Investigating Cavium's ThunderX: The First ARM Server SoC With Ambition
by Johan De Gelas on June 15, 2016 8:00 AM EST- Posted in
- SoCs
- IT Computing
- Enterprise
- Enterprise CPUs
- Microserver
- Cavium
Memory Subsystem: Bandwidth
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array size which are not cacheable by the Xeon's huge L3-caches nowadays.
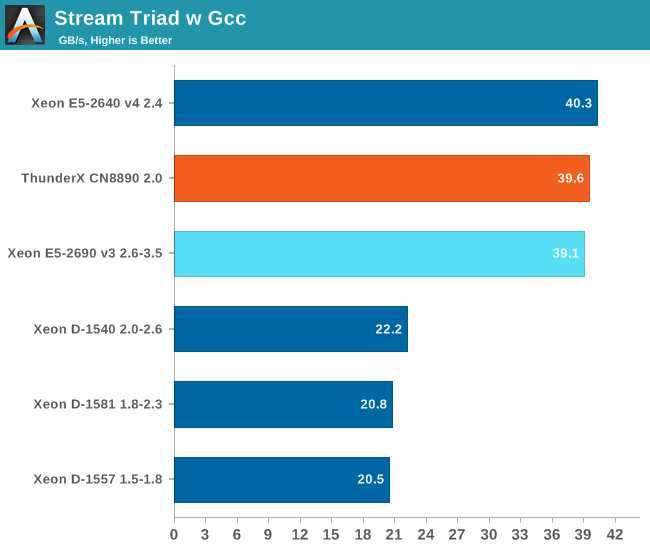
The ThunderX keeps up with the midrange Xeon E5s. The relatively low numbers might surprise a lot of people, as Stream benchmarks now hit 100 GB/s and beyond easily these days. First of all, these are of course single socket measurements, as opposed to the typical dual socket stream tests. Secondly, only the "high-end" and "segment optimized" Intel SKUs support DDR-2400, many SKUs are "limited" to DDR4-2133. With DDR4-2400, Xeon E5's score would increase to 48 GB/s per socket.
Last but not least: we do not use the icc compiler. Using the icc compiler boosts the performance of this benchmark by 33% (to 64 GB/s). That raw bandwidth is most likely only useful in some AVX-optimized HPC applications, a market that the ThunderX does not target. So far, so good: the ThunderX memory controller delivers twice as much bandwidth as Intel's Xeon D SoC. It is the first time the Xeon D gets beaten by an ARM v8 SoC...








82 Comments
View All Comments
silverblue - Thursday, June 16, 2016 - link
I'm not sure how this is relevant. Johan doesn't review graphics cards, other people at Anandtech do. I bet Guru3D has a much bigger team for that, and I imagine that they have a much narrower scope (i.e. no server stuff).I don't think I've looked at a review recently that hasn't had the comments section polluted with "where is the review for x".
UrQuan3 - Wednesday, June 15, 2016 - link
Intel allows their Xeons to sometimes pull double their TDP? No wonder our new machines trip breakers long before I thought they would. I need to test instead of assuming accurate documentation.I can see why you chose C-Ray, I'm just sorry a more general ray tracer was not chosen. Still, not it's intended market, though I am suddenly very interested. Ray-tracing and video encoding are my top two tasks.
Meteor2 - Thursday, June 16, 2016 - link
The 'T' in 'TDP' is for thermal. It's a measure of the maximum waste heat which needs to be removed over a certain period of time.UrQuan3 - Wednesday, June 22, 2016 - link
Yes, it stands for thermal, but power doesn't consumed doesn't just disappear. Convert it to light, convert it to motion, convert it to heat, etc. In this case there is a small amount of motion (electrons) and the rest has to be heat. I expect much higher instantaneous pulls, but this was sustained power. Anyway, I will track down the AVX documentation mentioned below.I saw the h264ref. I'll be curious about x264 (handbrake) as the authors seem interested in ARM in the last few years. Unsurprisingly, it is far less optimized than x64. I benchmarked handbrake on the Pi2, Pandaboard, and CI-20 last year, just to see what it would do.
JohanAnandtech - Thursday, June 16, 2016 - link
C-Ray was just a place holder to measure FPU energy consumption. I look into bringing a more potent raytracer into our benchmark suite (povray)Video encoding was in the review though, somewhat (h264ref).
patrickjp93 - Friday, June 17, 2016 - link
ARM chips with vector extensions allow it as well. Intel provides separate documentation for AVX-workload TDPs.Antony Newman - Wednesday, June 15, 2016 - link
Fascinating article.Why would Cavium not try and use 54 x A73s in their next chip?
If ARM are not in the business of making Silicon, and ARM think the '1.2W Ares' will help them break into the Server market ... Then Why do we think ARM isn't working with the likes of Cavium to get a Server SoC that rocks the Intel boat?
Typos From memory : send -> sent. Through-> thought. There were a few others.
AJ
name99 - Thursday, June 16, 2016 - link
How do you know ARM aren't working with such a vendor?ARM has always said that they expect ARM server CPUs to only be marginally competitive (for very limited situations) in 2017, and to only be really competitive in 2020.
That suggests, among other things, that if they are working with partners, they have a target launch between those two dates, and they regard all launches before 2017 as essentially nice for PR and fr building up the ecosystem, but essentially irrelevant for commercial purposes.
rahvin - Thursday, June 16, 2016 - link
The problem as pointed out early in this article is that ARM keeps targeting Intel's current products, not the ones that will be out when they get their products out. We've had almost a dozen vendors get to the point of releasing the chip and drop it because it is simply not competitive with Intel. Most of these arm products were under taken when Intel was targeting performance without regard to performance/watt. Now that intel targets the later metric arm server chips haven't been competitive with them.Fact is Intel could decimate and totally take over all the markets arm chips occupy, but to do it they'd have to cannibalize their existing high profit sales. This is why they keep canceling Atom chips, the chips turned out so good they were worried they'd cannibalize much more expensive products. This is the reason Avoton is highly restricted in what products and price segments it's allowed into. If Intel opened the flood gates on Avoton they would risk cannibalizing their own server profits.
junky77 - Wednesday, June 15, 2016 - link
So, they did what AMD couldn't for years? I'm trying to figure it out.. their offering seems to be a lot more interesting than AMD's stuff currently