Investigating Cavium's ThunderX: The First ARM Server SoC With Ambition
by Johan De Gelas on June 15, 2016 8:00 AM EST- Posted in
- SoCs
- IT Computing
- Enterprise
- Enterprise CPUs
- Microserver
- Cavium
Memory Subsystem: Bandwidth
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array size which are not cacheable by the Xeon's huge L3-caches nowadays.
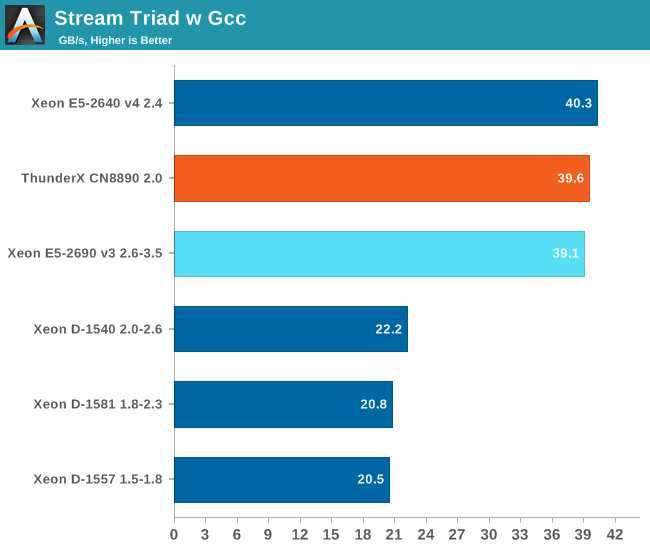
The ThunderX keeps up with the midrange Xeon E5s. The relatively low numbers might surprise a lot of people, as Stream benchmarks now hit 100 GB/s and beyond easily these days. First of all, these are of course single socket measurements, as opposed to the typical dual socket stream tests. Secondly, only the "high-end" and "segment optimized" Intel SKUs support DDR-2400, many SKUs are "limited" to DDR4-2133. With DDR4-2400, Xeon E5's score would increase to 48 GB/s per socket.
Last but not least: we do not use the icc compiler. Using the icc compiler boosts the performance of this benchmark by 33% (to 64 GB/s). That raw bandwidth is most likely only useful in some AVX-optimized HPC applications, a market that the ThunderX does not target. So far, so good: the ThunderX memory controller delivers twice as much bandwidth as Intel's Xeon D SoC. It is the first time the Xeon D gets beaten by an ARM v8 SoC...








82 Comments
View All Comments
willis936 - Thursday, June 16, 2016 - link
Are you sure that the there are more cores at lower clocks to keep voltage lower? Power consumption is proportional to v^2*f.ddriver - Friday, June 17, 2016 - link
Say what? Go back, read my previous post again, and if you are going to respond, make sure it is legible.willis936 - Friday, June 17, 2016 - link
Alright well if you don't understand why many slower cores are more power efficient even if there was a 0 cycle penalty on context switching then you aren't worth having this discussion with.blaktron - Wednesday, June 15, 2016 - link
48 cores of server processing on 16mb of l2 and 4 channels of RAM? What is this thing designed for. Will be like running single channel celerons as server processors, so decent hypervisor hosts are out, and so is any database work more complex than dynamic web pages.Haravikk - Wednesday, June 15, 2016 - link
Facebook is specifically mentioned as being interested in this, so dynamic web-pages is definitely a valid use-case here. HHVM for example is pretty light on memory usage (so is PHP7 now), especially in high demand cases where you're really only running a single set of scripts, probably cached in a compiled form, plus both scale really well across as many cores as you can throw at them.Things like nginx and MariaDB will be the same, so they're absolutely intended use-cases for this kind of chip, and I think it should be very good at it.
blaktron - Wednesday, June 15, 2016 - link
With no L3 and slow RAM access I'm not sure where you think the scrips will cache. Assuming you ran them on bare metal (horrifying waste of compute) there would be enough, but if you had docker instances or quick spin vms doing your work (as 99% of web servers are) then each instance will only get the tiniest slice of cache to work with. It would be like running your servers, as I said, on a bank of celerons. Except celerons have L3 and don't carry 12 cores per memory channel.spaceship9876 - Wednesday, June 15, 2016 - link
Hopefully someone will release a server chip using 64 cortex A73 cpu cores, i'm pretty sure the cortex a73 will be more power efficient than xeon d. Xeon d beats cortex a57 in power efficiency but i'm pretty sure than cortex a72 will be similar and cortex a73 will beat it.Flunk - Wednesday, June 15, 2016 - link
ARM with ambition?I've heard that before, nothing came of it.
CajunArson - Wednesday, June 15, 2016 - link
Interesting article. This does appear to be the first semi-credible part from an ARM server vendor.Having said that, the energy efficiency table at the end should put to rest any misconceived notions that ARM is somehow magically energy efficient while X86 isn't.
Considering that Xeon E5-2690 v3 is a 4.5 year old Sandy Bridge part made on a 32 nm process and it still has better performance-per-watt than the best ARM server parts available in 2016, it's pretty obvious that Intel has done an excellent job with power efficiency.
kgardas - Wednesday, June 15, 2016 - link
2 CajunArson: (1) you can't compare energy efficiency of CPUs made on different nodes. 28nm versus 14nm? This is apple to oranges. (2) Xeon E5-2690 *v3* is Haswell and not Sandy Bridge and it's not 4.5 years definitely.