The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
TSX
TSX or Transactional Synchronization Extensions is Intel's cache-based transactional memory system. Intel launched TSX with Haswell, but a bug threw a spanner in the works. Broadwell in turn got it right. The chicken is finally there, now it's time to enjoy the eggs.
Faster Virtualization
Virtualization overhead is (for most people) a thing of the past. The performance overhead with bare metal hypervisors (ESXi, Hyper-V, Xen, KVM..) is less than a few percent. There is one exception however: applications where I/O dominates. And of course, the packet switching telco applications are the prime examples. Intel, VMware and the server vendors really want to convert the telcos from their Firewall/Router/VPN "black boxes" to virtual ones using Software Defined Networking (SDN) infrastructure. To that end, Intel has continued to work on reducing the virtualization performance overhead. Virtualization overhead can be described as the number of VM exits (VM stops and hypervisor takes over) times the VM exit latency. In IO intensive application, VM exits happen frequently, which in turn leads to hard to predict and high IO latency, exactly what the telco people hate.
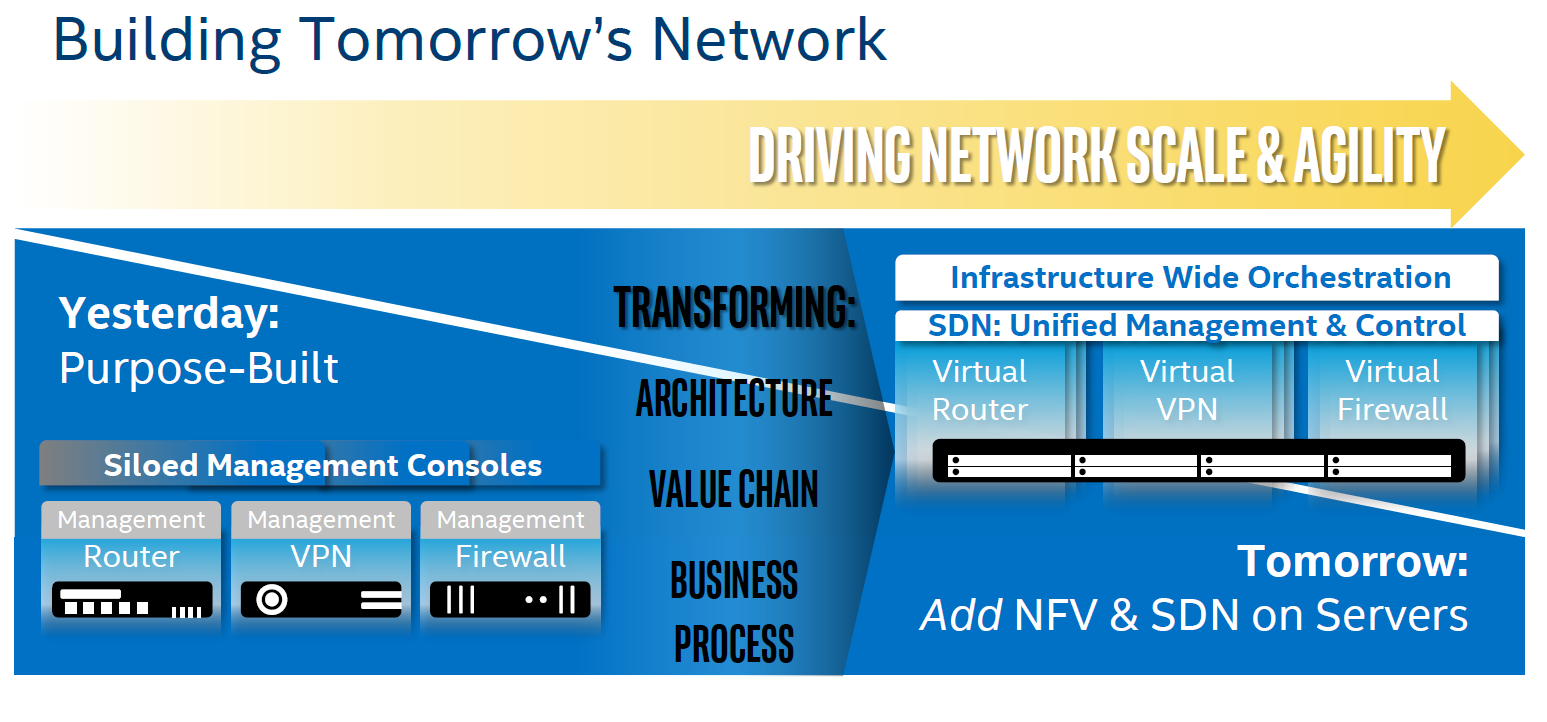
Intel wants to conquer the telco's datacenter by turning it into a SDN
So Intel worked on both factors. So Broadwell-DP VM exit latency is once again reduced from 500 cycles to 400.
It seems that the "ticks" also get a VM exit reduction. This slide of the Ivy Bride EP presentation gives you a very good overview of the VM exits in a network intensive application; in this case a networkd bandwidth benchmark application.
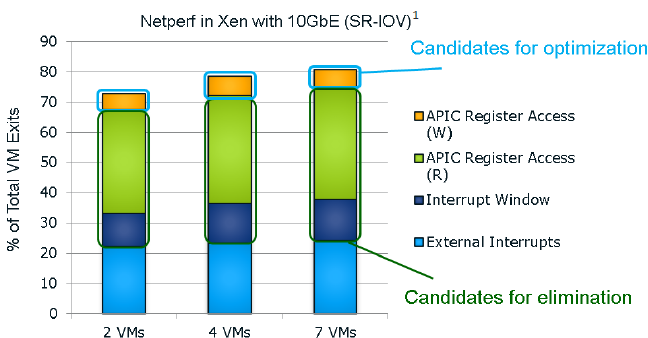
I quote from our Ivy Bridge-EP review:
The Ivy Bridge core is now capable of eliminating the VMexits due to "internal" interrupts, interrupts that originate from within the guest OS (for example inter-vCPU interrupts and timers). The virtual processor will then need to access the APIC registers, which will require a VMexit. Apparently, the current Virtual Machine Monitors do not handle this very well, as they need somewhere between 2000 to 7000 cycles per exit, which is high compared to other exits.
The solution is the Advanced Programmable Interrupt Controller virtualization (APICv). The new Xeon has microcode that can be read by the Guest OS without any VMexit, though writing still causes an exit. Some tests inside the Intel labs show up to 10% better performance.
In summary, Intel eliminated the green and dark blue components of the VM exit overhead with APICv. Broadwell now takes on the VM exits due to the external interrupts.
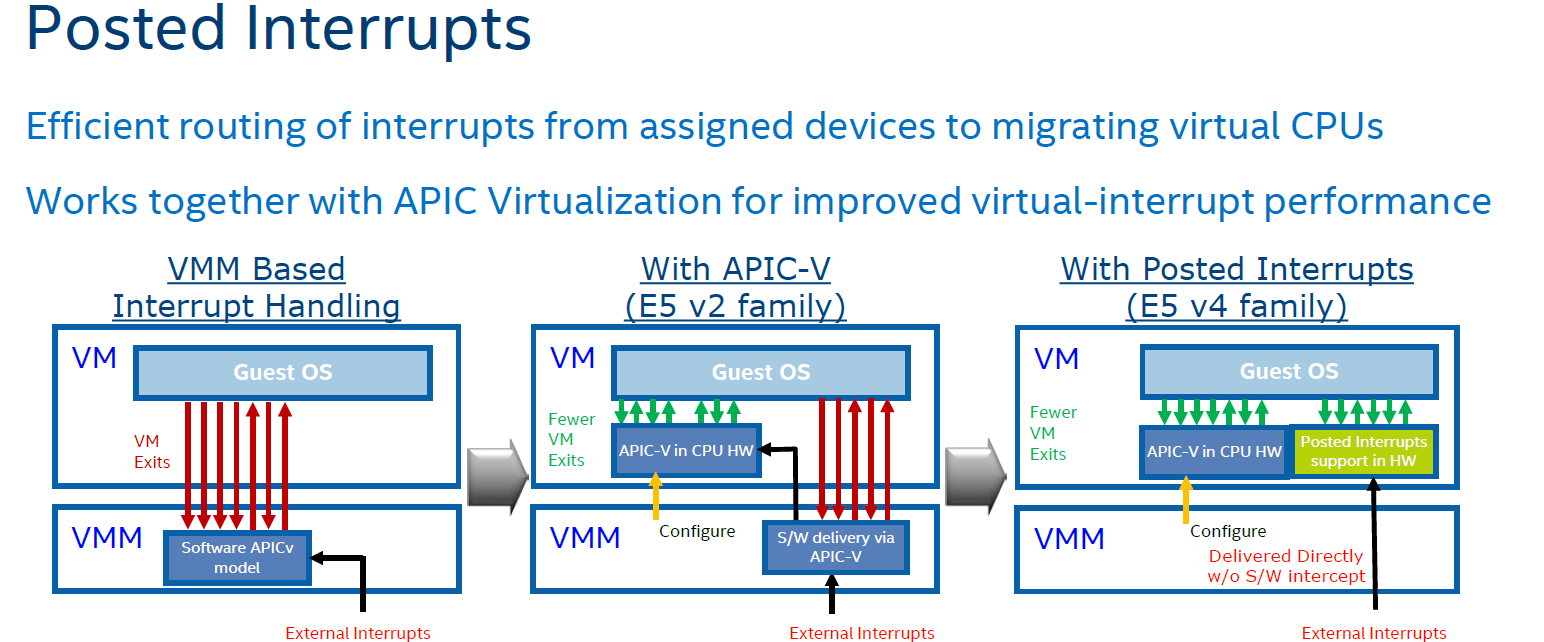
The technology on Broadwell-EP to do this is called posted interrupt. Essentially, posted interrupts enables direct interrupt delivery to the virtual machine without incurring a VM exit, courtesy of an interrupt remapping table. It is very similar to VT-D, which allowed DMA remapping thanks to the physical to virtual memory mapping table. Telco applications - among others - are very latency sensitive. Intel's Edwin Verplancke gave us one such example: before posted interrupts, a telco application had a latency varying from 4 to 47 (!) µsec, depending on the load. Posted interrupts made this a lot less variable, and latency varied from 2.4 to 5.2 µsecs.
As far as we are aware, KVM and Xen seem to have already implemented support for posted interrupts.








112 Comments
View All Comments
SkipPerk - Friday, April 8, 2016 - link
"Anyone putting Microsoft on bare hardware these days is nuts"This brother is speakin the truth!
warreo - Thursday, March 31, 2016 - link
Can someone clarify this line for me?"The average performance increase versus the Xeon E5-2690 is 3%, and the Broadwell cores get a boost of no less than 19%."
Does that mean IPC increase is 19% for Broadwell, offset by ~16% decline in clockspeed to get to 3% average performance increase? But that doesn't make sense to me as a 3.8ghz (E5-2690) to 3.6ghz (E5-2699 v4) is only 5% decline in max clockspeed?
ShieTar - Thursday, March 31, 2016 - link
I understood it as "the -Ofast setting boosts Broadwell by 19%", so with the -O2 setting it was actually 16% slower than the 2690.And I think the AT-Theory based on the original measurements is that the 3.6GHz boost are not even held for a significant amount of time, so that Broadwell in reality comes with an even worse decline in clock speed.
warreo - Thursday, March 31, 2016 - link
Your interpretation makes much more sense than mine, but still doesn't quite add up. The improvement from using -Ofast vs. -O2 is 13% on average, and the lowest improvement is 4% on the xalancbmk, well below the "no less than 19%" quoted by Johan.Perhaps the rest of the disparity is normalizing for sustained clock speeds as you suspect? Johan is that correct?
Ryan Smith - Thursday, March 31, 2016 - link
I've reworded that passage to make it clearer. But ShieTar's interpretation was basically correct."Switching from -O2 to -Ofast improves Broadwell-EP's absolute performance by over 19%. Meanwhile the relative performance advantage versus the Xeon E5-2690 averages 3%. "
JohanAnandtech - Thursday, March 31, 2016 - link
That means that the -ofast has much more effect on the Broadwell. I mean by that that -ofast is 19% faster than -o2 on Broadwell, while it is 3% faster on Sandy Bridge. I assume that the older the architecture, the better the compiler is able to optimize it without special tricks.warreo - Friday, April 1, 2016 - link
Thanks for the clarification. Loved the review, great work Johan!Pinn - Thursday, March 31, 2016 - link
I'm still happy I went with the 6 core x99 over the 8 core. Massive core count is nice to see available, but I don't see the true value. Looks like you have to do the same rough math to see if the clock speed reduction is worth the core count.Oxford Guy - Tuesday, April 5, 2016 - link
Why would there be "true value" for six and not for eight?Pinn - Wednesday, April 6, 2016 - link
Single threaded workloads.