Investigating Cavium's ThunderX: The First ARM Server SoC With Ambition
by Johan De Gelas on June 15, 2016 8:00 AM EST- Posted in
- SoCs
- IT Computing
- Enterprise
- Enterprise CPUs
- Microserver
- Cavium
Memory Subsystem: Bandwidth
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array size which are not cacheable by the Xeon's huge L3-caches nowadays.
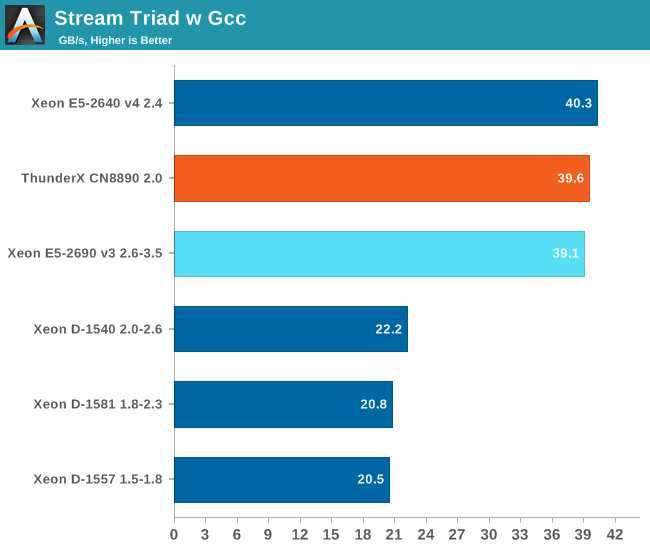
The ThunderX keeps up with the midrange Xeon E5s. The relatively low numbers might surprise a lot of people, as Stream benchmarks now hit 100 GB/s and beyond easily these days. First of all, these are of course single socket measurements, as opposed to the typical dual socket stream tests. Secondly, only the "high-end" and "segment optimized" Intel SKUs support DDR-2400, many SKUs are "limited" to DDR4-2133. With DDR4-2400, Xeon E5's score would increase to 48 GB/s per socket.
Last but not least: we do not use the icc compiler. Using the icc compiler boosts the performance of this benchmark by 33% (to 64 GB/s). That raw bandwidth is most likely only useful in some AVX-optimized HPC applications, a market that the ThunderX does not target. So far, so good: the ThunderX memory controller delivers twice as much bandwidth as Intel's Xeon D SoC. It is the first time the Xeon D gets beaten by an ARM v8 SoC...








82 Comments
View All Comments
vivs26 - Wednesday, June 15, 2016 - link
Not necessarily - (read Amdahl's law of diminishing returns). The performance actually depends on the workload. Having a million cores guarantees nothing in terms of performance unless the workload is parallelizable which in the real world is not as much as we think it could be. I'm curious to see how xeon merged with altera programmable fabric performs than ARM on a server.maxxbot - Wednesday, June 22, 2016 - link
Technically true but every generation that millstone gets a little smaller, the die area and power needed to translate x86 into uops isn't huge and reduces every generation.jardows2 - Wednesday, June 15, 2016 - link
Interesting. Faster in a few workloads where heavy use of multi-thread is important, but significantly slower in more single thread workloads. For server use, you don't always want parallelized tasks. The results are pretty much across the board for all the processors tested: If the ThunderX was slower, it was slower than all the Intel chips. If it were faster, it was faster than all but the highest end Intel Chips. With the price only being slightly lower than the cheapest Intel chip being sold, I don't think this is going to be a Xeon competitor at all, but will take a few niche applications where it can do better.With no significant energy savings, we should be looking forward to the ThunderX2 to see if it will bring this into a better alternative.
ddriver - Wednesday, June 15, 2016 - link
There is hardly a server workload where you don't get better throughput by throwing more cores and servers at it. Servers are NOT about parallelized task, but about concurrent tasks. That's why while desktops are still stuck at 8 cores, server chips come with 20 and more... Server workloads are usually very simple, it is just that there is a lot of them. They are so simple and take so little time it literally makes no sense parallelizing them.jardows2 - Wednesday, June 15, 2016 - link
In the scenario you described, the single-thread performance takes on even more importance, thus highlighting the advantage the Xeon's currently have in most server configurations.niva - Wednesday, June 15, 2016 - link
Not if the Xeon doesn't have enough cores to actually process 40+ singlethreaded tasks con-currently.hechacker1 - Wednesday, June 15, 2016 - link
But kernels and VMWare know how to schedule multiple threads on 1 core if it's not being fully utilized. Single threaded IPC can make up for not having as many cores. See the iPhone SoCs for another example.ddriver - Wednesday, June 15, 2016 - link
Not if you have thousands of concurrent workloads and only like 8 cores. As fast as each core might be, the overhead from workload context switching will eat it up.willis936 - Thursday, June 16, 2016 - link
Yeah if each task is not significantly longer than a context switch. Context switches are very fast, especially with processors with many sets of SMT registers per core.ddriver - Thursday, June 16, 2016 - link
If what you suggest is correct, then intel would not be investing chip TDP in more cores but higher clocks and better single threaded performance. Clearly this is not the case, as they are pushing 20 cores at the fairly modest 2.4 Ghz.