The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTDesigning GP104: Running Up the Clocks
So if GP104’s per-unit throughput is identical to GM204, and the SM count has only been increased from 2048 to 2560 (25%), then what makes GTX 1080 60-70% faster than GTX 980? The answer there is that instead of vastly increasing the number of functional units for GP104 or increasing per-unit throughput, NVIDIA has instead opted to significantly raise the GPU clockspeed. And this in turn goes back to the earlier discussion on TSMC’s 16nm FinFET process.
With every advancement in fab technology, chip designers have been able to increase their clockspeeds thanks to the basic physics at play. However because TSMC’s 16nm node adds FinFETs for the first time, it’s extra special. What’s happening here is a confluence of multiple factors, but at the most basic level the introduction of FinFETs means that the entire voltage/frequency curve gets shifted. The reduced leakage and overall “stronger” FinFET transistors can run at higher clockspeeds at lower voltages, allowing for higher overall clockspeeds at the same (or similar) power consumption. We see this effect to some degree with every node shift, but it’s especially potent when making the shift from planar to FinFET, as has been the case for the jump from 28nm to 16nm.
Given the already significant one-off benefits of such a large jump in the voltage/frequency curve, for Pascal NVIDIA has decided to fully embrace the idea and run up the clocks as much as is reasonably possible. At an architectural level this meant going through the design to identify bottlenecks in the critical paths – logic sections that couldn’t run at as high a frequency as NVIDIA would have liked – and reworking them to operate at higher frequencies. As GPUs typically (and still are) relatively low clocked, there’s not as much of a need to optimize critical paths in this matter, but with NVIDIA’s loftier clockspeed goals for Pascal, this changed things.
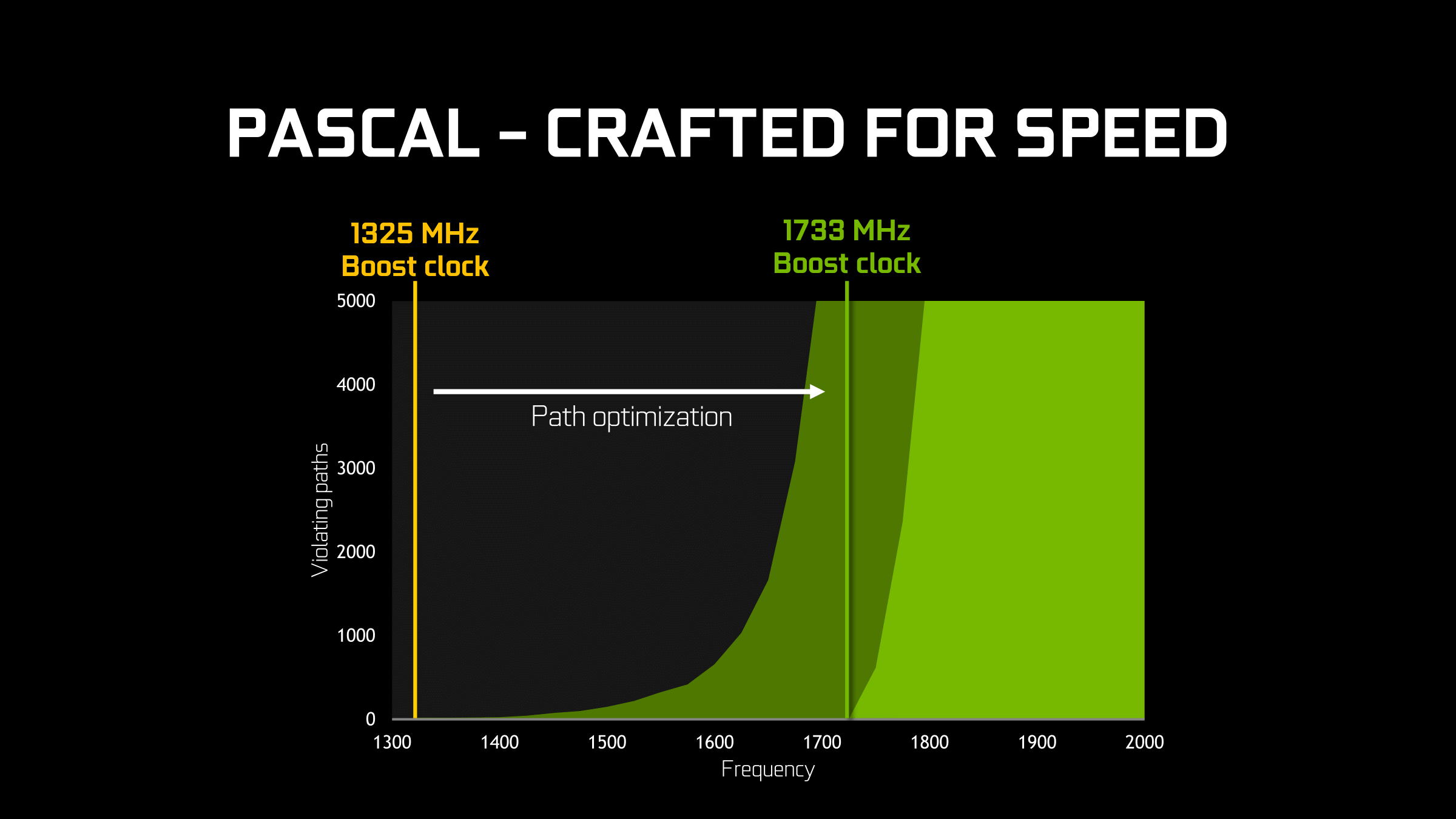
From an implementation point of view this isn’t the first time that NVIDIA has pushed for high clockspeeds, as most recently the 40nm Fermi architecture incorporated a double-pumped shader clock. However this is the first time NVIDIA has attempted something similar since they reined in their power consumption with Kepler (and later Maxwell). Having learned their lesson the hard way with Fermi, I’m told a lot more care went into matters with Pascal in order to avoid the power penalties NVIDIA paid with Fermi, exemplified by things such as only adding flip-flops where truly necessary.
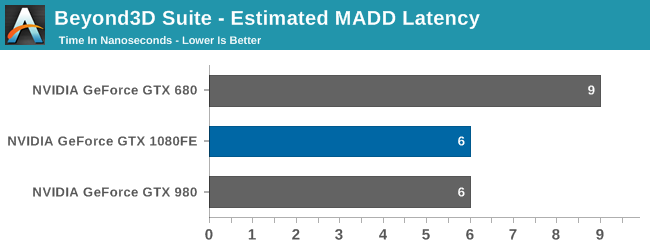
Meanwhile when it comes to the architectural impact of designing for high clockspeeds, the results seem minimal. While NVIDIA does not divulge full information on the pipeline of a CUDA core, all of the testing I’ve run indicates that the latency (in clock cycles) of the CUDA cores is identical to Maxwell. Which goes hand in hand with earlier observations about throughput. So although optimizations were made to the architecture to improve clockspeeds, it doesn’t look like NVIDIA has made any more extreme optimizations (e.g. pipeline lengthening) that detectably reduces Pascal’s per-clock performance.
Finally, more broadly speaking, while this is essentially a one-time trick for NVIDIA, it’s an interesting route for them to go. By cranking up their clockspeeds in this fashion, they avoid any real scale-out issues, at least for the time being. Although graphics are the traditional embarrassingly parallel problem, even a graphical workload is subject to some degree of diminishing returns as GPUs scale farther out. A larger number of SMs is more difficult to fill, not every aspect of the rendering process is massively parallel (shadow maps being a good example), and ever-increasing pixel shader lengths compound the problem. Admittedly NVIDIA’s not seeing significant scale-out issues quite yet, but this is why GTX 980 isn’t quite twice as fast as GTX 960, for example.
Just increasing the clockspeed, comparatively speaking, means that the entire GPU gets proportionally faster without shifting the resource balance; the CUDA cores are 43% faster, the geometry frontends are 43% faster, the ROPs are 43% faster, etc. The only real limitation in this regard isn’t the GPU itself, but whether you can adequately feed it. And this is where GDDR5X comes into play.








200 Comments
View All Comments
grrrgrrr - Wednesday, July 20, 2016 - link
Solid review! Some nice architecture introductions.euskalzabe - Wednesday, July 20, 2016 - link
The HDR discussion of this review was super interesting, but as always, there's one key piece of information missing: WHEN are we going to see HDR monitors that take advantage of these new GPU abilities?I myself am stuck at 1080p IPS because more resolution doesn't entice me, and there's nothing better than IPS. I'm waiting for HDR to buy my next monitor, but being 5 years old my Dell ST2220T is getting long in the teeth...
ajlueke - Wednesday, July 20, 2016 - link
Thanks for the review Ryan,I think the results are quite interesting, and the games chosen really help show the advantages and limitations of the different architectures. When you compare the GTX 1080 to its price predecessor, the 980 Ti, you are getting an almost universal ~25%-30% increase in performance.
Against rival AMDs R9 Fury X, there is more of a mixed bag. As the resolutions increase the bandwidth provided by the HBM memory on the Fury X really narrows the gap, sometimes trimming the margin to less that 10%,s specifically in games optimized more for DX12 "Hitman, "AotS". But it other games, specifically "Rise of the Tomb Raider" which boasts extremely high res textures, the 4Gb memory size on the Fury X starts to limit its performance in a big way. On average, there is again a ~25%-30% performance increase with much higher game to game variability.
This data lets a little bit of air out of the argument I hear a lot that AMD makes more "future proof" cards. While many Nvidia 900 series users may have to upgrade as more and more games switch to DX12 based programming. AMD Fury users will be in the same boat as those same games come with higher and higher res textures, due to the smaller amount of memory on board.
While Pascal still doesn't show the jump in DX12 versus DX11 that AMD's GPUs enjoy, it does at least show an increase or at least remain at parity.
So what you have is a card that wins in every single game tested, at every resolution over the price predecessors from both companies, all while consuming less power. That is a win pretty much any way you slice it. But there are elements of Nvidia’s strategy and the card I personally find disappointing.
I understand Nvidia wants to keep features specific to the higher margin professional cards, but avoiding HBM2 altogether in the consumer space seems to be a missed opportunity. I am a huge fan of the mini ITX gaming machines. And the Fury Nano, at the $450 price point is a great card. With an NVMe motherboard and NAS storage the need for drive bays in the case is eliminated, the Fury Nano at only 6” leads to some great forward thinking, and tiny designs. I was hoping to see an explosion of cases that cut out the need for supporting 10-11” cards and tons of drive bays if both Nvidia and AMD put out GPUs in the Nano space, but it seems not to be. HBM2 seems destined to remain on professional cards, as Nvidia won’t take the risk of adding it to a consumer Titan or GTX 1080 Ti card and potentially again cannibalize the higher margin professional card market. Now case makers don’t really have the same incentive to build smaller cases if the Fury Nano will still be the only card at that size. It’s just unfortunate that it had to happen because NVidia decided HBM2 was something they could slap on a pro card and sell for thousands extra.
But also what is also disappointing about Pascal stems from the GTX 1080 vs GTX 1070 data Ryan has shown. The GTX 1070 drops off far more than one would expect based off CUDA core numbers as the resolution increases. The GDDR5 memory versus the GDDR5X is probably at fault here, leading me to believe that Pascal can gain even further if the memory bandwidth is increased more, again with HBM2. So not only does the card limit you to the current mini-ITX monstrosities (I’m looking at you bulldog) by avoiding HBM2, it also very likely is costing us performance.
Now for the rank speculation. The data does present some interesting scenarios for the future. With the Fury X able to approach the GTX 1080 at high resolutions, most specifically in DX12 optimized games. It seems extremely likely that the Vega GPU will be able to surpass the GTX 1080, especially if the greatest limitation (4 Gb HBM) is removed with the supposed 8Gb of HBM2 and games move more and more the DX12. I imagine when it launches it will be the 4K card to get, as the Fury X already acquits itself very well there. For me personally, I will have to wait for the Vega Nano to realize my Mini-ITX dreams, unless of course, AMD doesn’t make another Nano edition card and the dream is dead. A possibility I dare not think about.
eddman - Wednesday, July 20, 2016 - link
The gap getting narrower at higher resolutions probably has more to do with chips' designs rather than bandwidth. After all, Fury is the big GCN chip optimized for high resolutions. Even though GP104 does well, it's still the middle Pascal chip.P.S. Please separate the paragraphs. It's a pain, reading your comment.
Eidigean - Wednesday, July 20, 2016 - link
The GTX 1070 is really just a way for Nvidia to sell GP104's that didn't pass all of their tests. Don't expect them to put expensive memory on a card where they're only looking to make their money back. Keeping the card cost down, hoping it sells, is more important to them.If there's a defect anywhere within one of the GPC's, the entire GPC is disabled and the chip is sold at a discount instead of being thrown out. I would not buy a 1070 which is really just a crippled 1080.
I'll be buying a 1080 for my 2560x1600 desktop, and an EVGA 1060 for my Mini-ITX build; which has a limited power supply.
mikael.skytter - Wednesday, July 20, 2016 - link
Thanks Ryan! Much appreciated.chrisp_6@yahoo.com - Wednesday, July 20, 2016 - link
Very good review. One minor comment to the article writers - do a final check on grammer - granted we are technical folks, but it was noticeable especially on the final words page.madwolfa - Wednesday, July 20, 2016 - link
It's "grammar", though. :)Eden-K121D - Thursday, July 21, 2016 - link
Oh the ironychrisp_6@yahoo.com - Thursday, July 21, 2016 - link
oh snap, that is some funny stuff right there