Investigating Cavium's ThunderX: The First ARM Server SoC With Ambition
by Johan De Gelas on June 15, 2016 8:00 AM EST- Posted in
- SoCs
- IT Computing
- Enterprise
- Enterprise CPUs
- Microserver
- Cavium
Memory Subsystem: Bandwidth
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array size which are not cacheable by the Xeon's huge L3-caches nowadays.
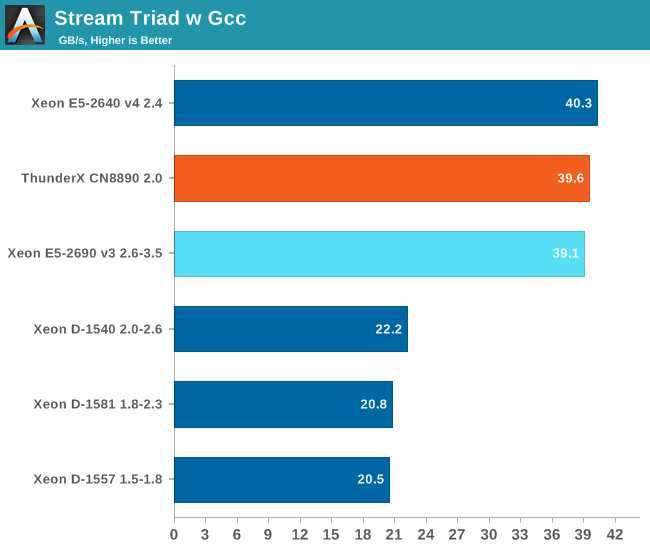
The ThunderX keeps up with the midrange Xeon E5s. The relatively low numbers might surprise a lot of people, as Stream benchmarks now hit 100 GB/s and beyond easily these days. First of all, these are of course single socket measurements, as opposed to the typical dual socket stream tests. Secondly, only the "high-end" and "segment optimized" Intel SKUs support DDR-2400, many SKUs are "limited" to DDR4-2133. With DDR4-2400, Xeon E5's score would increase to 48 GB/s per socket.
Last but not least: we do not use the icc compiler. Using the icc compiler boosts the performance of this benchmark by 33% (to 64 GB/s). That raw bandwidth is most likely only useful in some AVX-optimized HPC applications, a market that the ThunderX does not target. So far, so good: the ThunderX memory controller delivers twice as much bandwidth as Intel's Xeon D SoC. It is the first time the Xeon D gets beaten by an ARM v8 SoC...








82 Comments
View All Comments
BlueBlazer - Friday, June 17, 2016 - link
Cavium is quite aware of their ThunderX single thread weakness, and directly from Cavium themselves https://www.youtube.com/watch?v=ei9uVskwPNE thanks to ARMdevices.net.TiffanyTown - Thursday, July 28, 2016 - link
hi, The JDK version you used is OpenJDK 1.8.0_91 . Did you build it yourself?