The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
Memory Subsystem: Bandwidth
For this review we completely overhauled our testing of John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with the Intel compiler for linux version 16 or gcc 4.8.4, both 64 bit. The following compiler switches were used on icc:
-fast -openmp -parallel
The results are expressed in GB per second. The following compiler switches were used on gcc:
-O3 –fopenmp –static
Stream allows us to estimate the maximum performance increase that DDR-2400 (Xeon E5 v4) can offer over DDR-2133 (Xeon E5 v3).
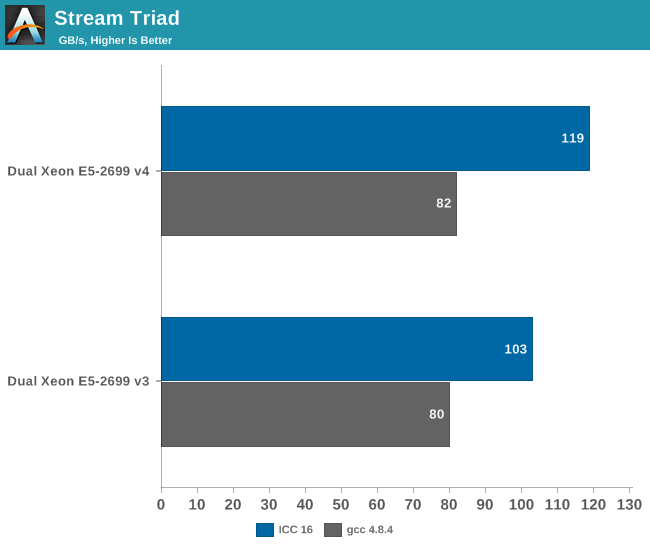
The Xeon E5 v4 with DDR4-2400 delivers about 15% higher performance then the v3 when we compile Stream with icc. To put this into perspective: DDR-4 @ 1600 delivered 80 GB/s.
The difference between DDR-4 2400 and DDR-4 2133 is negligible with gcc.
Memory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
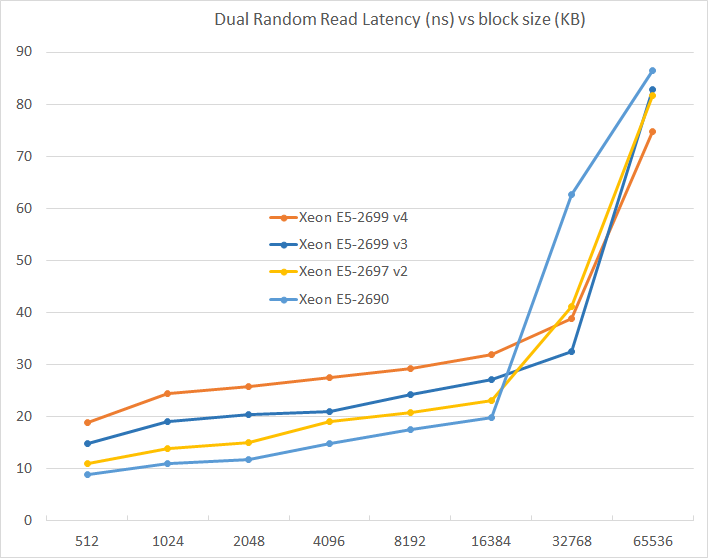
The larger the L3 caches get, the higher the latency. Latency has almost doubled from the Xeon E5 v1 to the Xeon E5 v4 while capacity has almost tripled (55 MB vs 20 MB). Still, this will result in a small performance hit in many non-virtualized applications that do no need such a large L3.








112 Comments
View All Comments
SkipPerk - Friday, April 8, 2016 - link
"Anyone putting Microsoft on bare hardware these days is nuts"This brother is speakin the truth!
warreo - Thursday, March 31, 2016 - link
Can someone clarify this line for me?"The average performance increase versus the Xeon E5-2690 is 3%, and the Broadwell cores get a boost of no less than 19%."
Does that mean IPC increase is 19% for Broadwell, offset by ~16% decline in clockspeed to get to 3% average performance increase? But that doesn't make sense to me as a 3.8ghz (E5-2690) to 3.6ghz (E5-2699 v4) is only 5% decline in max clockspeed?
ShieTar - Thursday, March 31, 2016 - link
I understood it as "the -Ofast setting boosts Broadwell by 19%", so with the -O2 setting it was actually 16% slower than the 2690.And I think the AT-Theory based on the original measurements is that the 3.6GHz boost are not even held for a significant amount of time, so that Broadwell in reality comes with an even worse decline in clock speed.
warreo - Thursday, March 31, 2016 - link
Your interpretation makes much more sense than mine, but still doesn't quite add up. The improvement from using -Ofast vs. -O2 is 13% on average, and the lowest improvement is 4% on the xalancbmk, well below the "no less than 19%" quoted by Johan.Perhaps the rest of the disparity is normalizing for sustained clock speeds as you suspect? Johan is that correct?
Ryan Smith - Thursday, March 31, 2016 - link
I've reworded that passage to make it clearer. But ShieTar's interpretation was basically correct."Switching from -O2 to -Ofast improves Broadwell-EP's absolute performance by over 19%. Meanwhile the relative performance advantage versus the Xeon E5-2690 averages 3%. "
JohanAnandtech - Thursday, March 31, 2016 - link
That means that the -ofast has much more effect on the Broadwell. I mean by that that -ofast is 19% faster than -o2 on Broadwell, while it is 3% faster on Sandy Bridge. I assume that the older the architecture, the better the compiler is able to optimize it without special tricks.warreo - Friday, April 1, 2016 - link
Thanks for the clarification. Loved the review, great work Johan!Pinn - Thursday, March 31, 2016 - link
I'm still happy I went with the 6 core x99 over the 8 core. Massive core count is nice to see available, but I don't see the true value. Looks like you have to do the same rough math to see if the clock speed reduction is worth the core count.Oxford Guy - Tuesday, April 5, 2016 - link
Why would there be "true value" for six and not for eight?Pinn - Wednesday, April 6, 2016 - link
Single threaded workloads.