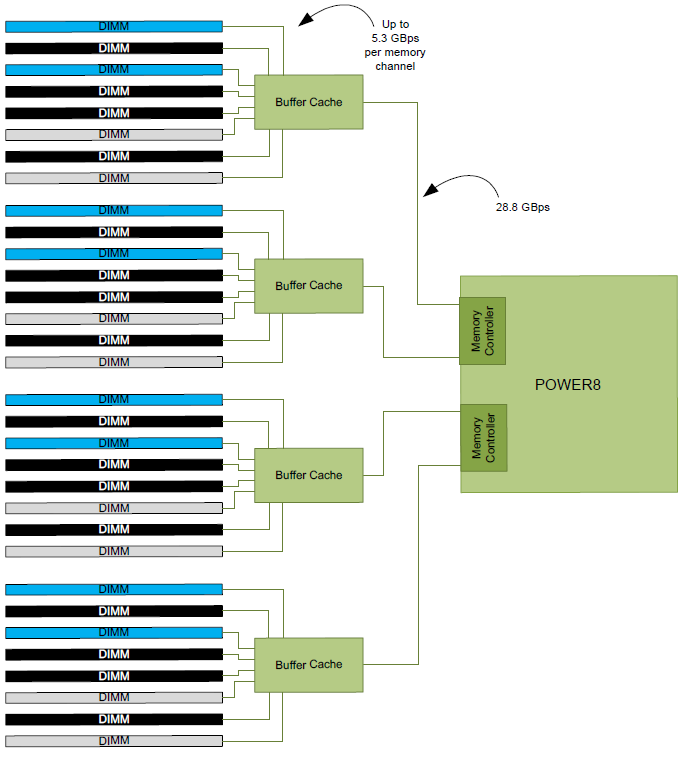
As we mentioned before, the IBM POWER8 has a memory subsystem which is more similar to the Xeon E7's than the E5's. The IBM POWER8 connects to 4 "Centaur" buffer cache chips, which have both a 19.2 GB/s read and 9.6 GB/s write link to the processor, or 28.8 GB/s in total. So the 105 GB/s aggregate bandwidth of the POWER8 is not comparable to Intel's peak bandwidth. Intel's peak bandwidth is the result of 4 channels of DDR4-2400 that can either write or read at 76.8 GB/s (2.4 GHz x 8 bytes per channel x 4 channels).
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2.1 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array sizes which are not cacheable by the Xeons' huge L3 caches.
It is important to note why we use the GCC compiler and not vendors' specialized compilers: the GCC compiler is not as good at vectorizing the code. Intel's ICC compiler does that very well, and as result shows the bandwidth available to highly optimized HPC code, which is great for that code in the real world, but it's not realistic for multi-threaded server applications.
With ICC, Intel can use the very wide 256-bit load units to their full potential and we measured up to 65 GB/s per socket. But you also have to consider that ICC is not free, and GCC is much easier to integrate and automate into the daily operations of any developer. No licensing headaches, no time consuming registrations.
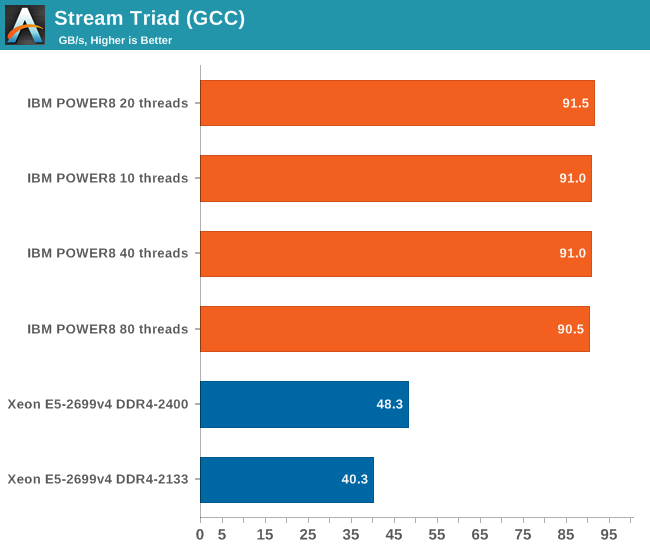
The combination of the powerful four load and two store subsystem of the POWER8 and the read/write interconnect between the CPU and the Centaur chips makes it much easier to offer more bandwidth. The IBM POWER8 delivers a solid 90 GB/s despite using old DDR3-1333 memory technology.
Intel claims higher bandwidth numbers, but those numbers can only be delivered in vectorized software.








124 Comments
View All Comments
jospoortvliet - Tuesday, July 26, 2016 - link
The point Johan makes is that his goal is not to get the best bechmark scores but the most relevant real life data. One can argue if he succeeded, certainly the results are interesting but there is much more to the CPU's as usual. And I do think his choice is justified, while much scientific code would be recompiled with a faster compiler (though the cost of ICC might be a problem in a educational setting), many businesses wouldn't go through that effort.I personally would love to see a newer Ubuntu & GCC being used, just to see what the difference is, if any. The POWER ecosystem seems to evolve fast so a newer platform and compiler could make a tangible difference.
But, of course, if you in your usecase would use ICC or xLC, these benches are not perfect.
Eris_Floralia - Friday, July 22, 2016 - link
Are these two processor both tested at the same frequency?or at their stock clock?tipoo - Friday, July 22, 2016 - link
The latter, page 52.92-3.5 GHz vs 2.2-3.6 GHz
abufrejoval - Thursday, August 4, 2016 - link
Well since Johan really only tested one core on each CPU, it would have been nice to have him verify the actual clock speed of those cores. You'd assume that they'd be able to maintain top speed for any single core workload independent of the number of threads, but checking is better than guessing.roadapathy - Friday, July 22, 2016 - link
22nm? *yawwwwwwwwwn* Come on IBM, you can do better than that, brah.Michael Bay - Saturday, July 23, 2016 - link
Nope, 22 is the best SOI has right now. You have to remember it`s nowhere near standard litographies customer-wise.tipoo - Monday, July 25, 2016 - link
In addition to what Michael Bay (lel) said, remember that only Intel really has 14nm, when TSMC and GloFlo say 14/16nm they really mean 20nm with finfetts.feasibletrash0 - Saturday, July 23, 2016 - link
using a less capable compiler (GCC) to test a chip, and not using everything the chip has to offer seems incredibly flawed to me, what are you testing exactlyaryonoco - Saturday, July 23, 2016 - link
He's testing what actual software people actually run on these things.On your typical Linux host, pretty most everything is compiled with GCC. You want to get into exotic compilers? Sure both IBM and Intel have their exotic proprietary costly compilers, so what. Very few people outside of niche industries use them.
You want to compare a CPU with CPU? You keep the compiler the same. That's just common sense. It's also how the scientific method works!
feasibletrash0 - Sunday, July 24, 2016 - link
right, but you're comparing, say 10% of the silicon on that chip, and saying that the remaining 90% of the transistors making the chip does not matter, they do; if the software is not using them, that's fine, but it's not an accurate comparison of the hardware, it's a comparison of the software